定量数据的分布分析
这就不用多说了,直方图。求极差--> 设定组距-->决定分点 --> 统计频率
定性数据的分布分析
这也不用多说了,扇形图,条形图统计法
对比分析
折线图
统计量分析
均值,中位数,极差,标准之类的就不说了,介绍一下变异系数,它是 标准差除以平均值 。反映了标准差相对于均值的离中趋势。数据:catering_sale.xls
#-*- coding:utf-8 -*-
import pandas as pd
# 餐饮数据
catering_sale = "wajue/catering_sale.xls"
# 读取数据,指定 "日期" 列为索引列
data = pd.read_excel(catering_sale,index_col = u"日期")
# 过滤数据
data = data[(data[u"销量"] > 400) & (data[u"销量"] < 5000)]
statistics = data.describe() # 利用里面的基本统计量计算
# 极差
statistics.loc["range"] = statistics.loc["max"] - statistics.loc["min"]
# 变异系数
statistics.loc["var"] = statistics.loc["std"] / statistics.loc["mean"]
# 四分数间距 IQR
statistics.loc["dis"] = statistics.loc["75%"] - statistics.loc["25%"]
print statistics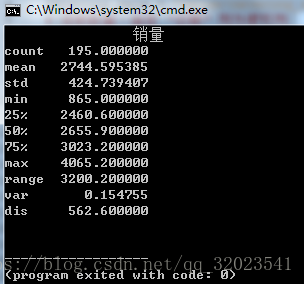
周期性分析
主要分析时间周期对数据的影响
贡献度分析
贡献度分析又称为 帕累托分析,它的原理是帕累托法则,又称 2/8 定律。例如,对一个公司来说,80% 的利润来自20% 最畅销的产品,而其他的 80% 的产品只产生了 20% 的利润。例如对餐饮菜品盈利数据 catering_dish_profit.xls 进行帕累托分析如下
#-*- coding:utf-8 -*-
import pandas as pd
# 餐饮菜品盈利数据
dish_profit = 'wajue/catering_dish_profit.xls'
data = pd.read_excel(dish_profit,index_col = u"菜品名")
# 获取盈利数据
data = data[u"盈利"].copy()
# 降序排序
data = data.sort_values(ascending = False)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure()
data.plot(kind = 'bar')
plt.ylabel(u"盈利(元)")
# cumsum 依次给出前 n 个数的和
p = 1.0*data.cumsum()/data.sum()
# 画出前 n 个和占总和比的曲线图
p.plot(color = "red",secondary_y = True,style = '-o',linewidth = 2)
# 添加标注,记录前 7 个菜品和的比例,保留4个小数
plt.annotate(format(p[6],'.4%'),xy = (6,p[6]),xytext = (6*0.9,p[6]*0.9), \
arrowprops = dict(arrowstyle = "->",connectionstyle = "arc3,rad = .2"))
plt.ylabel(u"盈利比例")
plt.show()
可以看到,前 7 种菜品的利润达到了总利润的 85.0033%
相关性分析
1.皮尔森(Pearson)相关系数。一般用于分析两个连续性变量之间的关系,计算公式如下

其中 r = [-1,1] ,r > 0正相关, r<0 负相关,越接近 0 越线性无关
2.斯皮尔曼(Spearman)相关系数
皮尔森相关系数要求连续变量的取值满足正态分布。不服从正态分布的变量之间的关联性可用斯皮尔曼相关系数表示。
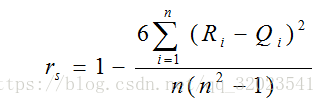
其中 Ri 和 Qi 分别代表两个变量的 秩次,所谓秩次,就是排序后所在位置的平均值。打个比方 x 从小到大排序(也可以从大到小)依次为 0.1 0.2 0.3 0.3 0.4 0.4 0.5 那么秩次就依次为 1 2 3.5 3.5 3.5 5.5 5.5 7,如图

只要两个变量具有严格单调的函数关系,那么他们就是完全斯皮尔曼相关。这与皮尔森系数不同,皮尔森系数只有在变量具有线性关系时才是完全相关的。也就是皮尔森系数是真正的线性关系。斯皮尔曼系数只是体现了单调相关性,即只能说明变量相关。
3.判定系数
判定系数就是相关系数的平方,用 r^2 表示,r^2 = [0,1] ,越接近1,表明 x 和 y 之间的相关性越强。
使用不同的菜品日销售数据 catering_sale_all.xls 判断相关性如下
#-*- coding:utf-8 -*-
import pandas as pd
# 不同菜品日销售量数据
catering_sale = 'wajue/catering_sale_all.xls'
data = pd.read_excel(catering_sale,index_col = u"日期")
''' 计算不同菜品的日销售量之间的相关性 '''
# 相关系数矩阵,即给出了任意两款菜品之间的相关系数
data.corr()
# 只显示 "百合酱蒸凤爪" 与其他菜品之间的相关系数
data.corr()[u"百合酱蒸凤爪"]
# 计算 "百合酱蒸凤爪" 和 "翡翠蒸香茜饺" 的相关系数
data[u"百合酱蒸凤爪"].corr(data[u"翡翠蒸香茜饺"])
print data.corr()