hashtable(散列表)结构,在插入、删除、搜索等操作也具有”常数平均时间”的表现。
hashtable概述
举个例子,假设所有元素都是16bits,范围0~65535,简单的使用一个array即可以满足常数时间的插入、删除、搜索。
创建数组array A,拥有65536个元素,索引号码0~65535,初始值全部为0
当插入元素i就执行A[i]++,删除元素就执行A[i]–,如果搜索元素i就检查A[i]是否为0
下图为插入了元素:5,8, 3, 8, 58, 65535, 65534 数组内容。

但是上面的解法存在两个问题:
如果元素是32-bits而非16-bits那么所需的array A的大小就是232=4GB,这么大就不切实际了。
如果元素是字符串而非整数,就无法拿来做array的索引了。
第二个问题不难解决:可以将字符编码,每个字符以7-bits的数值表示(也就是ASCII码),如字符串”jjhou”表现为:
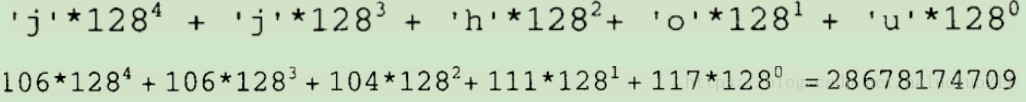
数值太大了,这有回到了问题一。
那么,如何避免一个大的慌缪的array呢?办法之一就是使用某种映射函数(hash function散列函数),将任意的元素映射到TableSize范围之内。
二、常用的哈希函数
1. 直接寻址法
取关键字或者关键字的某个线性函数值作为哈希地址,即H(Key)=Key或者H(Key)=a*Key+b(a,b为整数),这种散列函数也叫做自身函数.如果H(Key)的哈希地址上已经有值了,那么就往下一个位置找,知道找到H(Key)的位置没有值了就把元素放进去.
数字分析法
分析一组数据,比如一组员工的出生年月,这时我们发现出生年月的前几位数字一般都相同,因此,出现冲突的概率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果利用后面的几位数字来构造散列地址,则冲突的几率则会明显降低.因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址.平方取中法
取关键字平方后的中间几位作为散列地址.一个数的平方值的中间几位和数的每一位都有关。因此,有平方取中法得到的哈希地址同关键字的每一位都有关,是的哈希地址具有较好的分散性。折叠法
折叠法即将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和…….除留余数法
取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址.
使用hash function会带来一个问题:不同元素可能会被映射到相同的位置。这便是所谓的“碰撞(collision)”问题。解决的办法有很多种,包括线性探测(linear probing),二次探测(quadratic probing),开链(seperate chaining)…等做法。
哈希冲突的处理方法
- 开放定址法——线性探测
线性探测法的地址增量di = 1, 2, … , m-1,其中,i为探测次数。该方法一次探测下一个地址,知道有空的地址后插入,若整个空间都找不到空余的地址,则产生溢出。
线性探测容易产生“聚集”现象。当表中的第i、i+1、i+2的位置上已经存储某些关键字,则下一次哈希地址为i、i+1、i+2、i+3的关键字都将企图填入到i+3的位置上,这种多个哈希地址不同的关键字争夺同一个后继哈希地址的现象称为“聚集”。聚集对查找效率有很大影响。
- 开放地址法——二次探测
二次探测法的地址增量序列为 di = 12, -12, 22, -22,… , q2, -q2 (q <= m/2)。二次探测能有效避免“聚集”现象,但是不能够探测到哈希表上所有的存储单元,但是至少能够探测到一半。
- 链地址法
链地址法也成为拉链法。其基本思路是:将所有具有相同哈希地址的而不同关键字的数据元素连接到同一个单链表中。如果选定的哈希表长度为m,则可将哈希表定义为一个有m个头指针组成的指针数组T[0..m-1],凡是哈希地址为i的数据元素,均以节点的形式插入到T[i]为头指针的单链表中。并且新的元素插入到链表的前端,这不仅因为方便,还因为经常发生这样的事实:新近插入的元素最优可能不久又被访问。
链地址法特点:
拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。
以上参考: https://blog.csdn.net/u011080472/article/details/51177412
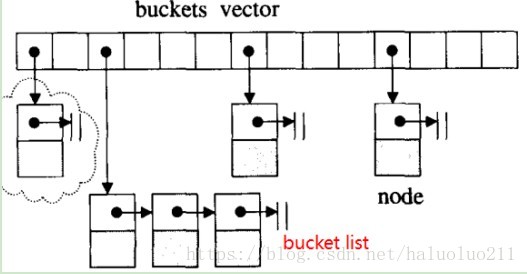
hashtable的桶子(buckets)与节点(nodes)
SGI的hash table正是以开链(seperate chaining)实现。
节点定义如下:
template<typename T>
struct __hashtable_node{
T val;
__hashtable_node* next;
};注意:bucket所维护的linked list ,并不是采用STL的list,而是自行维护。
hashtable的核心成员定义如下:
template<typename Key, typename Value, typename HashFun>
class hashtable{
public:
typedef size_t size_type;
typedef HashFun hasher;
typedef Value value_type;
typedef Key key_type;
public:
typedef __hashtable_node<value_type> node;
// 分配桶节点,分配器
typedef allocator<node> nodeAllocator;
// 成员就是vector维护的node*数组
std::vector<node*> buckets;
size_type num_elements;
};iterator
下面给出的iterator和侯捷先生的书,有不同,我认为迭代器关联hashtable是没有必要的。
template <typename Value>
struct __hashtable_iterator{
typedef Value value_type;
typedef Value& reference;
typedef __hashtable_node<value_type> node;
typedef node* pointer;
typedef __hashtable_iterator<value_type> self;
// 成员
node* cur;
reference operator*()const {return cur->val;}
pointer operator->()const{return &(operator*());}
// 返回的是引用
self& operator++(){
cur = cur->next;
return *this;
}
// 返回的非引用
self operator++(int){
self tmp = *this;
cur = cur->next;
return tmp;
}
};hashtable构造/插入函数
在看构造函数,之前先看下,buckets表格大小的计算问题。
虽然开链法并不要求表的大小(buckets)必须也质数,但是SGI STL仍然以质数来设计表格大小。 将28个质数(逐渐呈现大约两倍的关系)计算好,以备随时访问。同时提供一个函数,用来查询在这28个质数之中,”最接近某数,并大于某数” 的质数。
static const int __stl_num_primes = 28;
static const unsigned long __stl__prime_arr[__stl_num_primes] =
{
5, 53, 97, 193, 389,
769, 1543, 3079, 6151, 12289,
24593, 49157, 98317, 196613, 393241,
786433, 1572869, 3145739, 6291469, 12582917,
25165843, 50331653, 100663319, 201326611, 402653189,
805306457, 1610612741, 3221225473, 4294967291
};// 找出上述28个质数之中,最接近并大于 n 的那个质数
inline unsigned long __stl_next_prime(unsigned long n){
const unsigned long* first = __stl__prime_arr;
const unsigned long* last = __stl__prime_arr + __stl_num_primes;
const unsigned long* pos = std::lower_bound(first, last, n);
return pos == last ? *(last - 1): *pos;
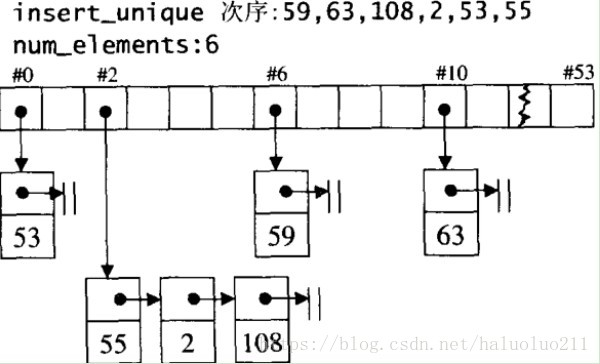
}假设现在,创建含有50个bucket节点的hashtable:
hashtable<int, int, std::hash<int>> hash_table(50);hashtable会返回53个节点(50的下一个质数是53)的bucket 数组:

插入6个元素后,hash table的状态如下:
构造函数如下:
template<typename Key, typename Value, typename HashFun>
hashtable<Key, Value, HashFun>::hashtable(size_type n){
initialize_buckets(n);
}
template<typename Key, typename Value, typename HashFun>
void hashtable<Key, Value, HashFun>::initialize_buckets(size_type n) {
// 例如传入 50 则返回 53
const size_type n_buckets = next_size(n);
buckets.reserve(n_buckets);
buckets.insert(buckets.end(), n_buckets, nullptr);
num_elements = 0;
}下面重点是元素的插入,类型与红黑树有unique插入,以及equal插入:
template<typename Key, typename Value, typename HashFun>
std::pair<iterator, bool> hashtable<Key, Value, HashFun>::insert_unique(const value_type& obj){
// 判断是否需要重建表格,入需要则扩充
resize(num_elements + 1);
insert_unique_noresize(obj);
}
template<typename Key, typename Value, typename HashFun>
void hashtable<Key, Value, HashFun>::resize(const size_type n){
// 根据 n 决定是否重新建立表格
// 先省略......
}可以插入重复的数据:
std::pair<iterator, bool> insert_equal(const value_type& obj);// 根据 obj 定位到哪个buckets数组
size_type bkt_num(const value_type& obj, size_t n){
return btk_num_key(get_key(obj), n);
}
key_type& get_key(const value_type& obj){
// 这里面省略了从 obj 获取 key
return key_type();
}
size_type btk_num_key(const key_type& key, size_type n){
return std::hash(key) % n;
}
template<typename Key, typename Value, typename HashFun>
void hashtable<Key, Value, HashFun>::clear(){
for (size_type i = 0; i < buckets.size(); ++i) {
node* cur = buckets[i];
// 情况每个bucket的list
while (cur){
node* next = cur->next;
dealloc_dtor_node(cur);
cur = next;
}
buckets[i] = 0;
}
num_elements = 0; // 令总的个数为 0
// 注意, buckets vector并未释放掉空间,人保留原有的
}find查询函数:
template<typename Key, typename Value, typename HashFun>
iterator hashtable<Key, Value, HashFun>::find(const key_type& key){
// 根据 obj 定位到哪个buckets数组
size_type idx = bkt_num(key, num_elements);
// 遍历查找bucket中的list
node* it = buckets[idx];
while (it++){
if (get_key(it->val) != key)
break;
}
return iterator(it);
}链表中的节点的配置、构造、与析构。
// 产生(配置并构造)一个节点, 首先分配内存, 然后进行构造
node* alloc_ctor_node(const value_type& value){
node* tmp = nodeAllocator::allocate(); // 配置空间
construct(tmp, value); // 构造节点
return tmp;
}
// 析构结点元素, 并释放内存
void dealloc_dtor_node(node* p){
destroy(&p->val);
nodeAllocator::destroy(p);
}