Hadoop(三)–MapReduce
mr
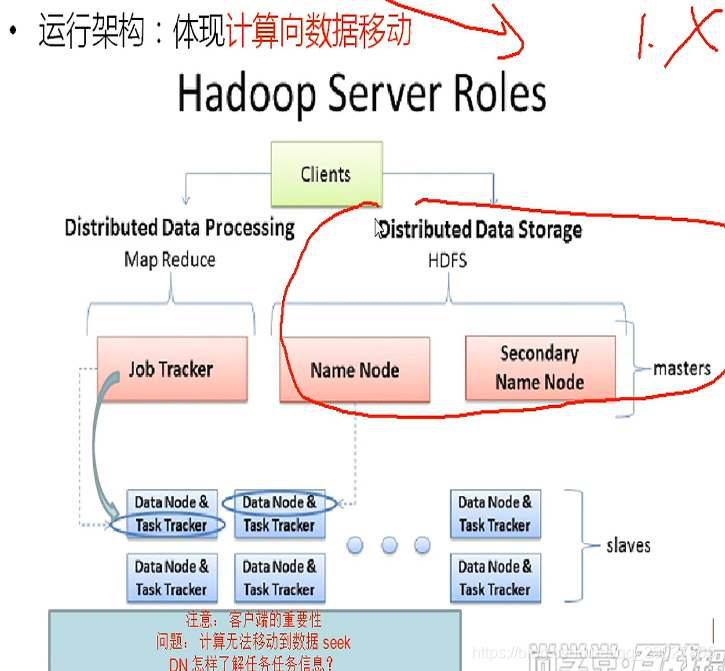
mr的框架:
宏观作业角度,有maptask和reduceTask,这两者有宏观的依赖关系。先有map,才有reduce。没有做中间级映射,产生规范的数据集,怎么来进行reduce。
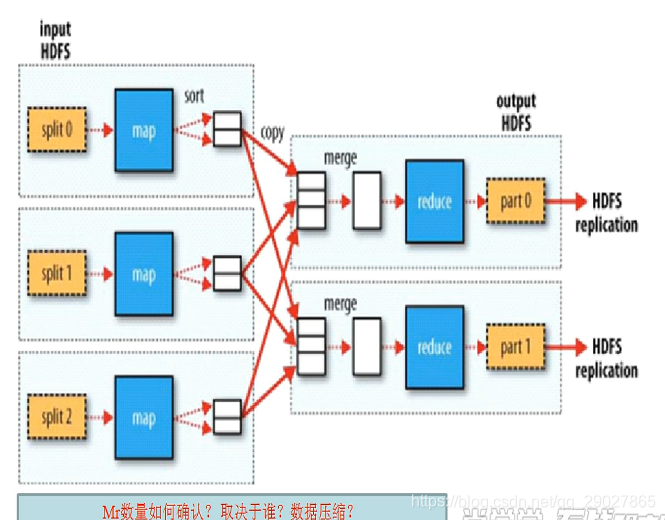
map:就是maptask的计算框架。那么map的数量该怎么确定呢?
有多少快就有多少map,每一个map都跑到block块上。实际上,map和split对象在一一对应。当前作业需要多少个map计算框架,和split得数量有关,并没有直接和块发生关系。
开始需要把文件切分为不同的块,散列在不同的节点之上。接下来要做的就是把map的计算框架移动到块所在的服务器之上。块的数量要小于map的数量。map和split对应,之前得块是真正被切割开的物理块,后面的split可以说是片,前面是物理块,后面是逻辑上的片–并没有真实切割,而是在逻辑上规划了下这块区域的数据量的大小。这块区域数据量由块来定。
为什么不直接切割成10个块,由10个程序去跑?
假定一个块的数据量很大,一个块需要算一年。那为甚么会造成时间长–块太大。灵活的提出“片”的概念,在块的基础上,切分为若干个逻辑片。
一个drop作业需要多少个map,首先需要知道split片的数量,而片的数量又和块的数量和位置有关。基于这已有的事实,才能知道split的数量,进而反推出map。
map完成了K-V的中间级映射。假如:统计中国各个主要城市的平均房价–
意味着要算平均值,map需要做的就是:k-v中间级的映射。k是城市名,v是房价。reduce该怎么来算:key相同的合并为一组,拿到总量算平均值。实际上是一个分组的概念,group-by。
问题:1. 相同的key要做一组进行计算;2. reduce需要多少个?
reduce和什么有关:一个key对应一个reduce(比较常规的思路);把不同的组交给一个reduce完成,一个reduce可以完成多组key。MR框架死板的地方在于,同一组key交给一个reduce来发,这是数据的分发策略。一个reduce可以来处理多组key。但是相同的一组key只能交给一个reduce来完成。
reduce和业务数据有关。
MR框架分为4个阶段:切片;拿到逻辑上的切片数据后,可以生成map任务开始计算;shuffle阶段:打乱顺序;reduce过程;
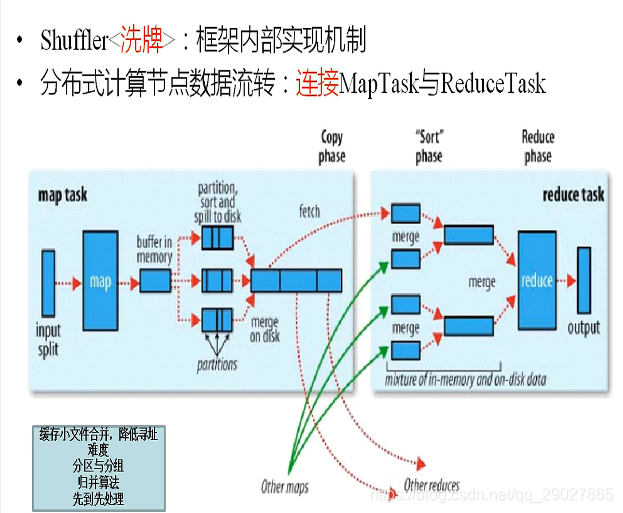
shuffle的过程:讲述的是出map的数据,到出reduce中间,如何完成一个排序洗牌的工作。
过程:先split片,一个片大小就是一个块的大小。在缓冲区中按照分区进行排序,有几个reduce就有几个分区。排好序后代表着每一个快都代表着一个城市。
把有些工作在拉取工作之前完成,在缓冲区中做了很多事情:
- 先按照分区进行排序;分区指的是–有几个reduce,就有几个分区;
- 分区内部的数据要归并排成一组;
内存端除了完成排序外,还有combiner,数据压缩。
每一个map在生成键值对k-v时,还要生成一个partition分区。partition这个分区代表着记录归属于谁
。第一步把它按照分区进行排序,分区号和reduce是对应的。每个reduce都知道自己该拉取哪个分区的数据过去。第二次排序,在分区内部也要进行排序,原因是一个reduce可能不止处理一组数据,可能要处理多组数据。拿到的数据是组的数据;reduce端拿到的数据是规整的数据,之前进行了二次排序。
把128M数据溢写,溢写成小文件,当整批数据处理完后,会生成一堆小文件。这些小文件要进行排序。谁先完成谁归并,最终得到一个排序完整的文件交给reduce。
总结mapreduce计算流程:
- 先是split切片,切片的原则是:默认大小和块大小一致;这个片数量决定了map的数量;

- 进行中间级kv映射,产生了kv,同时产生kv所属的分区。带着这行参数的记录向缓冲区中去写,写满了缓冲区,溢写成小文件;
- 在缓冲区内部完成了分区与分区内部的排序(2次);
- 小文件完成后,再通过快排或归并完成一个整体的归并算法,形成一个有序的大文件;
- 因为是多个map来并行,这些文件最终都会在shuffle阶段交给reduce, 但是reduce不能来一个文件处理一个。故这些文件还需要做归并,完整生成1-n个有序的文件。最后套一个归并算法,交给reduce。只要保证reduce拉取得数据是完全有序得即可。
单词统计
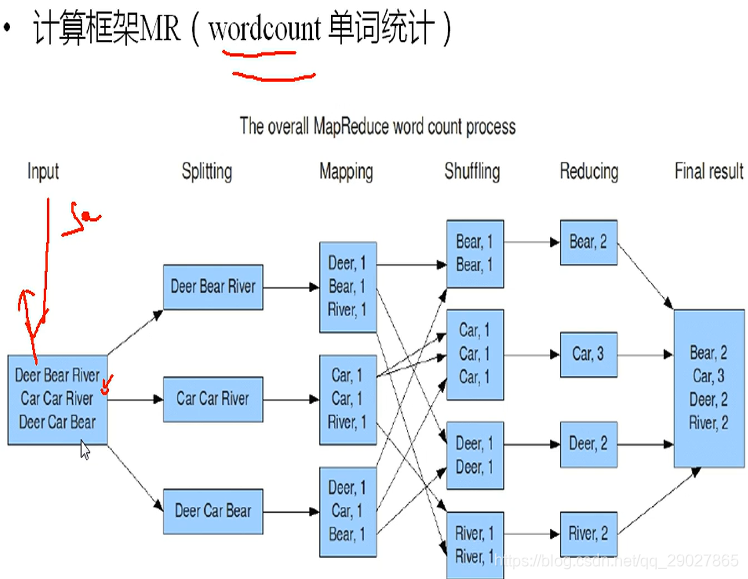
四个阶段:切割,中间级映射,数据洗牌,数据迭代。
- 切割:按行来进行切割,每次读取一行。因为要在map端做kv得映射,最好的形式就是拿一行数据。在split中每次交出一行;
- 完成k-v中间级映射,形成kv来生成分区号。依据reduce得数量来生成分区号,基于hash得好处是,相同得k放在了一个分区中;
- shffle:所有相同的词放在一个中;
- 这些词在reduce中进行累加即可,最后进行输出;
框架

K-相同数据特征得抽取,Value值和业务需求有关。全量:在reduce端既可以处理一组,也可以处理多组。reduce调用得原则是:只要属于同一个组,就会调用一次。假设k和reduce不一样了,reduce就会自动退出了。reduce拿到得数据已经是规整了,比map做的工作少。
k-v属于自定义数据类型。所有基本数据类型都不支持,kv必须是Java类得类型,或者是自定义得类。或者说必须是封装类。使用java得可变参数来进行解决。传递过程中需要序列化和反序列化,因此传递的kv需要实现序列化的接口。除了序列化之外,还得实现一个接口,comparable比较器,比较器得目的是为了进行排序。
Hadoop1.x版本得mr