目录

当我们收集到数据后,接下来的问题便是对数据的质量和数量进行检查,看一看收集的数据是否满足之后的建模过程,这里我们从数据质量分析和数据特征分析数据进行探索。
一·数据质量分析
数据质量分析主要是检查我们收集到的数据是否有脏数据,所谓的脏数据就是指不符合要求或不能直接进行数据分析的数据。脏数据包括:缺失值,异常值,不一致的值,重复数据或者带有特殊符号(#,*,¥)的数据。
1.缺失值分析
数据的缺失值主要包括数据纪录的缺失或者每个信息的缺失。
缺失值的产生:1.有些数据无法获取或者获取数据的代价太大,我们不得不丢弃。2.数据被遗漏。3.属性值不存在
缺失值的影响:1.数据挖掘建模阶段将丢失大量有用的数据。2.建模后表现出来的不确定性更加显著。3.包含空值的数据会导致不可靠的输出
2.异常值分析
异常值分析是检验数据是否录入错误,是否有不合理的数据。异常值分析的方法有如下几个。
2.1 简单统计量分析
简单统计量分析就是对变量进行一个描述性的统计,然后看看数据是否在我们的认知中合理,统计量常见的有最大值和最小值。
2.2 3 原则
原则
然后数据服从正态分布,我们就可以用这个原则检查数据是否是异常值,在一个原则下,异常值被定义为一组测定值中与平均值的偏差超过3倍标准差的值
2.3 箱型图分析
箱型图判断异常值的标准一四分位数和四分位距离为基础,四分位数具有一定的鲁棒性,什么是鲁棒性呢?就是25%的数据可以变得任意远而不会严重扰动四分位数,所有异常值不能对这个标准施加影响。

在python中读入数据后,可以用pandas库的describe()方法查看数据,例如:
import pandas as pd
catering_sale = 'catering_sale.xls'
data=pd.read_excel(catering_sale,index_col='日期')
print(data.describe())
print(len(data))
"""
销量
count 200.000000
mean 2755.214700
std 751.029772
min 22.000000
25% 2451.975000
50% 2655.850000
75% 3026.125000
max 9106.440000
201
"""输出后可以看到,count的数值比data的纪录少了一个,这个就是缺失值个数。其中mean表示平均数,std表示标准差,min表示最小值,max表示最大值,这些都可以帮助我们查看数据的信息,如果想更直观地表示数据或检查异常值也可以使用箱型图:
import pandas as pd
catering_sale = 'catering_sale.xls'
data = pd.read_excel(catering_sale, index_col = u'日期') # 读取数据,指定“日期”列为索引列
import matplotlib.pyplot as plt # 导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure() # 建立图像
p = data.boxplot(return_type='dict') # 画箱线图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() # 从小到大排序,该方法直接改变原对象
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() # 展示箱线图
如箱型图,超过上下界的7个销售额数据就可能为异常值了
2.4 一致性分析
数据的不一致性指数据的矛盾性,不相容性,直接对不一致性的数据进行挖掘,很可能会产生和实际相违背的结果
3.数据特征分析
分析数据质量后,我们就可以通过绘制图表,计算某些特征对数据进行特征分析
3.1分布分析
分布分析能揭示数据的分布特征和分布类型,分布分析的数据主要分为定量数据和定性数据
1.定量数据的分布分析
对于定量数据的分布分析,我们一般通过频率分布来分析,进行步骤:
求极差,决定组距和组数,决定分点,列出频率分布图,绘制频率直方图
这里我们看看绘制频率直方图:

import pandas as pd
catering_sale = 'catering_fish_congee.xls'
data = pd.read_excel(catering_sale, names=['date', 'sale']) # 读取数据,指定“日期”列为索引
import matplotlib.pyplot as plt
d = 500 # 设置组距
num_bins = round((max(data['sale']) - min(data['sale'])) / d) # 计算组数
plt.figure(figsize=(10, 6)) # 设置图框大小尺寸
plt.hist(data['sale'], num_bins)
plt.xticks(range(0, 4000, d))
plt.xlabel('sale分层')
plt.grid()
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('季度销售额频率分布直方图', fontsize=20)
plt.show()
2.定性数据分析
定性数据通常使用饼图或者条形图来描述定性变量的分布,例如:


import pandas as pd
import matplotlib.pyplot as plt
catering_dish_profit = 'catering_dish_profit.xls'
data = pd.read_excel(catering_dish_profit) # 读取数据,指定“日期”列为索引
# 绘制饼图
x = data['盈利']
labels = data['菜品名']
plt.figure(figsize = (8, 6)) # 设置画布大小
plt.pie(x,labels=labels) # 绘制饼图
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.title('菜品销售量分布(饼图)') # 设置标题
plt.axis('equal')
plt.show()
# 绘制条形图
x = data['菜品名']
y = data['盈利']
plt.figure(figsize = (8, 4)) # 设置画布大小
plt.bar(x,y)
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.xlabel('菜品') # 设置x轴标题
plt.ylabel('销量') # 设置y轴标题
plt.title('菜品销售量分布(条形图)') # 设置标题
plt.show() # 展示图片
3.2对比分析
对比分析是把两个互相联系的指标进行对比,从数量上展示和说明研究对象的规模大小,水平的高低,对比分析主要有这几种形式:
1.绝对数比较
利用绝对数进行比较
2.相对数比较
通过两个相联系的数据进行比较,相对数比较可分为:结构相对数,比例相对数,比较相对数,强度相对数,计划完成程度相对数,动态相对数。例如:
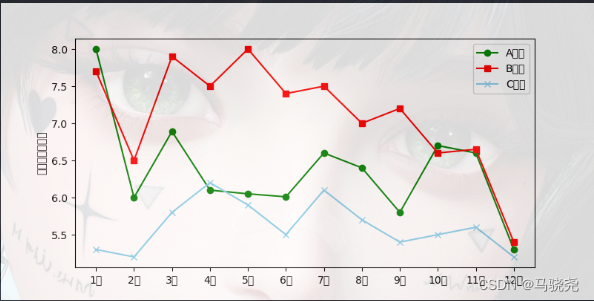
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_excel("dish_sale.xls")
plt.figure(figsize=(8, 4))
plt.plot(data['月份'], data['A部门'], color='green', label='A部门',marker='o')
plt.plot(data['月份'], data['B部门'], color='red', label='B部门',marker='s')
plt.plot(data['月份'], data['C部门'], color='skyblue', label='C部门',marker='x')
plt.legend() # 显示图例
plt.ylabel('销售额(万元)')
plt.show()
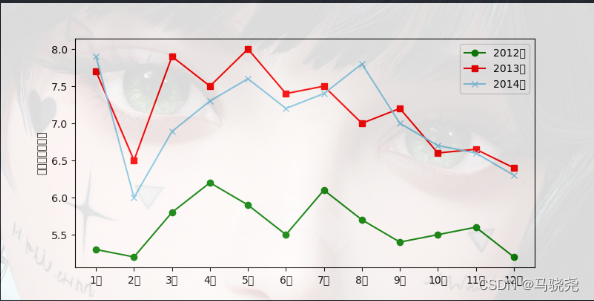
# B部门各年份之间销售金额的比较
data=pd.read_excel("dish_sale_b.xls")
plt.figure(figsize=(8, 4))
plt.plot(data['月份'], data['2012年'], color='green', label='2012年',marker='o')
plt.plot(data['月份'], data['2013年'], color='red', label='2013年',marker='s')
plt.plot(data['月份'], data['2014年'], color='skyblue', label='2014年',marker='x')
plt.legend() # 显示图例
plt.ylabel('销售额(万元)')
plt.show()3.3统计量分析
统计量分析指对定量数据进行统计,常从集中趋势和离中趋势两个方面进行分析
1.集中趋势度量
集中趋势度量主要分析均值,中位数,众数
离中趋势度量主要分析极差,标准差,变异系数,四分位数间距
3.4周期性分析
周期性分析是探索某个变量是否随着时间变化而呈现出来某种周期性变化趋势
3.5贡献度分析
贡献度分析又称帕累托法则,又称2/8法则,即同样的投入放找不同的地方会产生不同的效益
3.6性关系分析
分析连续变量之间线性相关程度的强弱,并用适当的统计指定表示出来的过程称为相关分析,常见的相关性分析方法有:
1.直接绘制散点图 2.绘制散点图矩阵 3.计算相关系数(Pearson系数,Spearman系数,判断系数)