1、缺失值处理:删除、插补、不处理
2、离群点分析:简单统计量分析、3σ原则(数据服从正态分布)、箱型图(最好用)
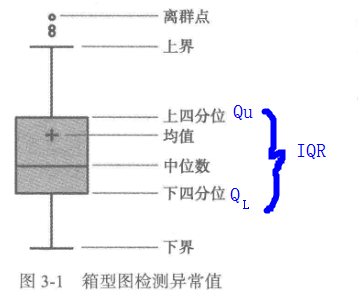
离群点(异常值)定义为小于QL-1.5IQR或大于Qu+1.5IQR
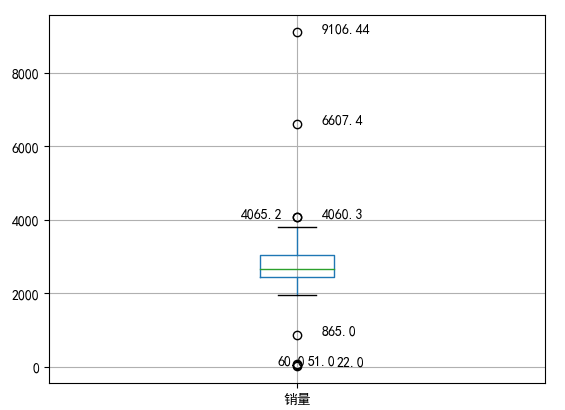
import pandas as pd catering_sale = '../data/catering_sale.xls' #餐饮数据 data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列 import matplotlib.pyplot as plt #导入图像库 #plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签 #plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 plt.figure() #建立图像 p = data.boxplot(return_type='dict') #画箱线图,直接使用DataFrame的方法 x = p['fliers'][0].get_xdata() # 'fliers'即为异常值的标签 y = p['fliers'][0].get_ydata() y.sort() #从小到大排序,该方法直接改变原对象 #用annotate添加注释 #其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制。 #以下参数都是经过调试的,需要具体问题具体调试。 for i in range(len(x)): if i>0: plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i])) else: plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i])) plt.show() #展示箱线图
3、贡献度分析(帕累托分析,20/80定律)
import pandas as pd import matplotlib.pyplot as plt #导入图像库 dish_profit = 'data/catering_dish_profit.xls' #餐饮菜品盈利数据 data = pd.read_excel(dish_profit, index_col = u'菜品名') data = data[u'盈利'].copy() data.sort_values(ascending = False) plt.figure() data.plot(kind='bar') plt.ylabel(u'盈利(元)') p = 1.0*data.cumsum()/data.sum() p.plot(color = 'r', secondary_y = True, style = '-o',linewidth = 2) plt.annotate(format(p[6], '.4%'), xy = (6, p[6]), xytext=(6*0.9, p[6]*0.9), arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2")) #添加注释,即85%处的标记。这里包括了指定箭头样式。 plt.ylabel(u'盈利(比例)') plt.show()

4、相关性分析(以餐饮数据为例)
导入数据

求相关系数的三种方式


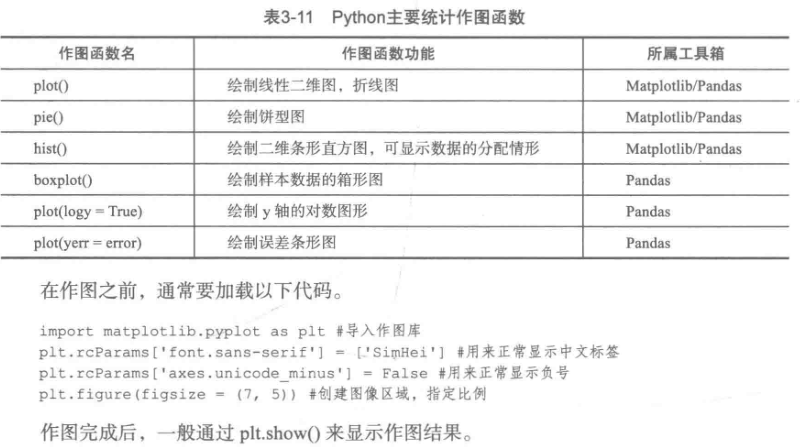
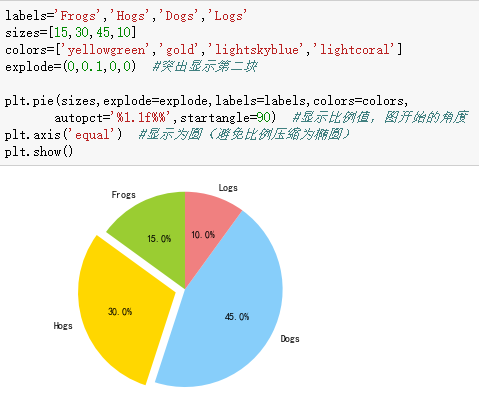
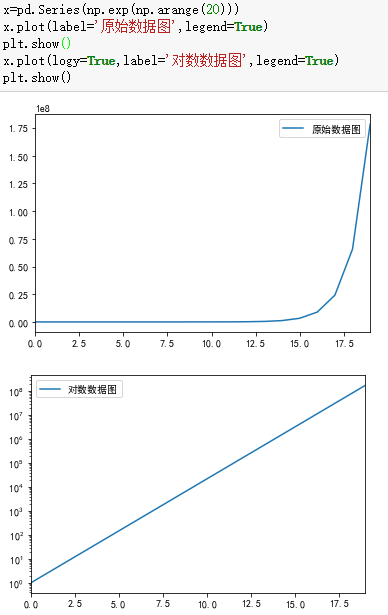
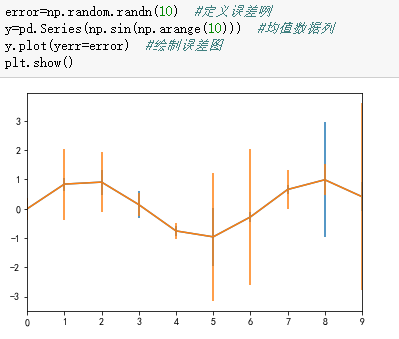
5、统计作图函数