1.为什么高可用?
之前的hdfs的nn+dn+snn架构,snn是一个小时备份一次,如果突然nn节点挂了,就算回到之前的备份,新数据已经丢失。
为了弥补这个缺点,有高可用架构nn+dn+nn,两个nn一主一备,其中一个挂了,另一个马上顶上。解决了单点问题。
2.HDFS高可用架构图
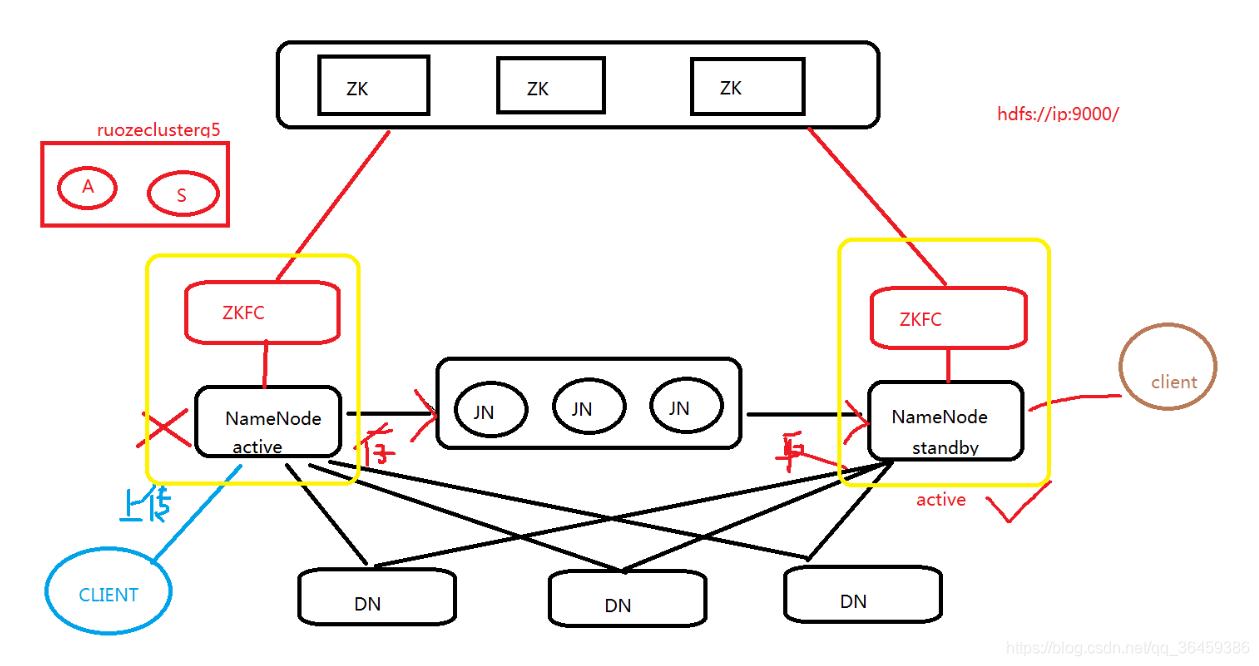 如图所示,两个nn通过jn(JounalNode 日志)来共享状态,而dn会同时向两个nn汇报心跳和blockreport。zk集群里的许多个zk通过选举ZKFC进程来控制nn状态。
如图所示,两个nn通过jn(JounalNode 日志)来共享状态,而dn会同时向两个nn汇报心跳和blockreport。zk集群里的许多个zk通过选举ZKFC进程来控制nn状态。
各个点的细节
-
ActiveNN:操作记录写到自己的editlog,
同时JN集群也会写一份;
接收 DN的心跳和blockreport -
StandbyNN: 接收JN集群的日志,
先是读取执行log操作(重演),使得自己的元数据和activenn节点保持一致;
接收 DN的心跳和blockreport; -
JounalNode: 用于 active standby nn节点的同步数据,部署是2n+1个(3个/5个–>7个),奇数个的原因是为避免两个nn得到的选票是一样的。
-
ZKFC: 单独的进程
监控NN的健康状态
向ZK定期发送心跳,使自己可以被选举;当自己被ZK选举为主的时候,
zkfc进程通过RPC调用使NN的状态变为active,对外提供实时服务,无感知。 -
hdfs地址问题: 假如
NN1 active hdfs://192.168.1.100:9000/ NN2 standby hdfs://192.168.1.101:9000/NN1地址是配置在
core-site.xml,如果他崩了,那么如何能切换到NN2呢? 命名空间:nameservice: ruozeclusterg5,在这里面设置nn的iphdfs dfs -ls hdfs://ruozeclusterg5/ -
zk部署:生产上50台规模以下 7台
50~100 9/11台
>100 11台 要是2n+1 奇数个,做选举
3.Yarn高可用

-
ZKFC: 线程
只作为RM进程的一个线程而非独立的守护进程来独立存在 -
RMStateStore:
a.RM把job信息存在在ZK的/rmstore(就是RMStateStore)下,activeRM会向这个目录写app信息
b.当active RM挂了,另外一个standby RM通过zkfc选举成功为active,会从/rmstore读取相应的作业信息。
重新构建作业的内存信息,启动内部服务,开始接收NM的心跳,构建集群的资源信息,并且接收客户端的作业提交请求。 -
RM:
a.启动时候的会向ZK的目录/hadoop-ha写个lock文件,写成功的话,就为active,否则为standby。
然后standby rm节点会一直监控这个lock文件是否存在,假如不存在,就试图创建,假如成功就为active。
b.接收client的请求。接收和监控NM的资源状况汇报,负载资源的分配和调度。
c.启动和监控ApplicationMaster(AM) on NM的container
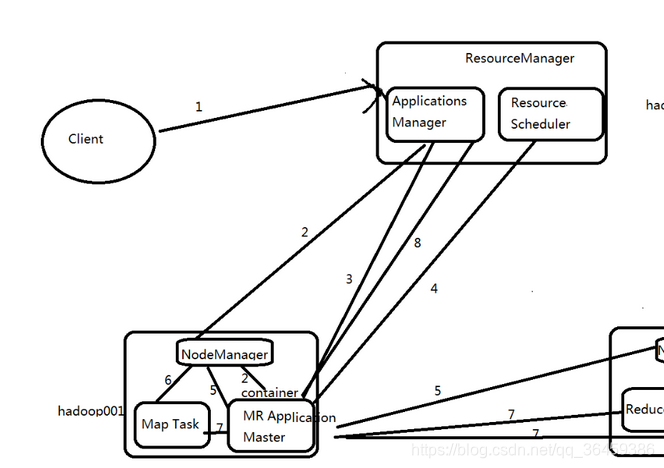
ApplicationMaster 就是JOB的老大相当于spark driver -
NM: 节点的资源管理
启动container运行task计算
上报资源
汇报task进度给AM ApplicationMaster
4.hdfs高可用和yarn高可用对比
zkfc:hdfs是进程,yarn是线程
dn/nm:hdfs的dn同时向两个nn汇报,yarn的nm只向active的rm汇报。