一、概述
- YARN(Yet Another Resource Negotiator,至今另一个资源调度器)是Hadoop2.0提供的一套用于进行任务调度和资源管理的机制
- YARN是Hadoop2.0中提供的最重要的特性之一。也是因为YARN的出现,导致Hadoop1.0和Hadoop2.0不兼容
- 原因
a 内部
① 在Hadoop1.0中,没有YARN,MapReduce分为主节点JobTracker以及从节点TaskTracker。但是在Hadoop1.0中,作为主节点的JobTracker只允许出现1个,所以存在单点故障
② 在Hadoop1.0中,JobTracker在分配完任务之后,会监控每一个TaskTracker的任务的执行情况。在TaskTracker的数量相对较少的情况下,JobTracker的效率还能保证。随着TaskTracker的数量的增多,JobTracker的效率就越来越难以保证。在官方文档中给定,每一个JobTracker最多能够管理4000个TaskTracker
b 外部:
① 在Hadoop刚开始设计的时候,整个Hadoop集群只考虑为计算模型MapReduce来分配资源而没有考虑为其他的计算模型来分配资源
② 随着大数据的发展,有越来越多的计算框架(Pig,Storm,Spark,Flink等)基于Hadoop来使用,这些框架之间彼此抢占资源导致资源冲突。也因此,需要提供了一个统一的资源管理机制来避免资源冲突
二、YARN的Job执行流程
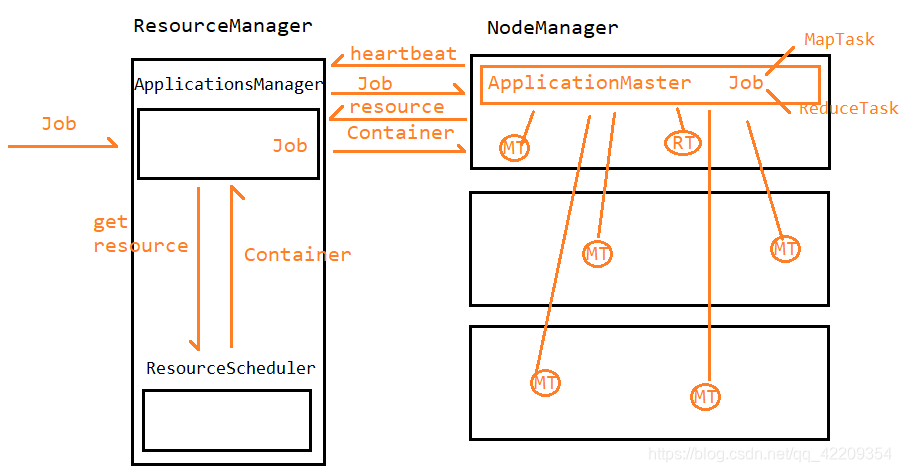
- 客户端将Job任务提交给ResourceManager中的ApplicationsManager,ApplicationsManager收到任务之后会将任务先临时存储在队列中,等待NodeManager的心跳
- 当ApplicationsManager收到NodeManager的心跳之后,会在心跳响应中,将Job任务返回给NodeManager, 并且会要求NodeManager在本节点上开启一个ApplicationMaster进程来处理这个Job任务
- 当NodeManager收到心跳响应之后,就会在本节点上来开启一个ApplicationMaster进程,并且会将Job任务交给这个进程来处理
- ApplicationMaster收到任务之后,会将这个Job任务来进行拆分,拆分成子任务。如果这是一个MapReduce任务,会将这个任务拆分成MapTask和ReduceTask。拆分完成之后,ApplicationMaster就会给ApplicationsManager发送请求,来请求自认为执行所需要的资源
- ApplicationsManager收到请求之后,会将请求转交给ResourceScheduler。ResourceScheduler会将资源的描述封装成一个Container对象返回给ApplicationsManager。ApplicationsManager收到Container之后,再转交给ApplicationMaster
- ApplicationMaster收到资源之后,会将资源分配给每一个子任务。分配完成之后,ApplicationMaster会将子任务分配到不同的NodeManager上执行,并且会监控这些子任务的执行情况
- 注意问题
a 每一个Job都会对应产生一个新的ApplicationMaster,从而保证任务之间的执行互相不影响
b 在YARN中,行了层级结构:ResourceManager中的ApplicationsManager管理ApplicationMaster,ApplicationMaster管理具体的子任务
• 由 ChiKong_Tam 写于 2021 年 1 月 14 日