1 - 引言
GoogLeNet, 在2014年ILSVRC挑战赛获得冠军,将Top5 的错误率降低到6.67%. 一个22层的深度网络
论文地址:http://arxiv.org/pdf/1409.4842v1.pdf
题目为:Going deeper with convolutions。
GoogLeNet这个名字也是挺有意思的,为了像开山鼻祖的LeNet网络致敬,他们选择了这样的名字。
之前我们介绍的网络模型都是通过卷积层和池化层的“串联”来构建的。
而GoogLeNet结构创新之处在于:
GoogLeNet 模型中的Inception结构是将不同的卷积层通过“并联”的方式结合在一起。
Inception结构如下图所示:
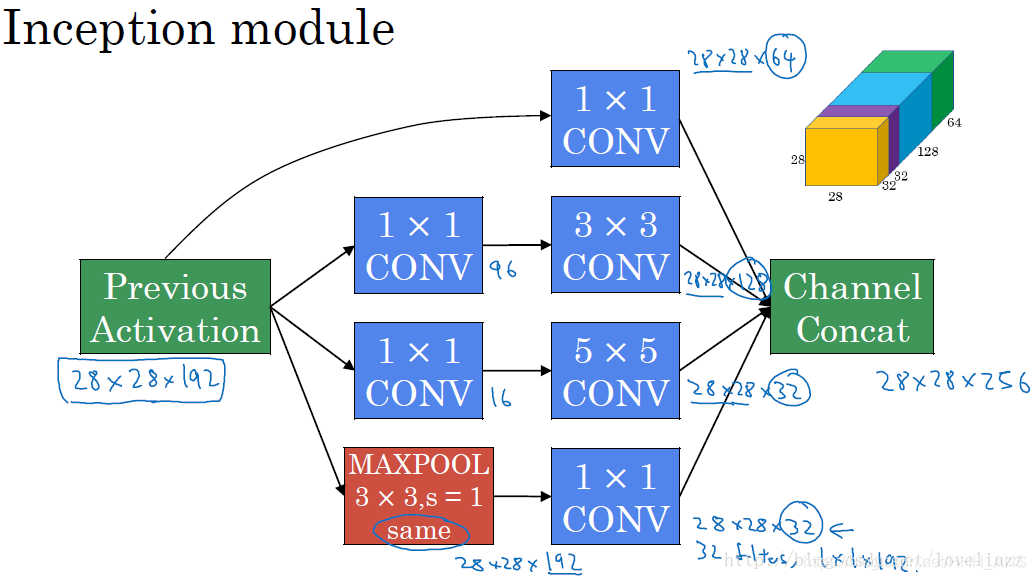
在GoogLeNet出来之前,主流的网络结构突破大致是网络更深(即层数增加),网络更宽(即神经元数目增多),但这样做存在一些缺点:
- 当训练集有限时,参数过多,模型会出现过拟合;
- 网络越大,计算复杂度越大,设计起来越困难;
- 当层数增多时,梯度越往后越容易消失;
针对上述缺点,我们考虑到一味的追求准确率而增加网络规模有一部分原因就是特征提取模块的设计没有能很好提取出图像的特征,如果能在基本的特征提取单元上做一些优化,然后用优化后的特征提取模块去构建网络,可能会有利于最后的识别效果。由此,Inception 模型孕育而生。
下面我们着重介绍一下GoogLeNet中的Inception -v3模型
2 - Inception -v3模型
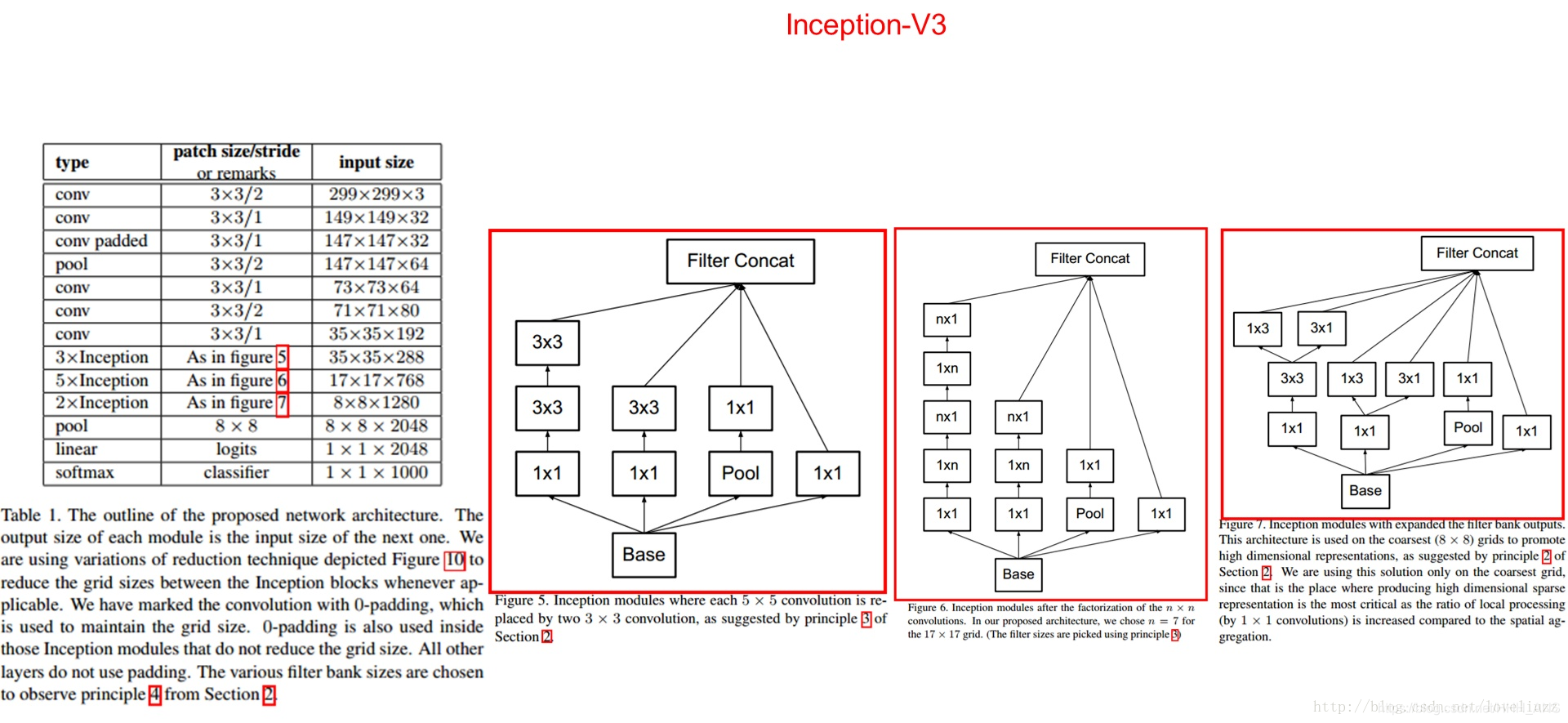

Inception-v3模型总共有46层,有11个Inception模块组成。而且有96个卷积层,如果用之前的TensorFlow程序来编写,一个卷积层需要5行代码,那么总共就需要480行代码来实现所有的卷积层。这样使得代码的可读性非常差。于是,为了实现这种复杂的卷积神经网络。
TensorFlow又推出了一款叫TensorFlow-Slim工具来更加简洁地实现一个卷积网络
3 - TensorFlow-Slim工具
slim是一个使构建,训练,评估神经网络变得简单的库。它可以消除原生tensorflow里面很多重复的模板性的代码,让代码更紧凑,更具备可读性。另外slim提供了很多计算机视觉方面的著名模型(VGG, AlexNet等),我们不仅可以直接使用,甚至能以各种方式进行扩展。
4 - Inception-v3卷积层实现
因为Inception-v3是一个比较复杂的神经网络结构在这里只给出卷积部分的实现代码:
########定义函数可以生成Inception V3网络的卷积部分########
def inception_v3_base(inputs, scope=None):
'''
Args:
inputs:输入的tensor
scope:包含了函数默认参数的环境
'''
end_points = {} # 定义一个字典表保存某些关键节点供之后使用
with tf.variable_scope(scope, 'InceptionV3', [inputs]):
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d], # 对三个参数设置默认值
stride=1, padding='VALID'):
# 正式定义Inception V3的网络结构。首先是前面的非Inception Module的卷积层
# 299 x 299 x 3
# 第一个参数为输入的tensor,第二个是输出的通道数,卷积核尺寸,步长stride,padding模式
net = slim.conv2d(inputs, 32, [3, 3], stride=2, scope='Conv2d_1a_3x3') # 直接使用slim.conv2d创建卷积层
# 149 x 149 x 32
'''
因为使用了slim以及slim.arg_scope,我们一行代码就可以定义好一个卷积层
相比AlexNet使用好几行代码定义一个卷积层,或是VGGNet中专门写一个函数定义卷积层,都更加方便
'''
net = slim.conv2d(net, 32, [3, 3], scope='Conv2d_2a_3x3')
# 147 x 147 x 32
net = slim.conv2d(net, 64, [3, 3], padding='SAME', scope='Conv2d_2b_3x3')
# 147 x 147 x 64
net = slim.max_pool2d(net, [3, 3], stride=2, scope='MaxPool_3a_3x3')
# 73 x 73 x 64
net = slim.conv2d(net, 80, [1, 1], scope='Conv2d_3b_1x1')
# 73 x 73 x 80.
net = slim.conv2d(net, 192, [3, 3], scope='Conv2d_4a_3x3')
# 71 x 71 x 192.
net = slim.max_pool2d(net, [3, 3], stride=2, scope='MaxPool_5a_3x3')
# 35 x 35 x 192.
# 上面部分代码一共有5个卷积层,2个池化层,实现了对图片数据的尺寸压缩,并对图片特征进行了抽象
'''
三个连续的Inception模块组,三个Inception模块组中各自分别有多个Inception Module,这部分是Inception Module V3
的精华所在。每个Inception模块组内部的几个Inception Mdoule结构非常相似,但是存在一些细节的不同
'''
# Inception blocks
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d], # 设置所有模块组的默认参数
stride=1, padding='SAME'): # 将所有卷积层、最大池化、平均池化层步长都设置为1
# mixed: 35 x 35 x 256.
# 第一个模块组包含了三个结构类似的Inception Module
with tf.variable_scope('Mixed_5b'): # 第一个Inception Module名称。Inception Module有四个分支
with tf.variable_scope('Branch_0'): # 第一个分支64通道的1*1卷积
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'): # 第二个分支48通道1*1卷积,链接一个64通道的5*5卷积
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv2d_0b_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'): # 第四个分支为3*3的平均池化,连接32通道的1*1卷积
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 32, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3) # 将四个分支的输出合并在一起(第三个维度合并,即输出通道上合并)
'''
因为这里所有层步长均为1,并且padding模式为SAME,所以图片尺寸不会缩小,但是通道数增加了。四个分支通道数之和
64+64+96+32=256,最终输出的tensor的图片尺寸为35*35*256。
第一个模块组所有Inception Module输出图片尺寸都是35*35,但是后两个输出通道数会发生变化。
'''
# mixed_1: 35 x 35 x 288.
with tf.variable_scope('Mixed_5c'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0b_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv_1_0c_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_2: 35 x 35 x 288.
with tf.variable_scope('Mixed_5d'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv2d_0b_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# 第二个Inception模块组。第二个到第五个Inception Module结构相似。
# mixed_3: 17 x 17 x 768.
with tf.variable_scope('Mixed_6a'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 384, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_1x1') # 图片会被压缩
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_1x1') # 图片被压缩
with tf.variable_scope('Branch_2'):
branch_2 = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID',
scope='MaxPool_1a_3x3')
net = tf.concat([branch_0, branch_1, branch_2], 3) # 输出尺寸定格在17 x 17 x 768
# mixed4: 17 x 17 x 768.
with tf.variable_scope('Mixed_6b'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 128, [1, 7], scope='Conv2d_0b_1x7') # 串联1*7卷积和7*1卷积合成7*7卷积,减少了参数,减轻了过拟合
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1') # 反复将7*7卷积拆分
branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 128, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_5: 17 x 17 x 768.
with tf.variable_scope('Mixed_6c'):
with tf.variable_scope('Branch_0'):
'''
我们的网络每经过一个inception module,即使输出尺寸不变,但是特征都相当于被重新精炼了一遍,
其中丰富的卷积和非线性化对提升网络性能帮助很大。
'''
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_6: 17 x 17 x 768.
with tf.variable_scope('Mixed_6d'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_7: 17 x 17 x 768.
with tf.variable_scope('Mixed_6e'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
end_points['Mixed_6e'] = net # 将Mixed_6e存储于end_points中,作为Auxiliary Classifier辅助模型的分类
# 第三个inception模块组包含了三个inception module
# mixed_8: 8 x 8 x 1280.
with tf.variable_scope('Mixed_7a'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_0 = slim.conv2d(branch_0, 320, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_3x3') # 压缩图片
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
branch_1 = slim.conv2d(branch_1, 192, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_2'): # 池化层不会对输出通道数产生改变
branch_2 = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID',
scope='MaxPool_1a_3x3')
net = tf.concat([branch_0, branch_1, branch_2], 3) # 输出图片尺寸被缩小,通道数增加,tensor的总size在持续下降中
# mixed_9: 8 x 8 x 2048.
with tf.variable_scope('Mixed_7b'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 320, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 384, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = tf.concat([
slim.conv2d(branch_1, 384, [1, 3], scope='Conv2d_0b_1x3'),
slim.conv2d(branch_1, 384, [3, 1], scope='Conv2d_0b_3x1')], 3)
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 448, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(
branch_2, 384, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = tf.concat([
slim.conv2d(branch_2, 384, [1, 3], scope='Conv2d_0c_1x3'),
slim.conv2d(branch_2, 384, [3, 1], scope='Conv2d_0d_3x1')], 3)
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(
branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3) # 输出通道数增加到2048
# mixed_10: 8 x 8 x 2048.
with tf.variable_scope('Mixed_7c'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 320, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 384, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = tf.concat([
slim.conv2d(branch_1, 384, [1, 3], scope='Conv2d_0b_1x3'),
slim.conv2d(branch_1, 384, [3, 1], scope='Conv2d_0c_3x1')], 3)
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 448, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(
branch_2, 384, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = tf.concat([
slim.conv2d(branch_2, 384, [1, 3], scope='Conv2d_0c_1x3'),
slim.conv2d(branch_2, 384, [3, 1], scope='Conv2d_0d_3x1')], 3)
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(
branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
return net, end_points
#Inception V3网络的核心部分,即卷积层部分就完成了
'''
设计inception net的重要原则是图片尺寸不断缩小,inception模块组的目的都是将空间结构简化,同时将空间信息转化为
高阶抽象的特征信息,即将空间维度转为通道的维度。降低了计算量。Inception Module是通过组合比较简单的特征
抽象(分支1)、比较比较复杂的特征抽象(分支2和分支3)和一个简化结构的池化层(分支4),一共四种不同程度的
特征抽象和变换来有选择地保留不同层次的高阶特征,这样最大程度地丰富网络的表达能力。
'''