引言
MapReduce是Hadoop生态中的一款分布式计算框架,采用“分而治之”的核心思想,先将一个大型任务拆分成若干个简单的子任务,然后将每个子任务交给一个独立的节点去处理,当所有节点的子任务都处理完毕后,再汇总所有子任务的处理结果,从而得到最终的结果。
1.经典案例分析:WordCount
1.1 Map阶段:TokenizerMapper类
源码如下:
import org.apache.hadoop.mapreduce.Mapper;
public static class TokenizerMapper extends Mapper<Object,Text,Text,IntWriter>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)throws IOException,InterrupedExcetion{
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextTOken());
context.write(word, one);
}
}
}
Map阶段源码分析:
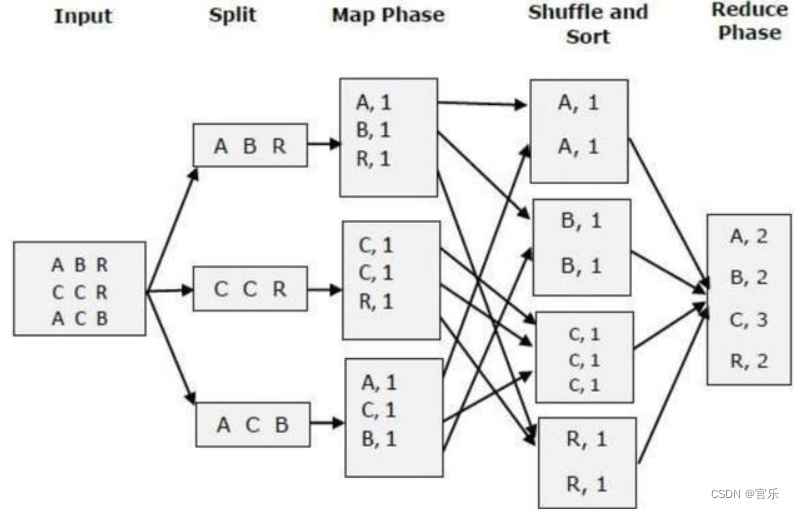
首先输入数据被提交到MapReduce流程后,MapReduce会先将输入数据进行拆分(split),再提交给Map阶段的map()方法,示意图如下:
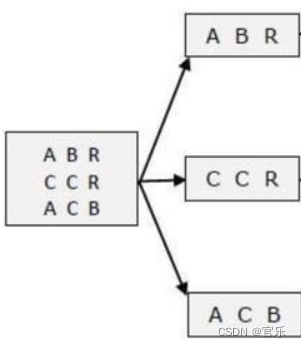
①map()方法默认以行为单位进行读取;
②每读取一行数据后,通过StringTokenizer构造方法将该行数据以空白字符(空格、制表符等)为分隔符进行拆分;
③遍历拆分后的单词,同时将每个单词的输出value置为1;
④遍历结束后,map阶段的结果如下:
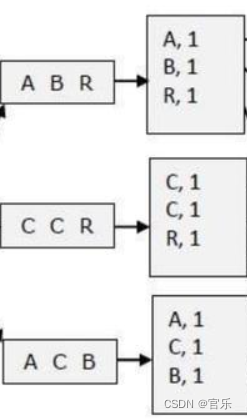
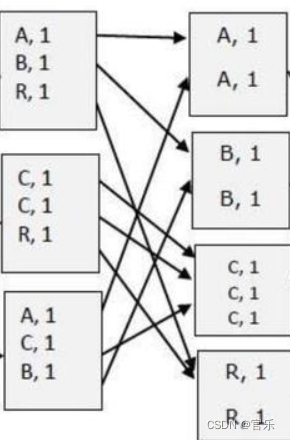
Map阶段后会经过一个名为shuffle阶段,在其中进行排序和分区操作,其处理结果为“key = 单词, value = 单词的value数组”,示意图如下:
1.2 Reduce阶段:IntSumReduce类
源码如下:
import org.apache.hadoop.mapreduce.Reducer;
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key,Iterable<IntWritable> value,Context context) throws IOException,InterruptedException{
int sum = 0;
for(IntWritable val:values){
sum += val.get();
}
result.set(sum);
context.write(key,result);
}
}
Reduce阶段源码分析:
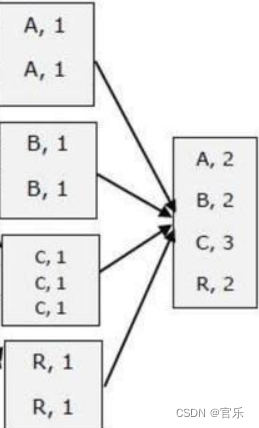
①Shuffle阶段的产物就是Reduce阶段的输入数据;
②对每个单词的出现次数进行相加;
③reduce阶段的处理结果示意图如下:
1.3 Driver阶段:main(函数)
源码如下:
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if otherArgs.length < 2){
System.err.println("Usage:wordcount <in>[<in>...]<out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");//①获取配置信息,获取job对象实例
job.setJarByClass(WordCount.class);//②指定本程序的jar包所在的本地路径
job.setMapperClass(TokenizerMapper.class);//③关联Mapper/Reducer业务类
job.setCombinerClass(IntSumReducer.calss);
job.setReducerClass(IntSumReducer.class);//③关联Mapper/Reducer业务类
job.setOutputKeyClass(Text.class);//④指定Mapper输出数据的kv类型
job.setOutputValueClass(IntWritable.class);//⑤指定最终输出数据的kv类型
for(int i=0; i < otherArgs.length-1; ++i){
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));//⑥指定job的输入原始文件所在目录
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length-1]));//⑦指定job的输出结果所在目录
System.exit(job.waitForCompletion(true)?0:1);//⑧提交作业
}
Driver阶段源码分析:
①获取配置信息,获取job对象实例;
②指定本程序的jar包所在的本地路径;
③关联Mapper/Reducer业务类;
④指定Mapper输出数据的kv类型;
⑤指定最终输出数据的kv类型;
⑥指定job的输入原始文件所在目录;
⑦指定job的输出结果所在目录;
⑧提交作业;
完整流程如下:
2.MapReduce的作业执行流程
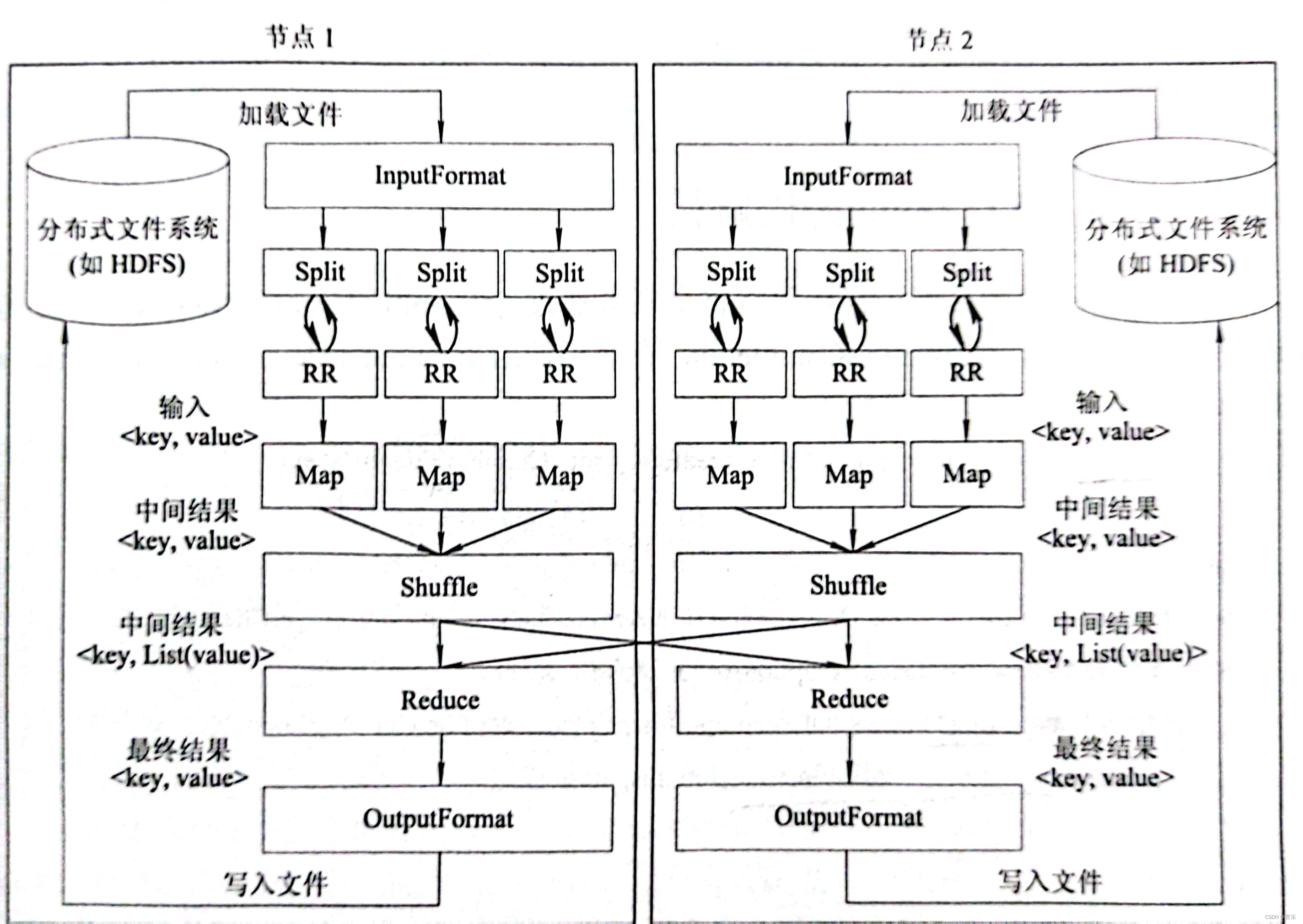
2.1 InputFormat
首先对数据做预处理,然后将输入文件切分为逻辑上的多个InputSplit;由于InputSplit是逻辑切分而非物理切分,所以需要通过RecordReader根据InputSplit中的信息来处理InputSplit中的具体记录。如加载数据并转换为适合Map任务读取的键值对<key, value>,输入给Map任务;
2.2 Map
根据用户自定义的映射规则,输出一系列的<key, value>作为中间结果。
2.3 Shuffle
对Map的输出进行一定的排序、分区、合并、归并等操作,得到<key, List>形式的中间结果,再交给Reduce处理。
2.4 Reduce
以<key, List>形式作为输入,执行用户自定义的逻辑,输出<key, value>形式的结果给OutputFormat。
2.5 OutputFormat
验证输出目录是否存在以及输出结果类型是否符合配置文件中的配置类型。
3.序列化与MapReduce的数据类型
3.1 序列化与反序列化
由于MapReduce是集群运算,会在执行期间利用网络进行数据传输,所以需将数据序列化以在网络中传输。
①序列化:把内存中的对象转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输;
②反序列化:将收到的字节序列(或其他数据传输协议)或者是磁盘的持久化数据转换成内存中的对象;
MapReduce中提供的序列化接口为Writable接口,其中的write()方法用于将数据进行序列化操作,readFields()方法用于将数据进行反序列化操作。
3.2 MapReduce中常见数据类型
MapReduce专门设计了一套数据类型匹配上述序列化机制,如下:
| 数据类型 | 说明 |
|---|---|
| IntWritable | 整型 |
| LongWritable | 长整型 |
| FloatWritable | 单精度浮点型 |
| DoubleWritable | 双精度浮点型 |
| ByteWritable | 字节型 |
| BooleanWritable | 布尔型 |
| Text | UTF-8格式的文本对象,字符串 |
| NullWritable | 空对象 |
4.Shuffle的机制
首先,Shuffle会持续接收Map阶段发来的数据,并将数据写入到一个“环形缓冲区”。当缓冲区被填满后就会将被覆盖掉的部分存放到“溢出文件”中。
其次,Shuffle会对溢出文件中的数据进行排序(Sort),然后再将排序后的数据进行分区(Partition)。
同样,Shuffle会生成很多个排序且分区后的溢出文件,最后会将所有溢出文件中相同分区号的内容进行合并(Combine),形成Map阶段最终的第0区内容、第1区内容…
与此同时,其他Map阶段也会生成当前Map最终的第0区内容、第1区内容…
然后Shuffle会对所有Map阶段相同分区号的内容再次合并,从而形成最终的第0区内容、第1区内容…
5.MapReduce调优
5.1 输入数据中存在大量的小文件
在处理之前将小文件合并,然后将合并后的文件进行处理。
5.2 减少MapReduce各阶段数据传输的次数
可以先将各个Map节点的数据在本地处理,然后再将各个Map节点本地处理的结果经网络传输到Reduce进行汇总。
5.3 数据压缩
使用org.apache.hadoop.io.compreaa.DefaultCodec等压缩工具类,需注意,压缩和解压缩的方式必须保持一致。
5.4 避免数据倾斜
使用抽样统计、自定义Combine组件、将ReduceJoin改为Map Join等方式。
5.5 参数调优
在maped-default.xml、mapred-site.xml中调整参数值。
总结
以上就是MaapReduce相关内容了,简单介绍了一下MapReduce的作业执行流程、序列化、Shuffle机制和MapReduce调优!
参考《Hadoop大数据原理与运用》徐鲁辉