感知机/k近邻/贝叶斯/决策树
前言:有时候公式实在不好理解的时候可以看一道例题理解,或者运行程序debug调试逐步看输入输出变化进行理解!
第二章感知机
感知机概念
输入到输出空间的映射:f(x) =sign(w*x+b)
sign函数如下:
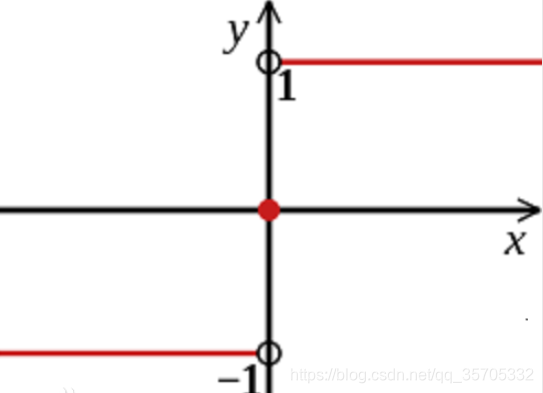
感知器是一种线性分类器模型,属于判别模型。
感知机是采用随机梯度下降,是在所有误分点中随机选一个误差点的梯度下降来跟新其的权重和偏执。
感知机学习算法原始形式
跟新权重与bias的方法也是梯度下降法:

具体算法实现步骤如下:

感知机的对偶形式
推导过程:
原始公式中权重与偏执的变化如下:
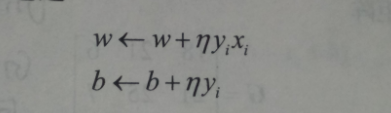
当w,b初始值设置为0时,上式可以变换为下面的式子,
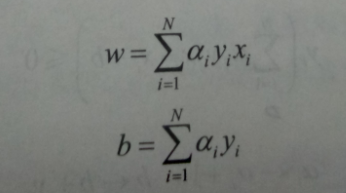
相当于w,b的迭代跟新转换到a上,具体如下,而对于a来说,每次迭代增量都是学习率,计算到最后一次后就是累加选中相应样本的次数*学习率。

感知机模型对偶形式:出现了內积的形式
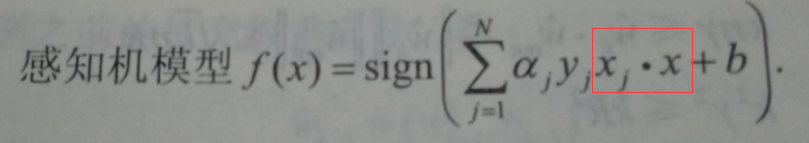
第三章 k近邻
概念
K近邻:利用欧氏距离衡量,计算要预测的点与已知点的距离,选取距离最近的K个样本点作为参考,接着使用多数表决法从k个最近的样本点判断预测点属于哪个类。多数表决法即K个点中属于C的类别数目多,支持为C类的多,则判定为C类。
k近邻算法的实现——KDTree的构造
实质就是中位数排序,以中位数划分子树。如图所示,首先利用第一维的数据进行中位数选择,紧接着利用第二维的数据特征做中位数排序…

k近邻算法的实现——KDTree的搜索
紧接着搜索树,有一种2分法的感觉,比线性扫描节省了太多时间!!线性扫描就是输入一个数对训练实例的每一个计算距离。。。。。
输入待检测点为(2,2,2)
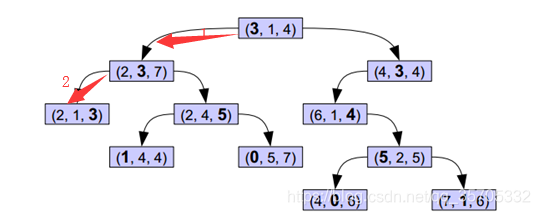
分别计算叶子结点(2,1,3),(2,3,7),(3,1,4)与待检测点欧氏距离,回溯到根节点距离最小为最近点。。。。。当训练数据较多依然计算量很大。
第4章 朴素贝叶斯
基本概念
先验概率:用P(Bi)表示没有训练数据前假设h拥有的初始概率,称为先验概率。
后验概率: P(Bi|A)为后验概率,给定A时Bi成立的概率,称为Bi的后验概率;
贝叶斯公式:
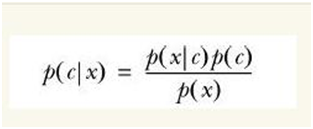
分类问题
假设之前已经统计了两类的分布情况,我们可以用p1(x,y)表示数据点(x,y)属于红色一类的概率,同时也可以用p2(x,y)表示数据点(x,y)属于蓝色一类的概率。出现一个新的点new_point (x,y),其分类未知。那要把new_point归在红、蓝哪一类呢?
一般用贝叶斯公式的分子替代整体:
如果p(red|x,y) > p(blue|x,y), 则(x,y)属于红色一类。
如果p(red|x,y) < p(blue|x,y), 则(x,y)属于蓝色一类。
最大似然估计——求模型参数
给定一堆数据,假如我们知道它是从某一种分布中随机取出来的,可是我们并不知道这个分布具体的参,即“模型已定,参数未知”。例如,我们知道这个分布是正态分布,但是不知道均值和方差;或者是二项分布,但是不知道均值。 最大似然估计(MLE,Maximum Likelihood Estimation)就可以用来估计模型的参数。但是在实际问题中并不都是这样幸运的,我们能获得的数据可能只有有限数目的样本数据,而先验概率 和类条件概率(各类的总体分布) 都是未知的。
贝叶斯算法实现流程


第五章 决策树
概念
决策树由结点和有向边组成。内部结点表示一个特征或者属性,叶子结点表示类别。树结构如图:
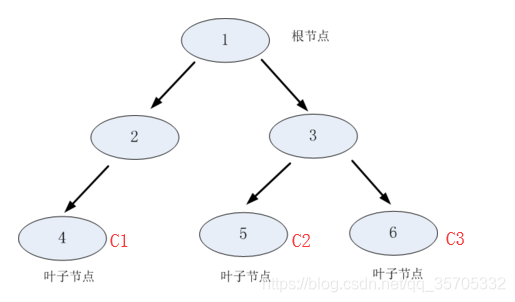
主要包含三部分:特征选择/决策树的生成/决策树剪枝;决策树学习就是寻找最优特征~
特征选择——信息增益、信息增益比
1.信息增益
熵:表示随机变量不确定性的度量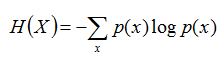
联合熵:两个随机变量X,Y的联合分布,可以形成联合熵Joint Entropy,用H(X,Y)表示。
条件熵:在随机变量X发生的前提下,随机变量Y发生所新带来的熵定义为Y的条件熵,用H(Y|X)表示,用来衡量在已知随机变量X的条件下随机变量Y的不确定性。
== 信息增益算法==
输入:训练数据集D和特征A;输出特征A对训练集D的信息增益g(D,A).

2.== 信息增益比==
主要解决信息增益的问题,信息增益容易造成选择取值较多的特征~~

决策树生成
-
ID3算法
应用信息增益准则选择特征,递归地构建决策树

-
C4.5算法
用信息增益比来选择特征,构建决策树

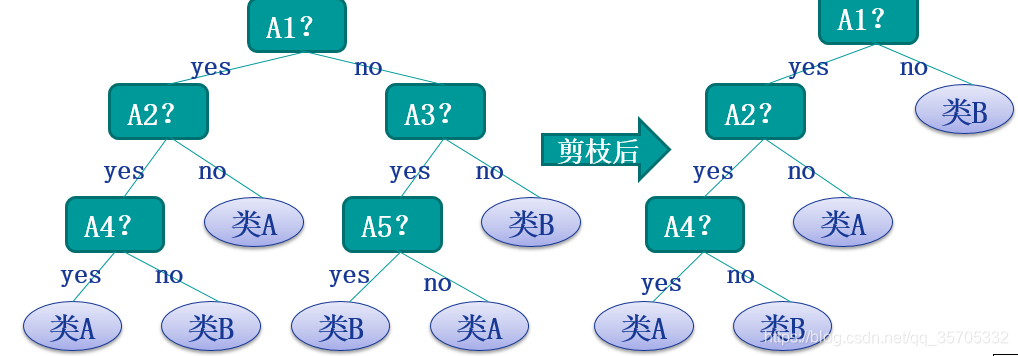
决策树的剪枝
为了防止过拟合,需要对决策树进行裁剪。裁剪分为事前裁剪和事后裁剪。事前裁剪发生在建立决策树时,通过判定规则(例如节点总数>),来决定是否进行新的分级。 事后裁剪发生在建立决策树后,通过判定规则进行树的修剪。准则:极小化决策树整体的损失函数。
理想的决策树有三种:
1.叶子节点数最少
2.叶子加点深度最小
3.叶子节点数最少且叶子节点深度最小。
预剪枝,设置树的深度为3,深度大于3的部分都不会构建;或者设置当分支样本数量小于50就停止构建树等等要求,在构建树的时候就进行剪枝;
后剪枝,由下图损失函数公式所示,叶子结点个数作为一个正则化项,希望叶子结点也少越好;前面一项为经验熵。

经验熵公式:
分别计算剪前叶子结点的损失函数与剪后叶子结点损失函数,对比,剪前大就直接减掉~
Ntk:对应叶结点中k类的样本点个数;
Nt:对应叶结点样本的个数
T:|T|为叶子结点个数
t:是树T的叶子结点
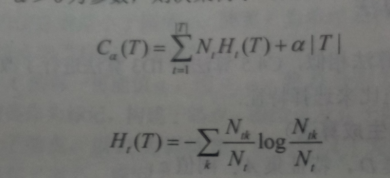
每一个叶子结点样本数乘上叶子结点的熵


剪枝过程的理解: