本文是基于《Python数据分析与挖掘实战》的实战部分的第14章的数据——《基于基站定位数据的商圈分析》做的分析。
旨在补充原文中的细节代码,并给出文中涉及到的内容的完整代码。
在作者所给代码的基础上增加的内容包括:
1)探索了不同的method取值而画出的谱系聚类图的不同
1 挖掘背景及目标
从某通信运营商提供的特定接口解析得到用户的定位数据。利用基站小区的覆盖范围作为商圈区域的划分,归纳出商圈的人流特征和规律,识别出不同类别的商圈,选择合适的区域进行运营商的促销活动
实质——聚类
2 数据预处理
2.1 数据变换——标准化
# 离差标准化(最大最小规范化):保留了原来数据中存在的关系,消除量纲和数据取值范围影响最简单的方法
# 目标:消除数量级数据带来的影响,数据标准化到[0,1]
import pandas as pd
filename = 'business_circle.xls'
data = pd.read_excel(filename, index_col = u'基站编号')
data = (data - data.min()) / (data.max() - data.min()) # 离差标准化
data.to_excel('1_1standardization.xlsx')
3 建立模型
# 画谱系聚类图 import pandas as pd # 参数初始化 filename = '1_1standardization.xlsx' data = pd.read_excel(filename, index_col = u'基站编号') import matplotlib.pyplot as plt from scipy.cluster.hierarchy import linkage, dendrogram # 这里使用scipy的层次聚类函数method是指计算类间距离的方法:
比较常用的有3种:
(1)single:最近邻,把类与类间距离最近的作为类间距
(2)complete:最远邻,把类与类间距离最远的作为类间距
(3)average:平均距离,类与类间所有pairs距离的平均
z = linkage(data, method = 'weighted', metric = 'euclidean') # method = 'weighted'时的谱系聚类图 p = dendrogram(z, 0) # 画谱系聚类图 plt.show()
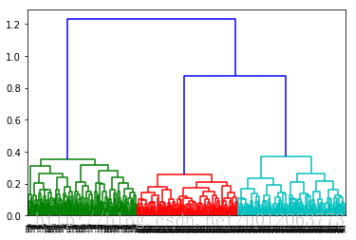
z = linkage(data, method = 'single', metric = 'euclidean') # method = 'single'谱系聚类图 p = dendrogram(z, 0) # 画谱系聚类图 plt.show()

z = linkage(data, method = 'complete', metric = 'euclidean') # method = 'complete'谱系聚类图 p = dendrogram(z, 0) # 画谱系聚类图 plt.show()
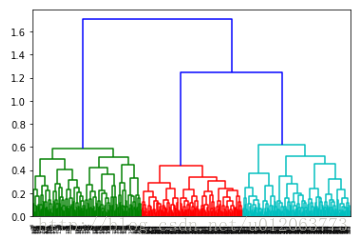
z = linkage(data, method = 'average', metric = 'euclidean') # method = 'average'谱系聚类图 p = dendrogram(z, 0) # 画谱系聚类图 plt.show()
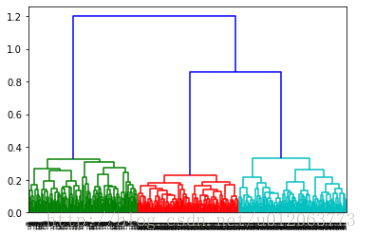
z = linkage(data, method = 'centroid', metric = 'euclidean') # method = 'centroid'谱系聚类图 p = dendrogram(z, 0) # 画谱系聚类图 plt.show()
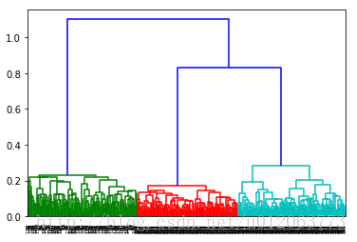
z = linkage(data, method = 'median', metric = 'euclidean') # method = 'median'谱系聚类图 p = dendrogram(z, 0) # 画谱系聚类图 plt.show()
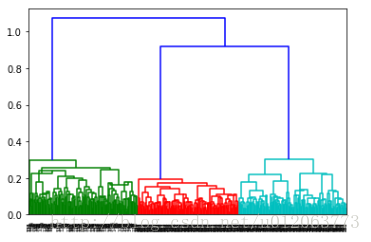
z = linkage(data, method = 'ward', metric = 'euclidean') # method = 'ward'谱系聚类图 # Ward方差最小化算法
p = dendrogram(z, 0) # 画谱系聚类图
plt.savefig('puxijulei.jpg')
plt.show()

由谱系聚类图可知,聚类类别为3类
k = 3 # 聚类数 from sklearn.cluster import AgglomerativeClustering # 导入sklearn的层次聚类函数 model = AgglomerativeClustering(n_clusters = k, linkage = 'ward') model.fit(data) # 训练模型
输出:
AgglomerativeClustering(affinity='euclidean', compute_full_tree='auto',
connectivity=None, linkage='ward', memory=None, n_clusters=3,
pooling_func=<function mean at 0x000000000627D908>)
# 详细输出原始数据及其类别
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) # 详细输出每个样本对应的类别
r.columns = list(data.columns) + [u'聚类类别'] # 重命名表名
import matplotlib.pyplot as plt
plt.rc('figure',figsize=(7,6))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
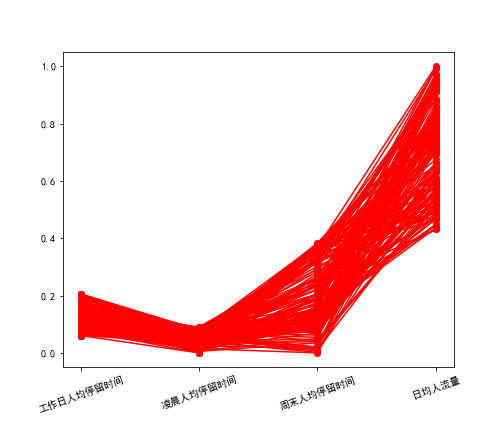
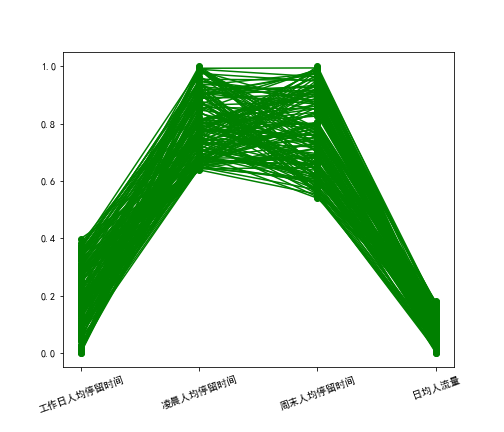
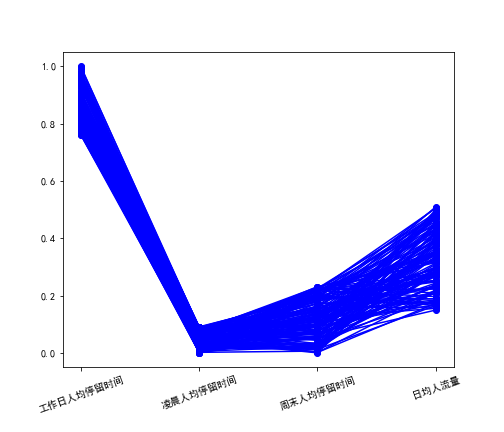
style = ['ro-', 'go-', 'bo-']
xlabels = [u'工作日人均停留时间', u'凌晨人均停留时间', u'周末人均停留时间', u'日均人流量']
pic_output = 'type_'
for i in range(k): # 逐一作图,作出不同样式
plt.figure()
tmp = r[r[u'聚类类别'] == i].iloc[:,:4] # 提取每一类
for j in range(len(tmp)):
plt.plot(range(1,5), tmp.iloc[j], style[i])
plt.xticks(range(1,5), xlabels, rotation = 20) # 坐标标签 (***)
plt.subplots_adjust(bottom=0.15) # 调整底部 (***)
plt.savefig(u'%s%s.png' % (pic_output, i)) # 保存图片
备注:本章节完整代码请见:点击打开链接