系列博客是博主学习神经网络中相关的笔记和一些个人理解,仅为作者记录笔记之用,不免有很多细节不对之处。
这一节我们来学习下经典的卷积神经网络-ResNet。ResNet在2015年比赛中一举获得了 ImageNet分类、ImageNet 检测、ImageNet 定位、COCO 检测、COCO 定位的五个项目的冠军。而且 Deep Residual Learning for Image Recognition 也获得了 CVPR2016 的 best paper,实在是实至名归。要学习 ResNet,下面这 两篇论文是必须要研读的:
* Deep Residual Learning for Image Recognition
* Identity Mappings in Deep Residual Networks
网络退化问题
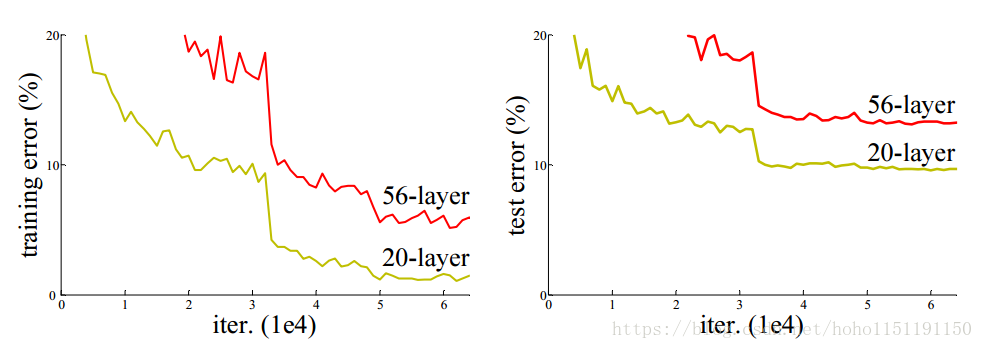
ResNet 最初的灵感来自于这样的问题:我们的直观认识网络的深度对其性能非常重要,即随着网络深度的不断增加,它的准确度应该不断提高。但是,在不断加深网络深度的时候,网络会出现退化(degradtion)的问题,即准确率会先上升然后达到饱和,再持续增加深度则会导致准确率下降。这个问题并不是由于过拟合产生的,如下图所示,CIFAR10数据的一个实验,左侧为训练误差,右侧为测试误差,不光在测试集上误差比较大,训练集本身的误差也非常大。
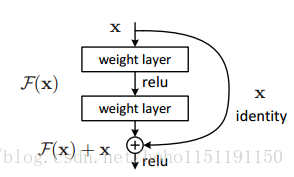
假设有一个比较浅网络的准确率达到饱和,那么后面再加上几个 的恒等映射(Identity Mappings),按理说,即使准确率不能再提升了,起码误差不会增加,但实验证明准确率下降了,这说明网络越深训练难度越大。
残差结构
假设我们现在要训练网络去逼近 的映射,实现方法有两种:
- 方法1: 按照常规的网络模式,在没有任何约束的情况下,让非线性单元(包含多个层)去学习出恒等映射;
- 方法2:增加一个约束,告诉网络 ,这样我们只需要让这个扰动 趋于零即可。
显然第二种方式更容易达到我们的目的,相当于我们已经告诉了它一些提示(告诉它这可能是一个恒等映射),而方法1则需要网络在无穷的函数中寻找这个映射关系。 我认为既可以称为残差(Residual),也可以称为扰动(Perturbation)。
在 ResNet 之前,瑞士教授 Schmidhuber (LSTM 的提出者)早就提出了 Highway Network,原理与 ResNet 相似。 Highway Network 的目标就是要解决极深网络的训练问题。Highway Network 相当于修改了每一层的激活函数,此前的激活函数会对输入做一个非线性映射,Highway Network 则允许保留一定比例的输入直接传输到下一层,仿佛高速公路。Highway Network 中有一个门单元(gating unit)学习如何控制网络中的信息流。
残差网络之所以能训练极深网络的原因在于 中的 ,它 可以直接将输出层的误差传递到任意层,如下:
shortcut 连接
ResNet 的恒等映射是通过 shortcut 连接实现的,shortcut 近路捷径原意为近路捷径,可以形象地理解为:输入信号抄小路传输到输出端。
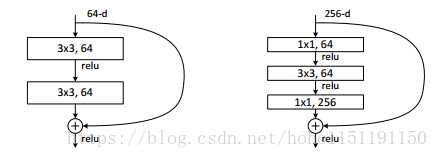
《Residual Learning for Image Recognition》论文中给出了两种构造单元(building block)左侧为浅网络所设计,实现流程为:Conv2D-BN-ReLU-Conv2D-BN-ADD-ReLU;右侧为深网络设计,右侧网络先利用 1x1 卷积进行降维,然后再利用 1x1 卷积进行升维。
由于
和
需要进行元素相加,当
和
维数相同时可以直接相加,在
和
维数不同时,可以在 shortcut 路径上可以加上一个 1x1 的卷积层,进行维数调节。
Keras实现
程序参考自 Keras 中的 example 例子:
关键函数 resnet_layer,resnet_layer返回一个卷积层,或跟着 BN层,或跟着 ReLU 激活函数:
def resnet_layer(inputs,
num_filters=16,
kernel_size=3,
strides=1,
activation='relu',
batch_normalization=True):
conv = Conv2D(num_filters,
kernel_size=kernel_size,
strides=strides,
padding='same',
kernel_initializer='he_normal',
kernel_regularizer=l2(1e-4))
x = inputs
x = conv(x)
if batch_normalization:
x = BatchNormalization()(x)
if activation is not None:
x = Activation(activation)(x)
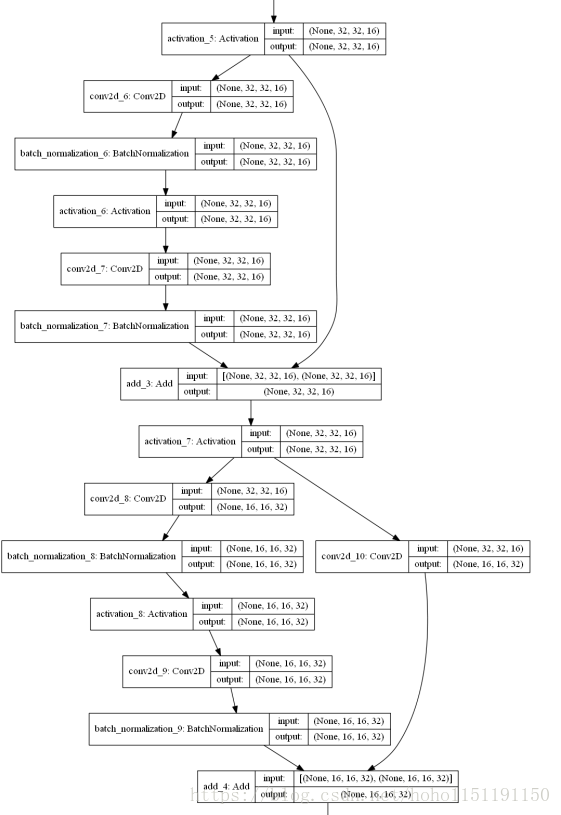
return x关键代码-网络结构定义:
def resnet_v1(input_shape, depth, num_classes=10):
""" 堆叠 2 x (3 x 3) Conv2D-BN-ReLU 结构,最后一个 ReLU 在shortcut 连接后
在每个 stage 开头,feature map 大小变为原来的一半,需要用 1x1 的卷积层进行维度调整
feature map 大小:
stage 0: 32x32, 16
stage 1: 16x16, 32
stage 2: 8x8, 64
"""
if (depth - 2) % 6 != 0:
raise ValueError('depth should be 6n+2 (eg 20, 32, 44 in [a])')
# Start model definition.
num_filters = 16
num_res_blocks = int((depth - 2) / 6)
inputs = Input(shape=input_shape)
# 第一个卷积层,Conv2d-BN-ReLU
x = resnet_layer(inputs=inputs)
for stack in range(3):
for res_block in range(num_res_blocks):
strides = 1
# 从第二个stack开始,第一个layer进行下采样
if stack > 0 and res_block == 0:
strides = 2 # 下采样
y = resnet_layer(inputs=x,
num_filters=num_filters,
strides=strides)
y = resnet_layer(inputs=y,
num_filters=num_filters,
activation=None)
# 从第二个stack开始,第一个layer进行下采样,为了保持 x 和 f(x) 相同的维度进行
# 1 x 1 的卷积操作
if stack > 0 and res_block == 0:
x = resnet_layer(inputs=x,
num_filters=num_filters,
kernel_size=1,
strides=strides,
activation=None,
batch_normalization=False)
x = keras.layers.add([x, y])
x = Activation('relu')(x)
num_filters *= 2
# 添加全局池化
x = AveragePooling2D(pool_size=8)(x)
y = Flatten()(x)
outputs = Dense(num_classes,
activation='softmax',
kernel_initializer='he_normal')(y)
model = Model(inputs=inputs, outputs=outputs)
return mode部分网络结构:上部为不变维数的结构,下部是利用1x1进行维数调整的结构
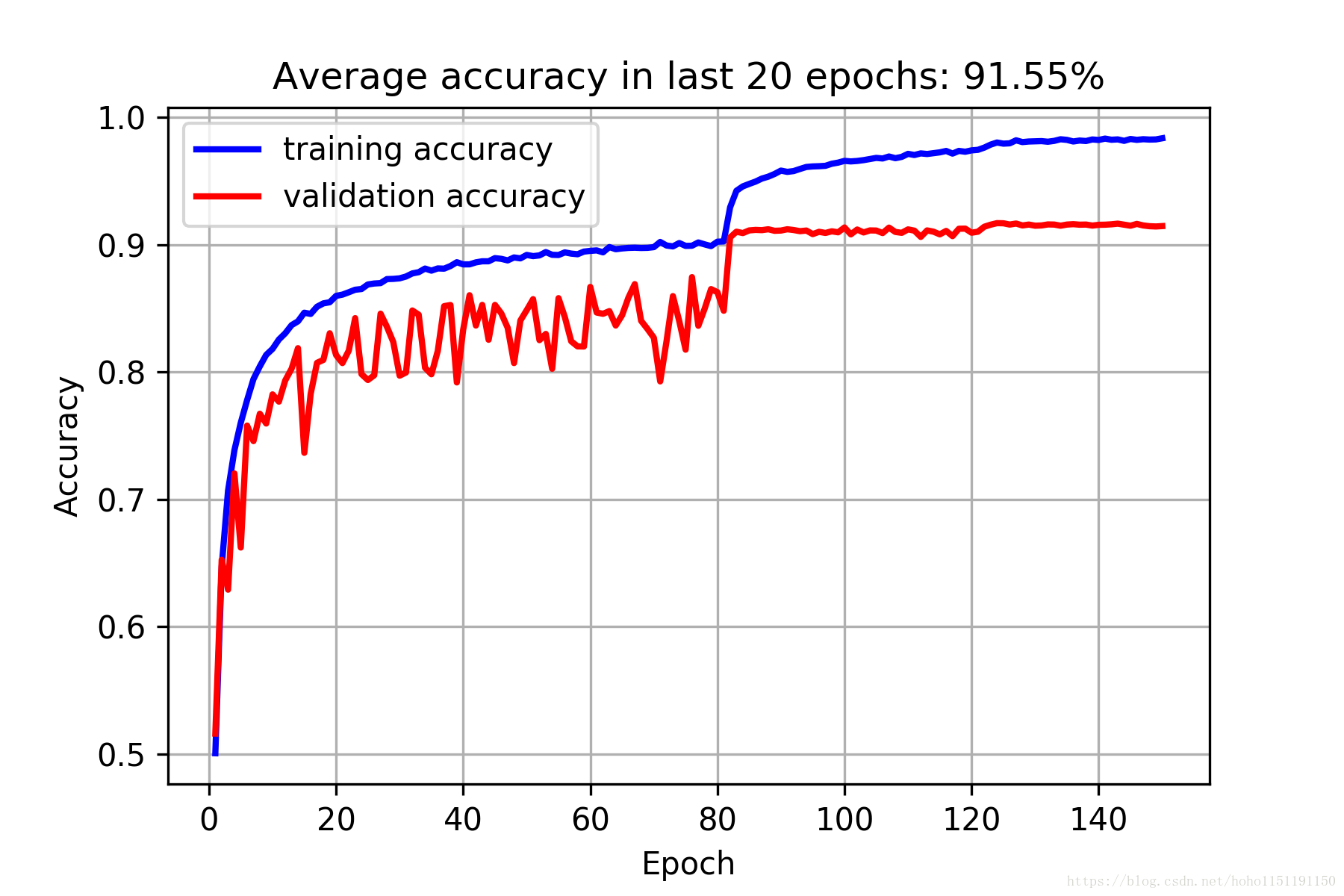
测试数据准确率为91.45%,下面是训练结果: