###在编写wordcount运行时出现权限不允许的问题,在这提一下解决方法
1)设置电脑环境变量 添加HADOOP_USER_NAME 值为你新建的虚拟机名
2)vi hdfs-site.xml 添加
dfs.permissions
false
之后重启电脑即可
#####mapreduce 由两部分组成
map()任务分解;
reduce()任务汇总;
####hdfs上的文件都是以块为单位存储的,Hadoop提交作业时需要将作业分片(逻辑上),每个分片一般由一个mapper处理,具体的分片细节由InputSplitFormat指定,一般分片大小不大于block大小。
######mapper执行过程
1)将文件分片,每一个片由一个mapper处理。
2)将输入片中的记录解析成键值对,键是每一行的起始位置,值是该行的文本内容。由mapreduce框架自动完成,即形成<k1,v1>
hello world
hello tom ----><0,hello world> <12,hello tom>
3)调用map() 方法,第二步解析出来的每一个键值对调用一次map(),即形成<k2,v2>
4)将第三阶段输出的键值对进行分区,默认只有一个分区,分区的数量就是reducer任务运行的数量,默认只有一个reducer任务。
5)对每个分区中的键值对进行排序,
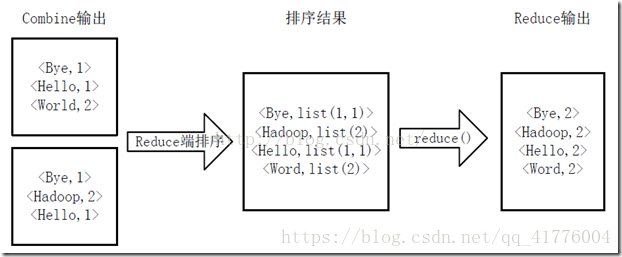
######reducer执行过程
1)reducer会主动复制mapper的输出,将复制后的键值对进行排序。
2)执行reduce(),键相等的键值对调用一次reduce方法,即生成<v3,k3>
#####具体执行代码
package com.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WcMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//接收数据map(k1,v1,k2,v2)k1:一行单词的起始位置,v1:一行单词的文本,k2:单词,v2:代表1
String line=value.toString();
//切分数据
String[] words=line.split(" ");
//循环
for(String w:words){
//出现1次,记个1 ,输出
context.write(new Text(w), new LongWritable(1));
}
}
}
package com.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WcReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text arg0, Iterable v2s,
Reducer<Text, LongWritable, Text, LongWritable>.Context arg2) throws IOException, InterruptedException {
// TODO Auto-generated method stub k2 v2 k3 v3
//定义一个计算器
long counter=0;
//循环v2s
for(LongWritable v:v2s){
counter+=v.get();
}
//输出
arg2.write(arg0, new LongWritable(counter));
}
}
package com.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;

public class WordCount {
public static void main(String[] args){
try {
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
//加载main方法所在的类
job.setJarByClass(WordCount.class);
//设置mapper与reducer的类
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
FileInputFormat.setInputPaths(job, new Path(“hdfs://192.168.17.128:9000/words.txt”));
FileOutputFormat.setOutputPath(job, new Path(“hdfs://192.168.17.128:9000/output”));
//设置输入和输出的相关属性
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
try {
job.waitForCompletion(true);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}//重要必写
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}