1. 执行模式
概述:
OpenMP是跨平台的多核多线程编程的一套指导性的编译处理方案(Compiler Directive),指导编译器将代码编译为多线程程序。
Openmp的执行模型采用fork-join的形式,其中fork(派生)创建新线程或者唤醒已有线程;join即多线程的会合。
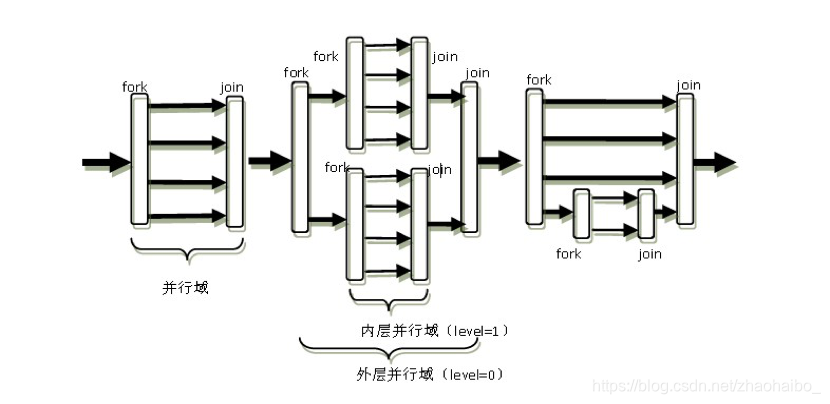
OpenMP的编程者需要在可并行工作的代码部分用制导指令向编译器指出其并行属性。(并行区域可以出现嵌套的情况)。
并行域与线程:
- 对**并行域(Paralle region)**作如下定义:在成对的fork和join之间的区域,称为并行域,它既表示代码也表示执行时间区间。
- 对OpenMP线程作如下定义:在OpenMP程序中用于完成计算任务的一个执行流的执行实体,可以是操作系统的线程也可以是操作系统上的进程。
2. OpenMP编程要素
OpenMP编程模型以线程为基础,通过编译制导指令来显式地指导并行化,OpenMP为编程人员提供了三种编程要素来实现对并行化的完善控制。它们是编译制导、API函数集和环境变量。
2.1编译制导
C/C++程序中,OpenMP的所有编译制导指令是以#pragma omp开始,后面跟具体的功能指令(或命令),其具有如下形式:
#pragma omp 指令 子句
支持OpenMP的编译器能识别、处理这些制导指令并实现其功能。其中指令或命令是可以单独出现的,而子句则必须出现在制导指令之后。制导指令和子句按照功能可以大体上分成四类:
- 并行域控制类;
- 任务分担类;
- 同步控制类;
- 数据环境类。
OpenMP规范中的指令:
- parallel:用在一个结构块之前,表示这段代码将被多个线程并行执行;
- for:用于for循环语句之前,表示将循环计算任务分配到多个线程中并行执行,以实现任务分担,必须由编程人员自己保证每次循环之间无数据相关性;
- sections:用在可被并行执行的代码段之前,用于实现多个结构块语句的任务分担,可并行执行的代码段各自用section指令标出(注意区分sections和section);
- single:用在并行域内,表示一段只被单个线程执行的代码;
- critical:用在一段代码临界区之前,保证每次只有一个OpenMP线程进入;
- flush、barrier、atomic、master、threadprivate …
相应的OpenMP子句:
- private:指定一个或多个变量在每个线程中都有它自己的私有副本;
- firstprivate:指定一个或多个变量在每个线程都有它自己的私有副本,并且私有变量要在进入并行域或任务分担域时,继承主线程中的同名变量的值作为初值;
- lastprivate:是用来指定将线程中的一个或多个私有变量的值在并行处理结束后复制到主线程中的同名变量中,负责拷贝的线程是for或sections任务分担中的最后一个线程;
- reduction:用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的归约运算,并将结果返回给主线程同名变量;
- nowait:指出并发线程可以忽略其他制导指令暗含的路障同步;
- num_threads:指定并行域内的线程的数目;
- schedule、shared、ordered、copyprivate、copyin、default…
2.2 API函数
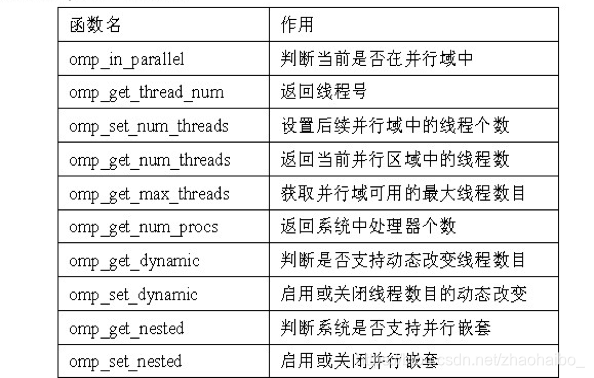
除上述编译制导指令之外,OpenMP还提供了一组API函数用于控制并发线程的某些行为,下面列出OpenMP 2.5所有的API函数:
2.3 环境变量
OpenMP规范定义了一些环境变量,可以在一定程度上控制OpenMP程序的行为。以下是开发过程中常用的环境变量
OMP_SCHEDULE:用于for循环并行化后的调度,它的值就是循环调度的类型;OMP_NUM_THREADS:用于设置并行域中的线程数;OMP_DYNAMIC:通过设定变量值,来确定是否允许动态设定并行域内的线程数;OMP_NESTED:指出是否可以并行嵌套。
编译方式
C / C++编译语句添加:-fopenmp
3. 并行域管理
parallel制导语句:开辟并行域,也可组合使用形成复合指令 由线程组并行执行
例:开辟并行域
#include <stdio.h>
#include <omp.h>
int main()
{
#pragma omp parallel
{
printf("hello world! from thread_num %d\n", omp_get_thread_num());
}
return 0;
}
输出:
hello world! from thread_num 5
hello world! from thread_num 4
hello world! from thread_num 8
hello world! from thread_num 6
hello world! from thread_num 2
hello world! from thread_num 13
hello world! from thread_num 3
hello world! from thread_num 19
hello world! from thread_num 16
hello world! from thread_num 12
hello world! from thread_num 7
hello world! from thread_num 1
hello world! from thread_num 11
hello world! from thread_num 14
hello world! from thread_num 9
hello world! from thread_num 10
hello world! from thread_num 15
hello world! from thread_num 18
hello world! from thread_num 17
hello world! from thread_num 0
可以通过omp_set_num_threads(n);设置使用的线程数
#include <stdio.h>
#include <omp.h>
int main()
{
omp_set_num_threads(2);
#pragma omp parallel
{
printf("hello world! from thread_num %d\n", omp_get_thread_num());
}
return 0;
}
输出:
hello world! from thread_num 0
hello world! from thread_num 1
4. 任务分担
当使用parellel制导指令产生出并行域之后,如果仅仅是多个线程执行完全相同的任务,那么只是徒增计算工作量而不能达到加速计算的目的,甚至可能相互干扰得出错误结果。因此在产生出并行域之后,紧接着的问题就是如何将计算任务在这些线程之间分配,并加快计算结果的生成速度及其保证正确性。
OpenMP可以完成的任务分担的指令只有for、sections和single。
4.1 for制导指令
for制导语句:指定紧随它的循环语句由线程组并行执行
例:for制导语句
#include <stdio.h>
#include <omp.h>
int main()
{
#pragma omp parallel
{
int i;
#pragma omp for
for (i = 0; i < 4; i++)
printf("i = %d,from thread_num%d\n", i, omp_get_thread_num());
}
return 0;
}
写法2: parallel for开辟for并行域
#include <stdio.h>
#include <omp.h>
int main()
{
int i;
#pragma omp parallel for
for (i = 0; i < 4; i++)
printf("i = %d,from thread_num%d\n", i, omp_get_thread_num());
return 0;
}
这里我们对第一层循环并行执行,第二层循环非并行执行:
#include <stdio.h>
#include <omp.h>
int main()
{
int i, j;
#pragma omp parallel for
for (i = 0; i < 4; i++)
printf("i = %d,from thread_num%d\n", i, omp_get_thread_num());
puts("");
for (j = 0; j < 4; j++)
printf("j = %d,from thread_num%d\n", j, omp_get_thread_num());
return 0;
}
输出:
i = 3,from thread_num3
i = 2,from thread_num2
i = 1,from thread_num1
i = 0,from thread_num0
j = 0,from thread_num0
j = 1,from thread_num0
j = 2,from thread_num0
j = 3,from thread_num0
特殊情况:一个并行域中有多个for制导指令 首先完成第一个for语句的任务分担,然后在此进行一次同步(for制导指令本身隐含有结束处的路障同步)
例:多个for制导指令
#include <stdio.h>
#include <omp.h>
int main()
{
int i, j;
#pragma omp parallel
{
#pragma omp for
for (i = 0; i < 4; i++)
printf("i = %d,from thread_num%d\n", i, omp_get_thread_num());
#pragma omp single
printf("\n");
#pragma omp for
for (j = 0; j < 4; j++)
printf("j = %d,from thread_num%d\n", j, omp_get_thread_num());
}
return 0;
}
输出: 第一个for循环结束后进行了一次同步
i = 1,from thread_num1
i = 3,from thread_num3
i = 2,from thread_num2
i = 0,from thread_num0
j = 2,from thread_num2
j = 0,from thread_num0
j = 1,from thread_num1
j = 3,from thread_num3
4.2 for调度
在OpenMP中,对for循环任务调度使用schedule子句来实现,一个简单的理解:一个for循环假设有10次迭代,使用4个线程去执行,那么哪些线程去执行哪些迭代呢?通过schedule去控制迭代的调度和分配,从而适应不同的使用情况,提高性能。使用格式为:schedule (type ,size)。
有四种type:static、dynamic、guided、runtime, 如果没有指定size大小,循环迭代会尽可能平均地分配给每个线程。
static:“静态”体现在这个分配过程跟实际的运行是无关的,可以从逻辑上推断出哪几次迭代会在哪几个线程上运行。具体而言,对于一个N次迭代,使用M个线程,那么,[0,size-1]的size次的迭代是在第一个线程上运行,[size, size + size -1]是在第二个线程上运行,依次类推。dynamic: 较快的线程抢到更多的任务,没有size参数的情况下,每个线程按先执行完先分配的方式执行1次循环;dynamic也可以设置size参数,size表示每次线程执行完(空闲)的时候给其一次分配的迭代的数量guided:采用指导性的启发式自调度方式runtime: 表示根据环境变量确定上述调度策略中的某一种,默认也是静态的 (static), 控制schedule环境变量的是OMP_SCHEDULE环境变量
例:for调度中的schedule子句 : static静态分配方式
#include <stdio.h>
#include <omp.h>
int main()
{
int NUM_THREADS = omp_get_num_procs();
int i;
#pragma omp parallel for schedule(static, 2)
for (i = 0; i < NUM_THREADS; i++)
printf("i=%d, from thread_num %d\n", i, omp_get_thread_num());
return 0;
}
输出
i=0, from thread_num 0
i=1, from thread_num 0
i=4, from thread_num 2
i=5, from thread_num 2
i=12, from thread_num 6
i=13, from thread_num 6
i=14, from thread_num 7
i=15, from thread_num 7
i=18, from thread_num 9
i=19, from thread_num 9
i=10, from thread_num 5
i=11, from thread_num 5
i=6, from thread_num 3
i=7, from thread_num 3
i=16, from thread_num 8
i=17, from thread_num 8
i=8, from thread_num 4
i=9, from thread_num 4
i=2, from thread_num 1
i=3, from thread_num 1
例:for调度中的schedule子句 : dynamic动态分配方式,不指定size
#include <stdio.h>
#include <omp.h>
int v[25]; //记录每个线程抢到的任务数
int main()
{
int NUM_THREADS = omp_get_num_procs(); // 线程总数
int i;
#pragma omp parallel for schedule(dynamic)
for (i = 0; i < 30; i++)
{
v[omp_get_thread_num()] ++;
printf("i=%d, from thread_num %d\n", i, omp_get_thread_num());
}
for (i = 0; i < NUM_THREADS; i ++)
{
printf("thread %d gets %d jobs\n", i, v[i]);
}
return 0;
}
i=4, from thread_num 6
i=12, from thread_num 12
i=21, from thread_num 12
i=22, from thread_num 12
i=23, from thread_num 12
i=9, from thread_num 13
i=25, from thread_num 13
i=26, from thread_num 13
i=27, from thread_num 13
i=28, from thread_num 13
i=29, from thread_num 13
i=10, from thread_num 10
i=0, from thread_num 9
i=7, from thread_num 3
i=17, from thread_num 8
i=3, from thread_num 15
i=1, from thread_num 5
i=15, from thread_num 11
i=14, from thread_num 0
i=5, from thread_num 2
i=6, from thread_num 4
i=8, from thread_num 18
i=20, from thread_num 6
i=24, from thread_num 12
i=16, from thread_num 14
i=18, from thread_num 7
i=13, from thread_num 17
i=2, from thread_num 1
i=19, from thread_num 19
i=11, from thread_num 16
thread 0 gets 1 jobs
thread 1 gets 1 jobs
thread 2 gets 1 jobs
thread 3 gets 1 jobs
thread 4 gets 1 jobs
thread 5 gets 1 jobs
thread 6 gets 2 jobs
thread 7 gets 1 jobs
thread 8 gets 1 jobs
thread 9 gets 1 jobs
thread 10 gets 1 jobs
thread 11 gets 1 jobs
thread 12 gets 5 jobs
thread 13 gets 6 jobs
thread 14 gets 1 jobs
thread 15 gets 1 jobs
thread 16 gets 1 jobs
thread 17 gets 1 jobs
thread 18 gets 1 jobs
thread 19 gets 1 jobs
例:for调度中的schedule子句 : dynamic动态分配方式,指定size
#include <stdio.h>
#include <omp.h>
int v[25];
int main()
{
int tot = omp_get_num_procs(); // 线程总数
int i;
#pragma omp parallel for schedule(dynamic, 2)
for (i = 0; i < 100; i++)
{
v[omp_get_thread_num()] ++;
printf("i=%d, from thread_num %d\n", i, omp_get_thread_num());
}
for (i = 0; i < tot; i ++)
{
printf("thread %d gets %d jobs\n", i, v[i]);
}
return 0;
}
i=22, from thread_num 19
i=23, from thread_num 19
i=40, from thread_num 19
i=41, from thread_num 19
...
i=8, from thread_num 3
i=9, from thread_num 3
i=14, from thread_num 9
i=15, from thread_num 9
thread 0 gets 2 jobs
thread 1 gets 2 jobs
thread 2 gets 2 jobs
thread 3 gets 2 jobs
thread 4 gets 2 jobs
thread 5 gets 2 jobs
thread 6 gets 2 jobs
thread 7 gets 16 jobs
thread 8 gets 2 jobs
thread 9 gets 2 jobs
thread 10 gets 2 jobs
thread 11 gets 2 jobs
thread 12 gets 2 jobs
thread 13 gets 2 jobs
thread 14 gets 2 jobs
thread 15 gets 2 jobs
thread 16 gets 2 jobs
thread 17 gets 2 jobs
thread 18 gets 2 jobs
thread 19 gets 48 jobs
4.3 sections 制导指令
用于非迭代计算的任务分担,将sections语句里的代码用section指导指令划分。不同的secion段由不同的线程并行执行。
#include <stdio.h>
#include <omp.h>
int main()
{
#pragma omp parallel sections
{
#pragma omp section
printf("section 1 from thread_num %d\n", omp_get_thread_num());
#pragma omp section
printf("section 2 from thread_num %d\n", omp_get_thread_num());
#pragma omp section
printf("section 3 from thread_num %d\n", omp_get_thread_num());
}
return 0;
}
section 1 from thread_num 12
section 3 from thread_num 4
section 2 from thread_num 2
多个sections:总体串行 单个sections内部并行
#include <stdio.h>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp sections
{
#pragma omp section
printf("section 1 from thread_num %d\n", omp_get_thread_num());
#pragma omp section
printf("section 2 from thread_num %d\n", omp_get_thread_num());
}
#pragma omp sections
{
#pragma omp section
printf("section 3 from thread_num %d\n", omp_get_thread_num());
#pragma omp section
printf("section 4 from thread_num %d\n", omp_get_thread_num());
}
}
return 0;
}
section 1 from thread_num 0
section 2 from thread_num 9
section 3 from thread_num 9
section 4 from thread_num 15
4.4 single制导指令
single制导指令所包含的代码段只由一个线程执行,别的线程跳过这段代码。
#include <stdio.h>
#include <omp.h>
int main()
{
omp_set_num_threads(4);
#pragma omp parallel
{
#pragma omp single
printf("Begining work1. \n");
printf("work on 1 parallellly. %d\n", omp_get_thread_num());
#pragma omp single nowait
printf("Finishing work1. \n");
#pragma omp single nowait
printf("Begining work2. \n");
printf("work on 2 parallelly. %d\n", omp_get_thread_num());
#pragma omp single
printf("Finishing work2. \n");
}
return 0;
}
Begining work1.
work on 1 parallellly. 0
Finishing work1.
Begining work2.
work on 2 parallelly. 0
Finishing work2.
work on 1 parallellly. 3
work on 2 parallelly. 3
work on 1 parallellly. 1
work on 2 parallelly. 1
work on 1 parallellly. 2
work on 2 parallelly. 2
5. 同步
多线程执行中不可避免数据竞争,openmp提供了两种线程互斥机制:互斥锁与事件同步机制。
5.1 critical 临界区
临界区用在可能产生数据访问竞争的地方,用法:#pragma omp critical (name) (name可省略)。保证每次只有一个线程进入。
注意:critical语句不允许互相嵌套
例:在一个并行域内的for任务分担域中,各个线程逐个进入到critical保护的区域内,比较当前元素的最大值得关系并可能进行最大值的更替,从而避免了数据竞争的情况。
#include <stdio.h>
#include <omp.h>
int main()
{
int i, max_x = -1, max_y = -1;
int arx[] = {5, 16, 87, 65, 24, 35, 9, 33};
int ary[] = {68, 4, 98, 43, 56, 18, 54, 11};
#pragma omp parallel for
for (i = 0; i < 8; i++)
{
#pragma omp critical
if (arx[i] > max_x)
max_x = arx[i];
#pragma omp critical
if (ary[i] > max_y)
max_y = ary[i];
}
printf("max_x = %d , max_y = %d\n", max_x, max_y);
return 0;
}
5.2 atomic原子操作
在OpenMP的程序中,原子操作的功能是通过#pragma omp atomic编译制导指令提供的。critical临界区操作能够作用在任意大小的代码块上,而原子操作只能作用在单条赋值语句中,C\C++中可用的原子操作如下:+ - * / & ^ | << >>
atomic在使用中需要注意:
- 当对一个数据进行原子操作的时候,就不能对数据进行临界区的保护
- 用户在针对同一个内存单元使用院子操作的时候,需要在程序所有涉及到该变量并行赋值的部位都加入原子操作的保护。
例:
#include <stdio.h>
#include <omp.h>
int main()
{
omp_set_num_threads(2);
int counter = 0, i;
#pragma omp parallel
{
for (i = 0; i < 10000; i++)
{
#pragma omp atomic
counter++;
}
}
printf("counter = %d\n", counter);
return 0;
}
由于使用atomic语句,避免了可能出现的数据访问竞争情况,最后的执行结果都是一致的,执行结果总是counter = 20000(假设有两个并发线程)。
5.3 barrier同步路障
线程遇到路障必须等待,直到并行区域内所有线程都达到了同一点。
5.4 nowait
避免不必要的路障
5.5 master
主线程执行用于指定一段代码由主线程执行。
5.6 ordered顺序制导指令
按照规定的顺序执行
5.7 互斥锁函数
OpenMP API所提供的互斥函数可放在任意需要的位置。程序员必须自己保证在调用相应锁操作之后释放相应的锁,否则就可能造成多线程程序的死锁。
下面为OpenMP API函数提供的互斥函数和可嵌套的互斥锁函数。
void omp_init_lock(omp_lock*):初始化互斥器
void omp_destroy_lock(omp_lock*):销毁互斥器
void omp_set_lock(omp_lock*):获得互斥器
void omp_unset_lock(omp_lock*):释放互斥器
void omp_test_lock(omp_lock*): 试图获得互斥器,如果获得成功则返回true,否则返回false
#include <stdio.h>
#include <omp.h>
static omp_lock_t lock;
int main()
{
int i;
omp_init_lock(&lock);
#pragma omp parallel for
for (i = 0; i < 5; ++i)
{
omp_set_lock(&lock);
printf("%d +\n", omp_get_thread_num());
printf("%d -\n", omp_get_thread_num());
omp_unset_lock(&lock);
}
omp_destroy_lock(&lock);
return 0;
}
上例对for循环中的所有内容进行加锁保护,同时只能有一个线程执行for循环中的内容。
线程1或线程2在执行for循环内部代码时不会被打断。如果删除代码中的获得锁释放锁的代码,则相当于没有互斥锁。
输出:
0 +
0 -
3 +
3 -
1 +
1 -
4 +
4 -
2 +
2 -
5.8 Flush 指令
flush指令主要用于处理内存一致性问题。每个处理器(processor)都有自己的本地(local)存储单元:寄存器和缓存,当一个线程更新了共享变量之后,新的值会首先存储到寄存器中, 然后更新到本地缓存中。这些更新并非立刻就可以被其他线程得知,因此在其它处理器中运行的线程不能访问这些存储单元。如果一个线程不知道这些更新而使用共享变量的旧值就行运算,就可能会得到错误的结果。
通过使用flush指令,可以保证线程读取到的共享变量的最新值。下面是语法形式:
#pragma omp flush[(list)]
例:第一个section的线程将flag刷新后,第二个线程才得以运行
// compile with: /openmp
#include <stdio.h>
#include <omp.h>
void read(int *data)
{
printf("read data\n");
*data = 1;
}
void process(int *data)
{
printf("process data\n");
(*data)++;
}
int main()
{
int data;
int flag = 0;
#pragma omp parallel sections num_threads(2)
{
#pragma omp section
{
printf("Thread %d: ", omp_get_thread_num());
read(&data);
#pragma omp flush(data)
flag = 1;
#pragma omp flush(flag)
// Do more work.
}
#pragma omp section
{
while (!flag)
{
printf("Thread %d: flushing... \n", omp_get_thread_num());
#pragma omp flush(flag)
if (flag) printf("Thread %d: flush complete. \n", omp_get_thread_num());
}
#pragma omp flush(data)
printf("Thread %d: ", omp_get_thread_num());
process(&data);
printf("data = %d\n", data);
}
}
}
输出:
Thread 1: flushing...
Thread 1: flushing...
Thread 1: flushing...
Thread 1: flushing...
Thread 1: flushing...
Thread 0: Thread 1: flushing...
read data
Thread 1: flushing...
Thread 1: flush complete.
Thread 1: process data
data = 2
6 数据环境控制
多线程的环境中不可避免共享变量和私有变量这两个基本问题,在此基础上还有线程专有数据、变量的初值和终值得设定、规约操作相关的变量等问题。
OpenMP中各个线程的变量是公有还是私有是依据OpenMP自身的规则和相关的数据子句而定,而不是依据操作系统线程或进程上的变量特性而定的。
6.1共享与私有化
- shared子句
shared子句用来声明一个或多个变量是共享变量。用法:shared(list) - default子句
default子句允许用户控制并行域中变量的共享属性。用法:default(shared | none)
使用shared时,默认情况下,传入并行域内的同名变量被当做共享变量来处理,不会产生线程私有副本。
如果使用none作为参数,除了那些有明确定义的,线程中用到的变量都必须显式指定为是共享的还是私有的。 - private子句
private子句将一个或多个变量声明为线程私有变量,变量声明成私有变量后,指定每个线程都有它自己的变量私有副本,其他线程无法访问私有副本。即使在并行域外有同名的共享变量,共享变量在并行域内不起任何作用,并且并行域内不会操作到外面的共享变量。 - firstprivate子句
firstprivate子句使并行域或任务分担开始执行时,私有变量通过主线程中的变量初始化 - lastprivate子句
for循环:最后一次循环迭代中的值给对应的共享变量;如果是sections构造,最后一个section语句中的值赋给对应的共享变量。 - flush
确保同步时程序被正确写入,flush指令将列表中的变量执行flush操作,直到所有变量都已完成相关操作后才返回。用法:flush(list)
6.2线程专有数据
- threadprivate子句
threadprivate子句用来指定全局的对象被各个线程复制了一个专有数据,即各个线程具有各自私有、线程范围内的全局对象。 用法:#pragma omp threadprivate(list) new-line - copyin子句
copyin子句用来将主线程中threadprivate变量的值复制到执行并行域的各个线程的threadprivate变量中,便于所有线程访问主线程中的变量值。用法:copyin(list)。copyin中的参数必须被声明成threadprivate的,对于类类型的变量,必须带有明确的拷贝赋值操作符。 - 规约操作
reduction子句用来对一个或多个参数条目指定一个操作符,每个线程将创建参数条目的一个私有拷贝,在并行域或任务分担域的结束处,将用私有拷贝的值通过指定的运行符运算,原始的参数条目被运算结果的值更新。用法:reduction(operator:list)
