统计学习方法_李航
因本人刚开始写博客,学识经验有限,如有不正之处望读者指正,不胜感激;也望借此平台留下学习笔记以温故而知新。这一篇文章介绍的是李航的统计学习方法一书的第一遍学习笔记。
统计学习方法概论
统计学习方法概论
统计学习的对象是数据,从数据出发,提取数据的特征, 抽象出数据的模型, 发现数据中的知识, 又回到对数据的分析与预测中去。
统计学习的目标是考虑学习什么样的模型和如何学习模型,以使模型能对数据进行准确的预测与分析,同时也要考虑尽可能地提高学习效率。
统计学习的组成:监督学习、非监督学习、半监督学习和强化学习等。
统计学习方法的三要素:模型、策略和算法.
学习或选择最优模型的预测错误的程度度量:通常采用损失函数或代价函数。
统计学习常用的损失函数:损失函数、平方损失函数、绝对损失函数、对数损失函数。
典型的生成模型:朴素贝叶斯法和隐马尔可夫模型。
典型的判别模型:k近邻法、感知机、决策树、逻辑斯谛回归模型、最大熵模型、支持向量机、提升方法和条件随机场等。
生成方法的特点: 生成方法可以还原出联合概率分布P(X,Y), 而判别别方法则不能。生成方法的学习收敛速度更快, 即当样本容量增加的时候, 学到的模型可以更快地收敛于真实模型;当存在隐变量时,仍可以用生成方法学习,此时判别方法就不能用。
判别方法的特点:判别方法直接学习的是条件概率 P(Y|X)或决策函数f(X),直接面对预测,往往学习的准确率更高;由于直接学习P(Y|X)或f(X),可以对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习问题。
实现统计学习方法的步骤如下:
(1)得到一个有限的训练数据集合;
(2)确定包含所有可能的模型的假设空间,即学习模型的集合;
(3)确定模型选择的准则,即学习的策略;
(4)实现求解最优模型的算法,即学习的算法;
(5)通过学习方法选择最优模型;
(6)利用学习的最优模型对新数掘进行预测或分析。
监督学习图示:

感知机学习算法

K近邻

K近邻模型由三个基本要素距离度量、k值的选择和分类决策规则决定。
距离度量:

K近邻法的实现:kd树
构造kd树


搜索kd树


朴素贝叶斯

决策树
决策树学习过程
• 特征选择
• 决策树生成:递归结构 ,对应于模型的局部最优
• 决策树剪枝:缩小树结构规模、缓解过拟合


ID3基于信息增益作为属性选择的度量


C4.5基于信息增益比作为属性选择的度量

逻辑回归模型

支持向量机


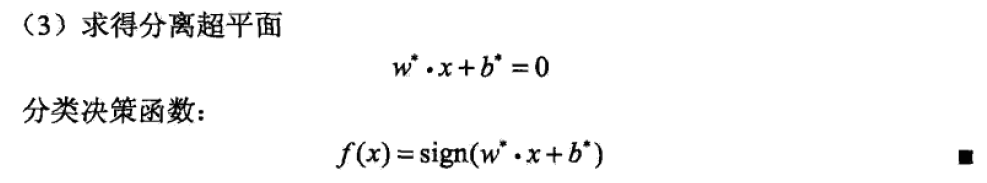
提升方法boosting
核心:多个弱分类器可以组成成为强分类器


EM算法
求期望,再求最大值



隐马尔可夫模型


参考文献
统计学习方法 李航