1.将一个日志文件上传到hdfs上
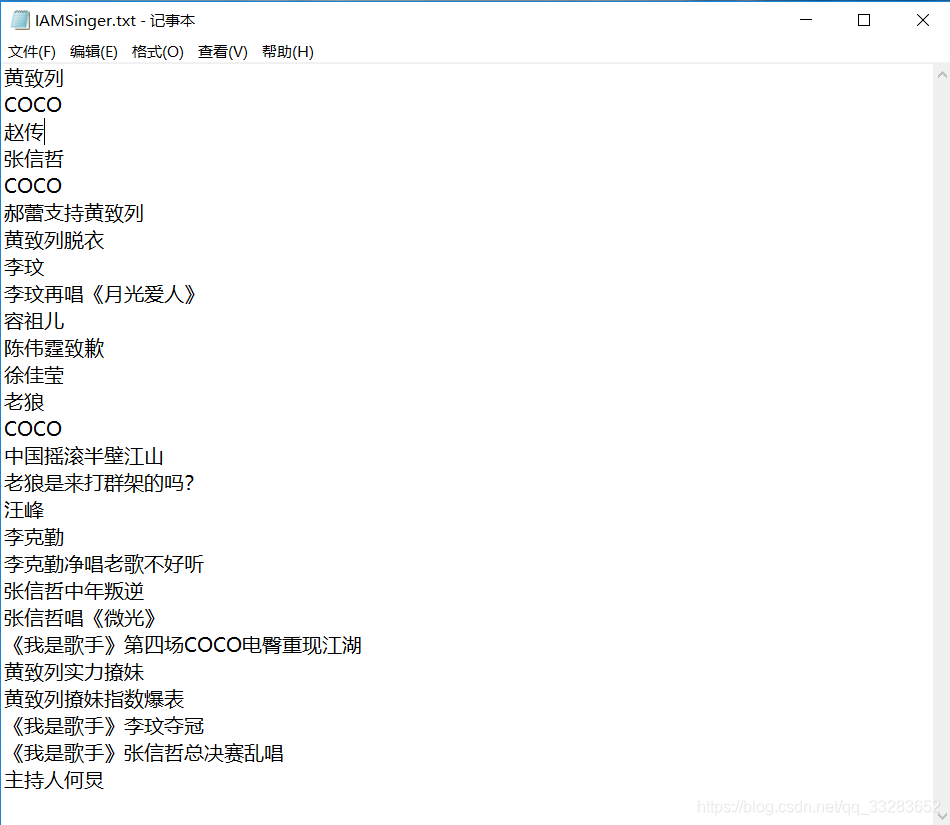

2. 编写mapReduce代码
2.1新建一个maven项目,添加依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>2.2编写HotSearch类

import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* mapReduce功能演示:《我是歌手》热搜榜
*
* @author lrn
* @createTime : 2018/11/30 19:03
*/
public class HotSearch {
public static class HotSearchMap extends Mapper<Object, Text, Text, IntWritable> {
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 文中的一行数据
String currentLine = value.toString();
// 如果当前行中出现歌手的名字,则对应歌手的统计数量+1
if (currentLine.contains("黄致列")) {
context.write(new Text("黄致列"), new IntWritable(1));
} else if (currentLine.contains("李玟") || currentLine.contains("COCO")) {
context.write(new Text("李玟"), new IntWritable(1));
} else if (currentLine.contains("张信哲")) {
context.write(new Text("张信哲"), new IntWritable(1));
} else if (currentLine.contains("赵传")) {
context.write(new Text("赵传"), new IntWritable(1));
} else if (currentLine.contains("老狼")) {
context.write(new Text("老狼"), new IntWritable(1));
}
}
}
public static class HotSearchReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int count = 0;
// 对map方法中输出的统计数据进行汇总
for (IntWritable intWritable : values) {
count += intWritable.get();
}
// 输出该reduce的汇总数据
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) throws Exception {
// 取得一个任务对象
Job job = Job.getInstance();
job.setJarByClass(HotSearch.class);
job.setMapperClass(HotSearchMap.class);
job.setReducerClass(HotSearchReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置任务的输入文件或路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 设置任务的输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 启动任务
job.waitForCompletion(true);
}
}
2.3打包
mvn clean,mvn install ,mvn package打成jar包
3.hdfs运行
3.1将jar包传到Linux上
3.2启动hdfs
在sbin目录下执行
./start-dfs.sh3.3启动yarn
./start-yarn.sh
3.4运行mapReduce
./hadoop jar /tmp/mapReduce-1.0-SNAPSHOT.jar HotSearch /input/IAMSinger.txt /output2命令解读:./hadoop jar +jar包在Linux的路径 +jar包main方法所在类(路径)+hdfs上的待分析文件路径+hdfs分析结果路径
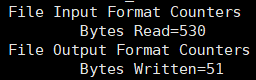
File Output Format对应的Bytes若为0,则表示无输出内容
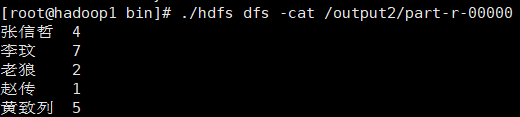
3.5查看分析结果
./hdfs dfs -cat /output2/part-r-00000