1. 概述
在此前的文章中,我们介绍了用于分类的算法:
k 近邻算法
决策树的构建算法 – ID3 与 C4.5 算法
但是,有时我们无法非常明确地得到分类,例如当数据量非常大时,计算每个样本与预测样本之间的距离或是构建决策树都会因为运算量过大而力不从心。
2. 朴素贝叶斯理论

假设我们有上面这个数据集,那么我们如何通过一个新的坐标预测新坐标应该属于哪个类别呢?
我们有下面三种方法:
- 使用 KNN 算法 – 进行 1000 次距离计算
- 使用决策树算法 – 分别沿X轴、Y轴划分数据
- 计算新的点属于每个类别的概率,并进行比较
显然,最佳的方法是方法3。
2.1. 贝叶斯概率
通常我们所说的概率指的是“频数概率”,不需要进行逻辑推理。
贝叶斯概率引入先验知识,通过逻辑推理来处理不确定性命题。
3. 条件概率
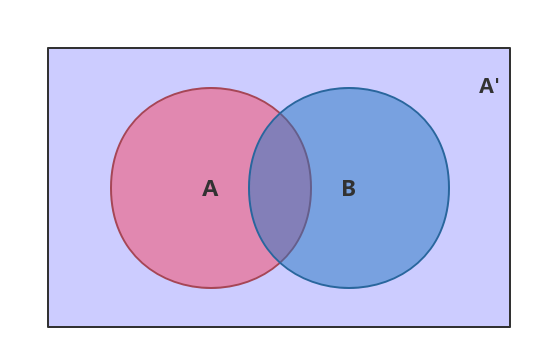
上面这幅维恩图中,我们可以清楚的看到,在事件 B 发生的情况下,事件 A 发生的概率就是 P(A∩B) 除以 P(B):
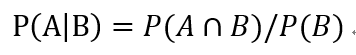
因此:
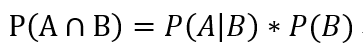
同理:
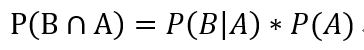
所以:
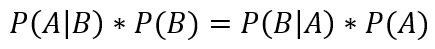
也就是:
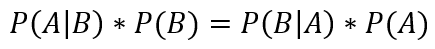
最后这个公式就是条件概率公式。
4.
我们把P(A)称为“先验概率”,即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B)称为“后验概率”,即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B)称为“可能性函数”,这是一个调整因子,使得预估概率更接近真实概率。
因此:
- 后验概率 = 先验概率 * 调整因子
这就是贝叶斯推断。
5. 朴素贝叶斯推断
P(A|X) 表示 X 条件下 A 事件发生的概率,那么假设 X 具有 n 个特征,那么:
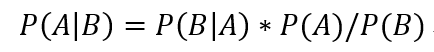
如果 n 个特征相互独立,那么可以进一步推导:
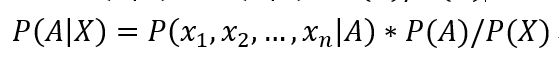
这个公式就是朴素贝叶斯推断,而他基于的基本假设:所有特征相互独立,就是条件独立性假设。
6. 朴素贝叶斯公式的应用
假设我们统计一个门诊的接诊情况如下:
门诊接诊情况
| 症状 | 职业 | 疾病 |
|---|---|---|
| 打喷嚏 | 护士 | 感冒 |
| 打喷嚏 | 农夫 | 过敏 |
| 头痛 | 建筑工人 | 脑震荡 |
| 头痛 | 建筑工人 | 感冒 |
| 打喷嚏 | 教师 | 感冒 |
| 头痛 | 教师 | 脑震荡 |
现在来了第七个病人,他是一个打喷嚏的建筑工人,那么如何计算他患感冒的概率呢?
6.1. 计算
根据朴素贝叶斯公式,我们可以求得:

即:
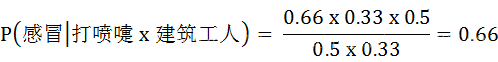
7. 通过 python 实现朴素贝叶斯算法
下面是一个预测一行文字是否是负面侮辱性语言的例子。
如果我们认为语句中,每个词出现的概率都是独立的,那么我们就可以应用朴素贝叶斯公式来计算给定的语句的分类概率了。
7.1. 程序示例
# -*- coding: UTF-8 -*-
# {{{
import numpy as np
from functools import reduce
def loadDataSet():
"""
创建实验样本
:return:
postingList - 实验样本切分的词条
classVec - 类别标签向量
"""
dataSet = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], # 切分的词条
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
results = [0, 1, 0, 1, 0, 1] # 类别标签向量,是否是侮辱性,0. 否,1. 是
return dataSet, results # 返回实验样本切分的词条和类别标签向量
def createVocabList(dataSet):
"""
获取去重后的词汇表
:param dataSet:
:return:
"""
vocabSet = set()
for document in dataSet:
vocabSet |= set(document)
return list(vocabSet)
def wordsToVector(dataList, vocabularys):
"""
将原始数据向量化,向量的每个元素为1或0
:param vocabularys: createVocabList返回的列表
:param dataList: 切分的词条列表
:return: 文档向量,词集模型
"""
vector = [0] * len(vocabularys)
for word in dataList: # 遍历每个词条
if word in vocabularys: # 如果词条存在于词汇表中,则置1
vector[vocabularys.index(word)] = 1
else:
print("the word: %s is not in my Vocabulary!" % word)
return vector # 返回文档向量
def trainNB0(trainMap, results):
"""
朴素贝叶斯分类器训练函数
:param trainMap: 训练文档矩阵
:param results: 训练类别标签向量
:return:
p0Vect - 侮辱类的条件概率数组
p1Vect - 非侮辱类的条件概率数组
pAbusive - 文档属于侮辱类的概率
"""
dataListNum = len(trainMap)
vocabularysNum = len(trainMap[0])
""" 计算文档属于侮辱词概率 """
pAbusive = sum(results) / float(dataListNum)
p0Num = np.zeros(vocabularysNum)
p1Num = np.zeros(vocabularysNum) # 创建numpy.zeros数组,
p0Denom = 0.0
p1Denom = 0.0
""" 将所有行按是否是侮辱类分别叠加,统计各个词出现的次数 """
for i in range(dataListNum):
if results[i] == 1: # 统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMap[i]
p1Denom += sum(trainMap[i])
else: # 统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMap[i]
p0Denom += sum(trainMap[i])
""" 计算概率 """
p1Vect = p1Num / p1Denom
p0Vect = p0Num / p0Denom
return p0Vect, p1Vect, pAbusive # 返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
"""
朴素贝叶斯分类器分类函数
:param vec2Classify: 待分类的词条数组
:param p0Vec: 侮辱类的条件概率数组
:param p1Vec: 非侮辱类的条件概率数组
:param pClass1: 文档属于侮辱类的概率
:return: 是否属于侮辱类,0. 不属于,1. 属于
"""
p1 = reduce(lambda x, y: x * y, vec2Classify * p1Vec) * pClass1 # 对应元素相乘
p0 = reduce(lambda x, y: x * y, vec2Classify * p0Vec) * (1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0
if __name__ == '__main__':
""" 创建实验样本 """
dataSet, results = loadDataSet()
""" 去重,创建词汇表 """
vocabularys = createVocabList(dataSet)
trainMap = []
""" 构造向量矩阵,标记每一行出现的词语 """
for dataList in dataSet:
trainMap.append(wordsToVector(dataList, vocabularys))
p0V, p1V, pAb = trainNB0(np.array(trainMap), np.array(results))
testEntry = ['love', 'my', 'dalmation'] # 测试样本1
thisDoc = np.array(wordsToVector(testEntry, vocabularys))
if classifyNB(thisDoc, p0V, p1V, pAb):
print(testEntry, '属于侮辱类') # 执行分类并打印分类结果
else:
print(testEntry, '属于非侮辱类') # 执行分类并打印分类结果
testEntry = ['stupid', 'garbage'] # 测试样本2
thisDoc = np.array(wordsToVector(testEntry, vocabularys))
if classifyNB(thisDoc, p0V, p1V, pAb):
print(testEntry, '属于侮辱类') # 执行分类并打印分类结果
else:
print(testEntry, '属于非侮辱类') # 执行分类并打印分类结果
# }}}
7.2. 原理解读
基本的原理其实很简单,就是统计各个词分别属于侮辱类和非侮辱类的出现次数,从而就可以计算他们的概率了。
8. 参考资料
Peter Harrington 《机器学习实战》。
https://blog.csdn.net/c406495762/article/details/77341116。