什么是统计学习?
统计学习方法 = 模型+策略+算法
模型指的是最后要学到一个条件概率分布或决策函数
策略指的是用什么准则选取最优的模型
比如选择损失函数(0-1损失,平方损失,绝对损失,均方损失)
算法指的是求解最优化问题的方法
什么是过拟合?过拟合一般的解决方法?
过拟合指的是模型在训练集表现很好,在测试集却很差。
解决方法
1. L1正则和L2正则:在模型中加入刻画模型复杂度的指标,即原损失函数上加上惩罚项
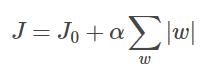
- L1正则化的模型叫做Lasso回归,L2正则化的模型叫做Ridge回归
- L1正则化是指权值向量w中各个元素的绝对值之和,L2正则化是指权值向量w中各个元素的平方和然后再求平方根
- L1 正则会让参数变稀疏(即会有更多的参数变成0),L2不会,故L1可用于特征选择
- 为什么?图像上,L1正则是正方形,L2正则是圆形。L1正则的往往取到正方形顶点,即有很多参数为0
(J0与这些顶点接触的机率会远大于与L其它部位接触的机率,而在这些顶点上,会有很多权值等于0)
2.Dropout
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
故dropout也可以防止过拟合
生成模型与判别模型
生成方法由数据学习联合概率分布P(X,Y),然后求出条件分布P(Y|X)
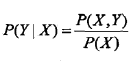
典型的生成模型有:logistic回归,朴素贝叶斯和隐马尔科夫模型
判别方法是由数据直接学习得到决策函数或条件概率分布
典型的判别模型有:k近邻法,感知机(perceptron)、决策树、LR、最大熵模型、SVM、提升方法、条件随机场等
感知机
感知机是一个二分类线性分类器,求得一个线性分离超平面
损失函数
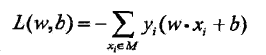
采用随机梯度下降(SGD)
随机梯度下降法:随机采样一些数据计算损失,然后极小化损失,而不是计算整个训练集的损失
算法原理

对偶形式
基本想法:将w 和b 表示为实例xi 和标记yi 的线性组合的形式,通过求解其系数而求得w 和b
一个误分类点更新一次参数,假设更新n次,故得其对偶形式
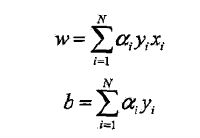
算法描述

对偶形式好处:对偶形式中训练实例仅以内积的形式出现,故可以预先计算训练集实例间的内积并以矩阵形式存储,好处就是方便计算….
支持向量机(SVM)
线性支持向量机与硬间隔最大化
二分类模型,与perceptron区别在于:间隔最大。 perceptron的解有无数多个,而SVM要求间隔最大,故解唯一
训练数据线性可分时,学习一个线性分类器,又称为硬间隔支持向量机
训练数据近似线性可分时,学习一个线性分类器,又称为软间隔支持向量机
训练数据线性不可分时,使用核技巧及软间隔最大化,得到非线性支持向量机
函数间隔
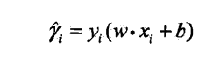
然后将所有点代入,取max(y~)
几何间隔
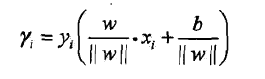
两者关系
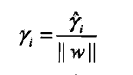
函数间隔将参数规范化后即得几何间隔
几何间隔最大化
表示为以下的优化问题
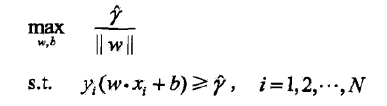
每一个训练样本的几何间隔至少是γ
函数间隔γ^取值不影响问题的解,故γ^取1
max(1/w) 可转化成 min(1/2*w^2)
算法描述

对偶问题
优点
对偶问题往往更容易求解
自然引入核函数,进而可推广到非线性分类问题
算法描述

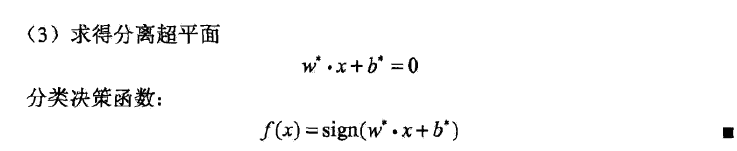
KKT条件


线性支持向量机与软间隔最大化
近似线性可分:即大部分数据还是线性可分的,只有在一些特异点无法分开
解决方法:对每个样本点引入一个松弛变量
目标问题变成:
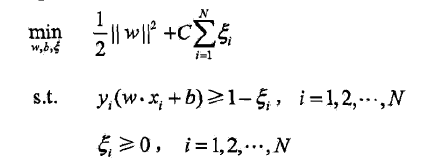
对偶问题
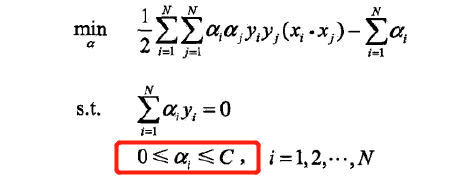
对偶形式
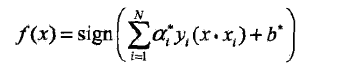
软间隔的对偶问题和对偶形式与硬间隔的基本类似
非线性支持向量机与核函数
线性不可分解决思路:
首先使用一个变换将原空间的数据映射到新空间,然后在新空间里用线性分类学习方法从训练数据中学习分类模型
一个简单粗暴的映射方法是将每个多项式抽象成一个维度,这样会导致维度爆炸问题
这时候就要引入核函数,核函数“刚好”能产生前一种相同的多项式结果
对偶问题的目标函数变成:
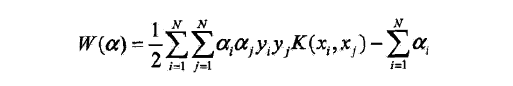
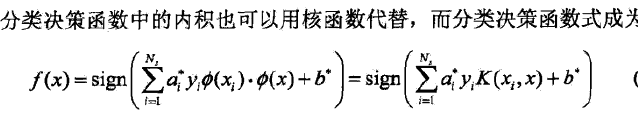
核函数神奇在于
不需要先计算映射到高维空间后的值,再两两做内积,而是可以直接计算出高维空间的内积值
可以预先在低维的空间进行计算,而将实质上的分类效果表现在高维上,即避免了在高维上做运算
核函数的选取需要凭经验选取
常用核函数

3.字符串核函数
核函数不仅可以定义在欧氏空间上,还可以定义在离散数据上。字符串核是定义在字符串集合上的核函数,字符串核函数在文本分类、信息检索、生物信息学方面都有应用…..
算法描述

序列最小最优化算法(SMO)
SMO是一种实现SVM 的算法,由于求解SVM涉及的是一个优化求解问题,所以需要一个算法来高效求解该问题……