考虑一下,CPU一般都是32或64位的寄存器,一次处理的数据长度达到32或64位,对于图像处理来说,一般是每个像素以8位为单位,那么我们在对一幅图像每个像素做处理时,用32位或64位的寄存器来处理8位的数据,其实就是一性能上的浪费。有没有办法充分利用CPU 32/64位的处理能能力,让CPU一次处理多个8位数据呢?这就是本文要说的SIMD.
向量化( Vectorization)
向量化( Vectorization)是一种单指令多数据( Single Instruction Mutiple Data,简称SIMD)的并行执行方式。具体而言,向量化是指相同指令在硬件向量处理单元( Vector Processing Unit简称VPU)上对多个数据流进行操作。这些硬件向量处理单元也被称为SIMD单元。
例如,两个向量的加法形成的第三个向量就是一个典型的SMD操作。许多处理器具有可同时执行2、4、8或更多的SIMD(矢量)单元执行相同的操作。
它通过循环展开、数据依赖分析、指令重排等方式充分挖掘程序中的并行性,将程序中可以并行化的部分合成处理器支持的向量指令,通过复制多个操作数并把它们直接打包在寄存器中,从而完成在同一时间内采用同步方式对多个数据执行同一条指令,有效地提高程序性能。
还以前面图像处理的应用场景为例,向量化( Vectorization)可以允许一条SIMD指令一次实现多个8位像素的运算处理。以intel CPU的SSE指令为例,SSE的寄存器达到128bit宽度,一次可以实现16个byte的算术运算。(SSE是Intelr SIMD指令集,进一步,还有升级版的AVX 256bit,和AVX512)。可想而知,在不增加硬件设备投入的前提下,SIMD对于密集运算程序的性能会带来数倍乃至数十倍的提升。所以向量化可以充分挖掘处理器并行处理能力,非常适合于处理并行程度高的程序代码.
不同的CPU体系的有不同的SIMD指令集标准,比如:
Intel有的x86体系有SSE以及后续的升级版的AVX,AVX2,AVX512 等(参见《英特尔®流式 simd 扩展技术》).
arm 平台也有自己的SIMD指令集,叫NEON(参见《NEON》).
mips体系的SIMD指令集叫MSA(参见《MIPS SIMD》).
看到这里估计你该头痛了,SIMD好是好,但这么多互不兼容SIMD指令标准。实际开发中该怎么用呢?
向量化的实现通常可采用两种方式:自动向量化和手动向量化.
手动向量化
通过内嵌手工编写的汇编代码或目标处理器的内部函数来添加SIMD指令从而实现代码的向量化。
说白了,就是开发者要手工编写汇编程序使用CPU的SIMD指令来实现向量化( Vectorization)。这要求开发者具备很高的底层汇编开发能力,这个过程对于开发者而言痛苦而低效。而且只能针对特定平台编写程序,代码不能跨平台使用,总之代价很高,吃力不讨好。
自动向量化
编译器通过分析程序中控制流和数据流的特征,识别并选出可以向量化执行的代码,并将标量指令自动转换为相应的SMD指令的过程。
也就是说,向量化的过程由编译器自动完成,开发者只要编写正常的C代码就好,编译器会自动分析代码结构,将适合向量化的C代码部分自动生成SIMD指令的向量化代码。而且这些C代码可以跨平台编译,针对不同的平台生成不同的SIMD指令。开发者不需要详细了解SIMD指令的用法。也不需要具备汇编程序的编写能力。
2013年, OpenMP4.0提供了预处理指令simd对函数和循环进行向量化。现在主流编译器都支持了OpenMP4.0(比如gnu,intel Compiler,参见 https://www.openmp.org/resources/openmp-compilers-tools/)。感谢OpenMP4.0,为SIMD指令的跨平台应用提供了可能。
OpenMP又是啥?
按照Wiki的解释,OpenMP(Open Multi-Processing)是一套支持跨平台共享内存方式的多线程并发的编程API,使用C,C++和Fortran语言,可以在大多数的处理器体系和操作系统中运行,包括Solaris, AIX, HP-UX, GNU/Linux, Mac OS X, 和Microsoft Windows。包括一套编译器指令、库和一些能够影响运行行为的环境变量。参见(https://zh.wikipedia.org/wiki/OpenMP)
OpenMP早期是用来实现跨平台的多线程并发编程的一套标准。到了OpenMP4.0加入了对SIMD指令的支持,以实现跨平台的向量化支持。
那么如何使用OpenMP来实现SIMD指令优化呢(向量化)呢?简单说只要在代码的循环逻辑前加入#pragma omp simd预处理指令就可以,不需要任何依赖库。简单吧?
#pragma omp simd指令应用于代码中的循环逻辑,可以让多个迭代的循环利用simd指令实现并发执行。
示例
多说无益,还是举个栗子吧!
下面就是一个简单BGRA转RGB图像的程序,没有什么复杂的逻辑,就是把4字节BGRA格式像素转为3字节的RGB格式像素。与普通的C程序没有任何不同,只是在for循环前面多了一个#pragma omp simd预处理指令。
这个预处理令告诉编译器下面这个循环要使用SIMD指令来实现向量化。
test_simd.c
/*
* test_simd.c
*
* Created on: Nov 27, 2018
* Author: gyd
*/
#if 1
void bgra2rgb(const char *src,char*dst,int w,int h)
{
#pragma omp simd
for(int y=0;y<h;++y)
{
for(int x=0;x<w;++x)
{
dst[(y*w+x)*3 ] = src[(y*w+x)*4 + 2];
dst[(y*w+x)*3+1] = src[(y*w+x)*4 + 1];
dst[(y*w+x)*3+2] = src[(y*w+x)*4 + 0];
}
}
}
int main()
{
char bgra_mat[480*640*4];
char rgb_mat[480*640*3];
bgra2rgb(bgra_mat,rgb_mat,480,640);
}
#endif
程序部分就这样了,只是多了一行预处理指令而已,够简单吧。重要的是代码的编译方式,以gcc编译器为例,下面是命令行编译test_simd.c的过程:
$ gcc -O3 -fopt-info -fopenmp -mavx2 -o test_simd test_simd.c
test_simd.c:13:3: note: loop vectorized
test_simd.c:13:3: note: loop versioned for vectorization because of possible aliasing
上面编译命令执行时输出test_simd.c:13:3: note: loop vectorized,就显示line 13的循环代码已经实现了循环向量化.下面详细解释几个特别的编译选项的意义:
-
-fopenmp打开OpenMP预处理指令支持开关,使用此选项,代码中的#pragma omp simd预处理指令才有效。
参见 https://gcc.gnu.org/onlinedocs/gcc/C-Dialect-Options.html#C-Dialect-Options -
-mavx2指定使用intel AVX2指令集。如果目标CPU不支持AVX,也可以根据目标CPU的类型改为低版本的-msse4.1 -msse4.2 -msse4 -mavx
参见 https://gcc.gnu.org/onlinedocs/gcc/Option-Summary.html#Option-Summary -
-fopt-info显示优化过程的输出,该选项只是用于输出显示,指示哪些代码已经被优化了,可以不用,就没有上面的输出显示。
参见 https://gcc.gnu.org/onlinedocs/gcc/Developer-Options.html#Developer-Options -
-O33级优化选项,参见 https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html#Optimize-Options
对于mips平台,编译方式是这样的,与x86平台唯一的不同就是-mavx2改为-mmsa(参见 《Option-Summary》):
$ mips-linux-gnu-gcc -O3 -fopt-info -fopenmp -mmsa -o test_simd_msa test_simd.c
test_simd.c:13:3: note: loop vectorized
test_simd.c:13:3: note: loop versioned for vectorization because of possible aliasing
如果是arm平台,编译方式应该是这样的(我还没有试过),参见参考资料5,6:
arm-none-linux-gnueabi-gcc -mfpu=neon -ftree-vectorize -ftree-vectorizer-verbose=1 -c test_simd.c
验证
如何验证代码是SIMD指令实现的呢?
最直接的办法 就是查看生成的可执行文件的反汇编代码。
可以用gdb打开生成的可执行文件test_simd,通过查看生成的指令来验证是否对循环实现了向量化优化。
执行gdb test_simd打开gdb,再执行disassemble /m bgra2rgb显示bgra2rgb函数的汇编代码,翻几页就可以看到类似vmovdqa 0x52f(%rip),%ymm11这样的指令,像vmovdqa这种v开头的指令就是AVX2的SIMD指令。代表SIMD指令已经被用于程序中
$ gdb test_simd
GNU gdb (Ubuntu 7.11.1-0ubuntu1~16.5) 7.11.1
Copyright (C) 2016 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word".
(gdb) disassemble /m bgra2rgb
Dump of assembler code for function bgra2rgb:
0x0000000000400660 <+0>: test %ecx,%ecx
0x0000000000400662 <+2>: jle 0x400a1a <bgra2rgb+954>
0x0000000000400668 <+8>: lea 0x8(%rsp),%r10
0x000000000040066d <+13>: and $0xffffffffffffffe0,%rsp
0x0000000000400671 <+17>: lea 0x0(,%rdx,4),%eax
0x0000000000400678 <+24>: xor %r11d,%r11d
0x000000000040067b <+27>: pushq -0x8(%r10)
0x000000000040067f <+31>: push %rbp
0x0000000000400680 <+32>: mov %rsp,%rbp
0x0000000000400683 <+35>: push %r15
0x0000000000400685 <+37>: push %r14
0x0000000000400687 <+39>: push %r13
0x0000000000400689 <+41>: push %r12
0x000000000040068b <+43>: xor %r13d,%r13d
0x000000000040068e <+46>: push %r10
0x0000000000400690 <+48>: push %rbx
0x0000000000400691 <+49>: xor %r10d,%r10d
0x0000000000400694 <+52>: xor %ebx,%ebx
0x0000000000400696 <+54>: mov %eax,-0x34(%rbp)
0x0000000000400699 <+57>: lea (%rdx,%rdx,2),%eax
0x000000000040069c <+60>: vmovdqa 0x41c(%rip),%ymm8 # 0x400ac0
0x00000000004006a4 <+68>: mov %eax,-0x38(%rbp)
---Type <return> to continue, or q <return> to quit---
0x00000000004006a7 <+71>: mov %edx,%eax
0x00000000004006a9 <+73>: lea (%rax,%rax,2),%r15
0x00000000004006ad <+77>: shl $0x2,%rax
0x00000000004006b1 <+81>: mov %rax,-0x40(%rbp)
0x00000000004006b5 <+85>: lea -0x21(%rdx),%eax
0x00000000004006b8 <+88>: shr $0x5,%eax
0x00000000004006bb <+91>: add $0x1,%eax
0x00000000004006be <+94>: mov %eax,-0x54(%rbp)
0x00000000004006c1 <+97>: shl $0x5,%eax
0x00000000004006c4 <+100>: mov %eax,-0x48(%rbp)
0x00000000004006c7 <+103>: lea -0x1(%rdx),%eax
0x00000000004006ca <+106>: mov %eax,-0x44(%rbp)
0x00000000004006cd <+109>: lea (%rax,%rax,2),%rax
0x00000000004006d1 <+113>: mov %rax,-0x50(%rbp)
0x00000000004006d5 <+117>: nopl (%rax)
0x00000000004006d8 <+120>: test %edx,%edx
0x00000000004006da <+122>: jle 0x4009ac <bgra2rgb+844>
0x00000000004006e0 <+128>: movslq %r11d,%r9
0x00000000004006e3 <+131>: movslq %ebx,%r12
0x00000000004006e6 <+134>: lea (%rdi,%r9,1),%r8
0x00000000004006ea <+138>: add -0x40(%rbp),%r9
0x00000000004006ee <+142>: lea (%rsi,%r12,1),%rax
0x00000000004006f2 <+146>: add %rdi,%r9
---Type <return> to continue, or q <return> to quit---
0x00000000004006f5 <+149>: cmp %r9,%rax
0x00000000004006f8 <+152>: lea (%r15,%r12,1),%r9
0x00000000004006fc <+156>: setae %r14b
0x0000000000400700 <+160>: add %rsi,%r9
0x0000000000400703 <+163>: cmp %r9,%r8
0x0000000000400706 <+166>: setae %r9b
0x000000000040070a <+170>: or %r9b,%r14b
0x000000000040070d <+173>: je 0x4009e0 <bgra2rgb+896>
0x0000000000400713 <+179>: cmp $0x1f,%edx
0x0000000000400716 <+182>: jbe 0x4009e0 <bgra2rgb+896>
0x000000000040071c <+188>: xor %r9d,%r9d
0x000000000040071f <+191>: cmpl $0x1f,-0x44(%rbp)
0x0000000000400723 <+195>: jbe 0x40095c <bgra2rgb+764>
0x0000000000400729 <+201>: vmovdqa 0x52f(%rip),%ymm11 # 0x400c60
0x0000000000400731 <+209>: vmovdqa 0x547(%rip),%ymm10 # 0x400c80
0x0000000000400739 <+217>: vmovdqa 0x55f(%rip),%ymm9 # 0x400ca0
0x0000000000400741 <+225>: vmovdqa 0x577(%rip),%ymm7 # 0x400cc0
0x0000000000400749 <+233>: vmovdqa 0x58f(%rip),%ymm6 # 0x400ce0
0x0000000000400751 <+241>: vmovdqa 0x5a7(%rip),%ymm5 # 0x400d00
0x0000000000400759 <+249>: vmovdqa 0x5bf(%rip),%ymm4 # 0x400d20
0x0000000000400761 <+257>: vmovdqu (%r8),%xmm1
0x0000000000400766 <+262>: add $0x1,%r9d
0x000000000040076a <+266>: sub $0xffffffffffffff80,%r8
---Type <return> to continue, or q <return> to quit---
0x000000000040076e <+270>: add $0x60,%rax
0x0000000000400772 <+274>: vmovdqu -0x60(%r8),%xmm13
0x0000000000400778 <+280>: vinserti128 $0x1,-0x70(%r8),%ymm1,%ymm1
0x000000000040077f <+287>: vmovdqu -0x40(%r8),%xmm3
0x0000000000400785 <+293>: vinserti128 $0x1,-0x50(%r8),%ymm13,%ymm13
0x000000000040078c <+300>: vmovdqu -0x20(%r8),%xmm12
0x0000000000400792 <+306>: vinserti128 $0x1,-0x30(%r8),%ymm3,%ymm3
0x0000000000400799 <+313>: vinserti128 $0x1,-0x10(%r8),%ymm12,%ymm12
0x00000000004007a0 <+320>: vpand %ymm13,%ymm8,%ymm2
0x00000000004007a5 <+325>: vpsrlw $0x8,%ymm13,%ymm13
0x00000000004007ab <+331>: vpand %ymm1,%ymm8,%ymm0
0x00000000004007af <+335>: vpsrlw $0x8,%ymm1,%ymm1
0x00000000004007b4 <+340>: vpackuswb %ymm13,%ymm1,%ymm13
0x00000000004007b9 <+345>: vpand %ymm12,%ymm8,%ymm14
0x00000000004007be <+350>: vpsrlw $0x8,%ymm12,%ymm1
0x00000000004007c4 <+356>: vpackuswb %ymm2,%ymm0,%ymm0
0x00000000004007c8 <+360>: vpand %ymm3,%ymm8,%ymm2
0x00000000004007cc <+364>: vpsrlw $0x8,%ymm3,%ymm3
0x00000000004007d1 <+369>: vpackuswb %ymm1,%ymm3,%ymm1
0x00000000004007d5 <+373>: vpermq $0xd8,%ymm13,%ymm13
0x00000000004007db <+379>: vpackuswb %ymm14,%ymm2,%ymm14
0x00000000004007e0 <+384>: vpermq $0xd8,%ymm1,%ymm1
0x00000000004007e6 <+390>: vpand %ymm13,%ymm8,%ymm3
---Type <return> to continue, or q <return> to quit---
0x00000000004007eb <+395>: vpermq $0xd8,%ymm0,%ymm0
0x00000000004007f1 <+401>: vpermq $0xd8,%ymm14,%ymm14
0x00000000004007f7 <+407>: vpand %ymm1,%ymm8,%ymm1
0x00000000004007fb <+411>: vpand %ymm0,%ymm8,%ymm2
0x00000000004007ff <+415>: vpsrlw $0x8,%ymm0,%ymm0
0x0000000000400804 <+420>: vpand %ymm14,%ymm8,%ymm15
0x0000000000400809 <+425>: vpsrlw $0x8,%ymm14,%ymm14
0x000000000040080f <+431>: vpackuswb %ymm1,%ymm3,%ymm1
0x0000000000400813 <+435>: vpackuswb %ymm14,%ymm0,%ymm0
0x0000000000400818 <+440>: vpackuswb %ymm15,%ymm2,%ymm2
0x000000000040081d <+445>: vmovdqa 0x41b(%rip),%ymm15 # 0x400c40
0x0000000000400825 <+453>: vpermq $0xd8,%ymm1,%ymm1
0x000000000040082b <+459>: vpermq $0xd8,%ymm0,%ymm0
0x0000000000400831 <+465>: vpermq $0xd8,%ymm2,%ymm2
0x0000000000400837 <+471>: vpshufb 0x2c0(%rip),%ymm1,%ymm12 # 0x400b00
0x0000000000400840 <+480>: vpshufb 0x297(%rip),%ymm0,%ymm3 # 0x400ae0
0x0000000000400849 <+489>: vpermq $0x4e,%ymm12,%ymm13
0x000000000040084f <+495>: vpermq $0x4e,%ymm3,%ymm14
0x0000000000400855 <+501>: vpshufb 0x2e2(%rip),%ymm1,%ymm12 # 0x400b40
0x000000000040085e <+510>: vpshufb 0x2b9(%rip),%ymm0,%ymm3 # 0x400b2---Type <return> to continue, or q <return> to quit---
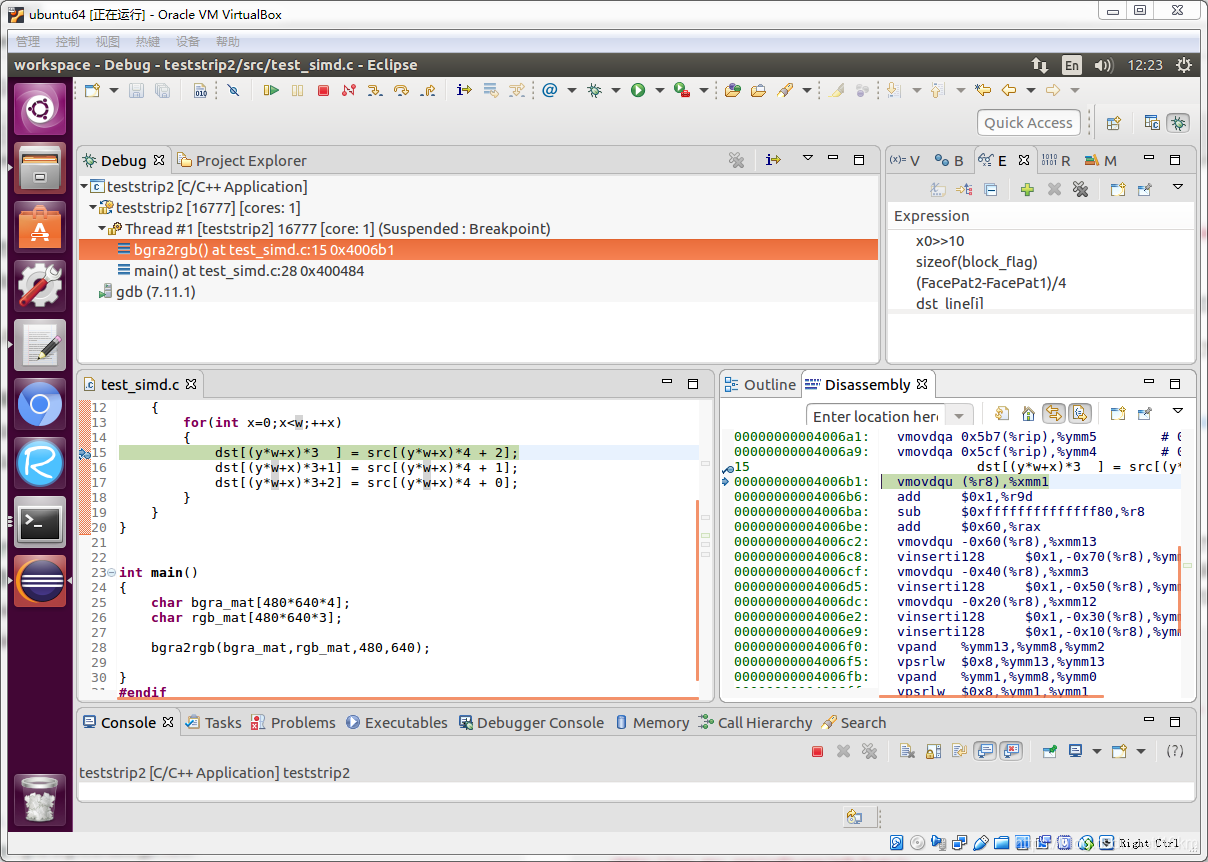
如果你不习惯用命令行的gdb工具,也可以用eclipse来查看反汇编代码,如下,在程序中加个断点,调试执行到指定的断点,在Disassembly窗口就可以查看到对应的汇编代码
总结
上面的例子非常简单,说明#pragma omp simd预处理指令的强大,但这并不是全部,也并不是表面看的那么简单,#pragma omp simd不是万能的,一段循环代码是不是能被向量化,有不少的限制条件。并不是所有的循环都可以直接用#pragma omp simd来向量化优化。关于#pragma omp simd更详细的说明请参见参考资料2,3。如果你觉得英文看得吃力,建议找本书翻翻,系统化的资料比网上零散的文章看起来更有效率,比如这本《多核异构并行计算(OpenMP4.5C\C++篇)》 ,我也是前几天从京东买的,写得一般,不够通俗,但这样的系统化中文书籍本身就不多,也只有它了,看看就成。
参考资料:
1.《#pragma omp simd - IBM》
2.《PDF:SIMD Vectorization with OpenMP》
3.《Options Controlling C Dialect.》
4. 《GCC Developer Options》
5. 《ARM NEON Development》
6. 《1.4.3. Automatic vectorization》
7. 《OpenMP in Visual C++》