目录
1. \(O\left ( N^2 \right )\)
- 选择排序
- 冒泡排序
2. \(O\left (N \log N \right )\)(重点)
- 归并排序
- 快速排序
- 堆排序
3.\(O \left ( N \right )\)(重点)
- 桶排
一、 \(O\left ( N^2 \right )\)
\(\left ( 1\right )\)选择排序(不稳定)
1.原理:判断这个数以后的所有数,将小的放在前面,如果没有,就swap(挖坑)
2.考点:复赛基本不用,初赛要考
3.关键代码:
for(int i=1;i<=N;i++)
{
for(int j=i+1;j<=N;j++)
{
if(a[i]>a[j])
{
swap(a[i],a[j]);
}
}
} 4.时间复杂度:
最好情况: \(O\left ( N \right )\)
最坏情况: \(O\left ( N^2 \right )\)
平均情况: \(O\left ( N^2 \right )\)

***
\(\left ( 2\right )\) 冒泡排序(不稳定)
1.原理:比较相邻的元素,将小的放在前面
2.考点:初赛重点
3.关键代码:(初始代码)
for(int i=1;i<=N;i++)
{
for(int j=1;j<=N-i;j++)
{
if(a[j]>a[j+1])
{
swap(a[j],a[j+1]);
}
}
}还可以优化一下,当发现没有交换,就跳出循环
bool flag = true;
int k = n;
while(flag)
{
flag = false;
for(int i=1;i<=k;i++)
{
if(a[i]>a[i+1])
{
swap(a[i],a[i+1]);
flag = true;
}
}
k--;
}4.时间复杂度
最好情况: \(O\left ( N \right )\)
最坏情况: \(O\left ( N^2 \right )\)
平均情况: \(O\left ( N^2 \right )\)

二、 \(O\left ( N\log N \right )\)
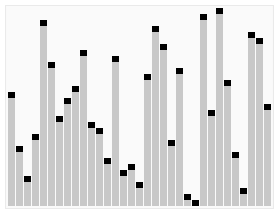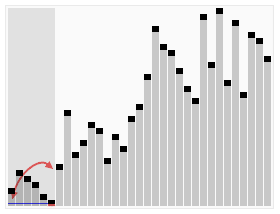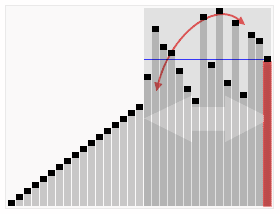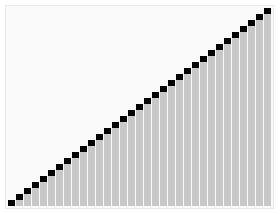
\(\left ( 1\right )\)快速排序(不稳定)
1.原理:冒泡排序的改进,用二分的思想进行优化
2.考点:几乎所有时候,快排都能过(除了卡快排的题 如P1309 瑞士轮||数据太大的题)
3.优化:三平均分区法
(以下摘自百度)
关于这一改进的最简单的描述大概是这样的:与一般的快速排序方法不同,它并不是选择待排数组的第一个数作为中轴,而是选用待排数组最左边、最右边和最中间的三个元素的中间值作为中轴。这一改进对于原来的快速排序算法来说,主要有两点优势:
①首先,它使得最坏情况发生的几率减小了。
②其次,未改进的快速排序算法为了防止比较时数组越界,在最后要设置一个哨点。
4.关键代码:
①STL自带函数
sort(a+1,a+n+1); //a为数组名(默认从小到大)可以配合cmp函数使用
bool cmp(int x,int y){return x>y;}//(从大到小cmp)结构体排序可以使用cmp函数,也可使用重载运算符
cmp
struct node
{
int id,v;
};
bool cmp(node x,node y)
{
if(x.v>y.v) return 1;
else if(x.id<y.id) return 1;
return 0;
}重载运算符
struct node
{
int id,v;
bool operator <(const node &n)const
{
if(v>n.v) return 1;
else if(id<n.id) return 1;
return 0;
}
};②自己写二分(不推荐,既然有了STL,还要什么二分)
(以下摘自Hardict大佬)
void swap(int arr[], int i, int j)
{
int temp;
temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
void QuickSort(int arr[], int left, int right)
{
int i, pivot;
if (left >= right)
return;
pivot = left;
swap(arr, left, (left + right) / 2);
for (i = left + 1; i <= right; i++) //单边搜索,可以该为双向搜索(据说快点( ° ▽、° ))
if (arr[i] < arr[left])
swap(arr, i, ++pivot);
swap(arr, left, pivot);
QuickSort(arr, left, pivot - 1);
QuickSort(arr, pivot + 1, right);
}5.时间复杂度:
最坏情况: \(O\left ( N^2 \right )\)
最好情况: \(O\left ( N\log N \right )\)
平均情况: \(O\left ( N\log N \right )\)
***
\(\left ( 2\right )\)归并排序(稳定)
1.原理:运用分治法,将两个数列合并,再将这两个数列分开
(以下转自MoreWindows大佬)
首先考虑下如何将将二个有序数列合并。这个非常简单,只要从比较二个数列的第一个数,谁小就先取谁,取了后就在对应数列中删除这个数。然后再进行比较,如果有数列为空,那直接将另一个数列的数据依次取出即可。
解决了上面的合并有序数列问题,再来看归并排序,其的基本思路就是将数组分成二组A,B,如果这二组组内的数据都是有序的,那么就可以很方便的将这二组数据进行排序。如何让这二组组内数据有序了?
可以将A,B组各自再分成二组。依次类推,当分出来的小组只有一个数据时,可以认为这个小组组内已经达到了有序,然后再合并相邻的二个小组就可以了。这样通过先递归的分解数列,再合并数列就完成了归并排序。
2.考点:在快排不能用时,就用它(如 P1309 瑞士轮)
3.关键代码
①STL实现
将两个数组合并放到第三个数组(其实是归并排序的一部分:并)
merge(w+1,w+1+wn,l+1,l+1+ln,p+1,cmp);//w为第一个数组,l为第二个数组,p为合并后放入的数组,wn,ln分别为w[],l[]的长度一个数组归并排序
int a[100000];
int mergesort(int l,int r)
{
if(l>=r) return 0;
int mid(l+r)/2;
mergesort(l,mid);
mergesort(mid+1,r);
inplace_merge(a+l,a+mid+1,a+r+1);//STL库自带函数
}
mergesort(a+1,a+n+1);//排序②手写归并排序(两个数组归并排序)
(以下同样摘自MoreWindows大佬)
//将有二个有序数列a[first...mid]和a[mid...last]合并。
void mergearray(int a[], int first, int mid, int last, int temp[])
{
int i = first, j = mid + 1;
int m = mid, n = last;
int k = 0;
while (i <= m && j <= n)
{
if (a[i] <= a[j])
temp[k++] = a[i++];
else
temp[k++] = a[j++];
}
while (i <= m)
temp[k++] = a[i++];
while (j <= n)
temp[k++] = a[j++];
for (i = 0; i < k; i++)
a[first + i] = temp[i];
}
void mergesort(int a[], int first, int last, int temp[])
{
if (first < last)
{
int mid = (first + last) / 2;
mergesort(a, first, mid, temp); //左边有序
mergesort(a, mid + 1, last, temp); //右边有序
mergearray(a, first, mid, last, temp); //再将二个有序数列合并
}
}
bool MergeSort(int a[], int n)
{
int *p = new int[n];
if (p == NULL)
return false;
mergesort(a, 0, n - 1, p);
delete[] p;
return true;
}4.时间复杂度
归并的归:\(O\left ( \log N \right )\)
归并的并:\(O\left ( N \right )\)
总时间复杂度:\(O\left ( N\log N \right )\)(基本稳定)

***
\(\left ( 3\right )\)堆排序(不稳定)
1.原理:利用了大根堆(或小根堆)的堆顶记录关键字最大(或最小)的特性,专门设计的一种排序,属于选排的一种(堆是一种完全二叉树)
(以下摘自百度)
用大根堆排序的基本思想
① 先将初始文件R[1..n]建成一个大根堆,此堆为初始的无序区
② 再将关键字最大的记录R[1](即堆顶)和无序区的最后一个记录R[n]交换,由此得到新的无序区R[1..n-1]和有序区R[n],且满足R[1..n-1].keys≤R[n].key
③由于交换后新的根R[1]可能违反堆性质,故应将当前无序区R[1..n-1]调整为堆。然后再次将R[1..n-1]中关键字最大的记录R[1]和该区间的最后一个记录R[n-1]交换,由此得到新的无序区R[1..n-2]和有序区R[n-1..n],且仍满足关系R[1..n-2].keys≤R[n-1..n].keys,同样要将R[1..n-2]调整为堆。
……
直到无序区只有一个元素为止。
2.考点:用于常数大的时候(Dijkstra,Prim时要用)如: P1843 奶牛晒衣服
3.关键代码:
①STL实现
优先队列(默认从大到小,如果需从小到大,需用结构体+重载运算符)
priority_queue<int>qu;
for(int i=1;i<=N;i++)
{
qu.push(a[i]);
}
for(int i=1;i<=N;i++)
{
a[i]=qu.front();
}小根堆实现(默认从大到小,如果需从小到大,需用结构体+重载运算符)//比优先队列快
struct node
{
int x;
bool operator <(const node &n)const
{
return x<n.x;
}
};
node heap[N];
int heaplen=0;
int pushHeap(int x)
{
heap[heaplen].x=x;
heaplen++;
push_heap(heap,heap+heaplen);
}
int popHeap()
{
pop_heap(heap,heap+heaplen);
heaplen--;
return heap[heaplen].x;
}
for(int i=1;i<=N;i++)
{
pushHeap(a[i]);
}
for(int i=1;i<=N;i++)
{
a[i]=popHeap();
}②自建堆(小根堆)
(以下摘自MoreWindows大佬)
堆的插入:
// 新加入i结点 其父结点为(i - 1) / 2
void MinHeapFixup(int a[], int i)
{
int j, temp;
temp = a[i];
j = (i - 1) / 2; //父结点
while (j >= 0 && i != 0)
{
if (a[j] <= temp)
break;
a[i] = a[j]; //把较大的子结点往下移动,替换它的子结点
i = j;
j = (i - 1) / 2;
}
a[i] = temp;
}
//在最小堆中加入新的数据nNum
void MinHeapAddNumber(int a[], int n, int nNum)
{
a[n] = nNum;
MinHeapFixup(a, n);
} 堆的删除:
// 从i节点开始调整,n为节点总数 从0开始计算 i节点的子节点为 2*i+1, 2*i+2
void MinHeapFixdown(int a[], int i, int n)
{
int j, temp;
temp = a[i];
j = 2 * i + 1;
while (j < n)
{
if (j + 1 < n && a[j + 1] < a[j]) //在左右孩子中找最小的
j++;
if (a[j] >= temp)
break;
a[i] = a[j]; //把较小的子结点往上移动,替换它的父结点
i = j;
j = 2 * i + 1;
}
a[i] = temp;
}
//在最小堆中删除数
void MinHeapDeleteNumber(int a[], int n)
{
Swap(a[0], a[n - 1]);
MinHeapFixdown(a, 0, n - 1);
}堆的建立、插入与删除图解
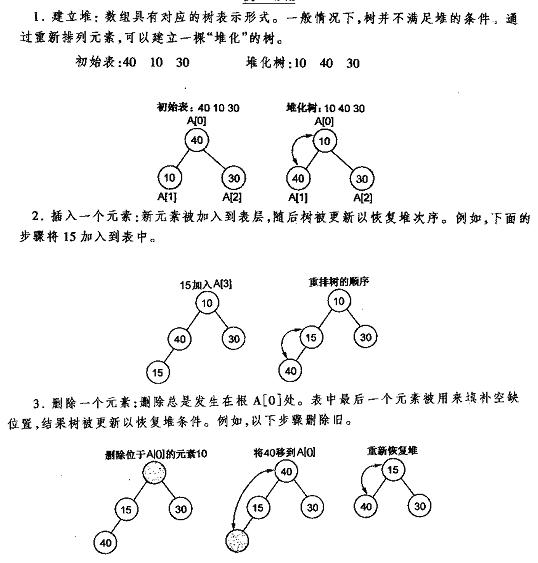
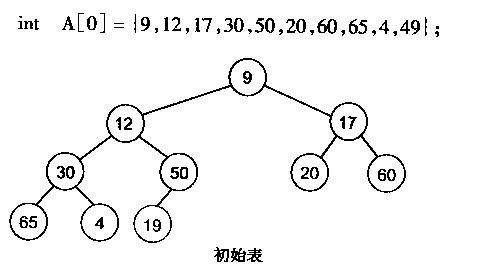
堆化数组代码及图解:
//建立最小堆
void MakeMinHeap(int a[], int n)
{
for (int i = n / 2 - 1; i >= 0; i--)
MinHeapFixdown(a, i, n);
}
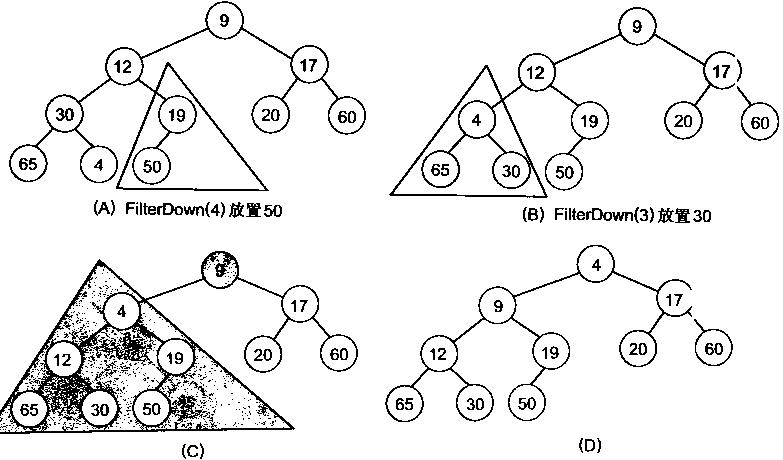
堆排序:
// 新加入i结点 其父结点为(i - 1) / 2
void MinHeapFixup(int a[], int i)
{
int j, temp;
temp = a[i];
j = (i - 1) / 2; //父结点
while (j >= 0 && i != 0)
{
if (a[j] <= temp)
break;
a[i] = a[j]; //把较大的子结点往下移动,替换它的子结点
i = j;
j = (i - 1) / 2;
}
a[i] = temp;
}
//在最小堆中加入新的数据nNum
void MinHeapAddNumber(int a[], int n, int nNum)
{
a[n] = nNum;
MinHeapFixup(a, n);
}
// 从i节点开始调整,n为节点总数 从0开始计算 i节点的子节点为 2*i+1, 2*i+2
void MinHeapFixdown(int a[], int i, int n)
{
int j, temp;
temp = a[i];
j = 2 * i + 1;
while (j < n)
{
if (j + 1 < n && a[j + 1] < a[j]) //在左右孩子中找最小的
j++;
if (a[j] >= temp)
break;
a[i] = a[j]; //把较小的子结点往上移动,替换它的父结点
i = j;
j = 2 * i + 1;
}
a[i] = temp;
}
//在最小堆中删除数
void MinHeapDeleteNumber(int a[], int n)
{
Swap(a[0], a[n - 1]);
MinHeapFixdown(a, 0, n - 1);
}
//建立最小堆
void MakeMinHeap(int a[], int n)
{
for (int i = n / 2 - 1; i >= 0; i--)
MinHeapFixdown(a, i, n);
}
void MinheapsortTodescendarray(int a[], int n)
{
for (int i = n - 1; i >= 1; i--)
{
Swap(a[i], a[0]);
MinHeapFixdown(a, 0, i);
}
}4.时间复杂度:
最好情况:\(O\left ( N\log N\right )\)
最坏情况:\(O\left ( N\log N \right )\)
平均情况:\(O\left ( N\log N \right )\)
由于每次重新恢复堆的时间复杂度为\(O\left ( \log N \right )\),共N - 1次重新恢复堆操作,再加上前面建立堆时N / 2次向下调整,每次调整时间复杂度也为\(O\left ( \log N \right )\)。二次操作时间相加还是\(O\left ( N\log N \right )\)。故堆排序的时间复杂度为\(O\left ( N\log N \right )\)。
5.空间复杂度:
堆排序是就地排序,辅助空间为\(O\left (1 \right )\)。
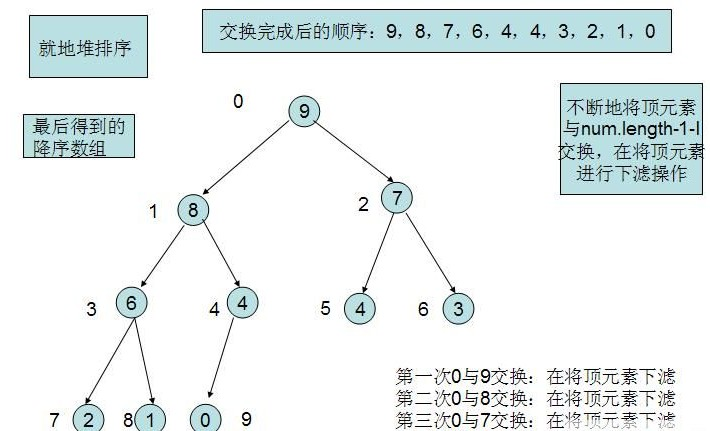
***
补:关于堆的几个函数:(摘自MoreWindows大佬)
建立堆
make_heap(_First, _Last, _Comp)
默认是建立最大堆的。对int类型,可以在第三个参数传入greater
在堆中添加数据
push_heap (_First, _Last)
要先在容器中加入数据,再调用push_heap ()
在堆中删除数据
pop_heap(_First, _Last)
要先调用pop_heap()再在容器中删除数据
堆排序
sort_heap(_First, _Last)
排序之后就不再是一个合法的heap了
二、 \(O\left ( N\right )\)
\(\left ( 1\right )\)桶排序(稳定)
1.原理:
(以下摘自百度)
假定:输入是由一个随机过程产生的[0, 1)区间上均匀分布的实数。将区间[0, 1)划分为n个大小相等的子区间(桶),每桶大小1/n:[0, 1/n), [1/n, 2/n), [2/n, 3/n),…,[k/n, (k+1)/n ),…将n个输入元素分配到这些桶中,对桶中元素进行排序,然后依次连接桶输入0 ≤A[1..n] <1辅助数组B[0..n-1]是一指针数组,指向桶(链表)。
样例:
这里有一个数列{6,8,7,4,2,5},最大值不超过10;
我们定义三个数组,数列数组(a【】),桶数组(T【】),桶数组编号(Tn【】)
\(\begin{array} {|c||c||c|} a& T & Tn \\ \\6&0&0 \\8&0&1 \\7&0&2 \\4&0&3 \\2&0&4 \\5&0&5 \\0&0&6 \\0&0&7 \\0&0&8 \\0&0&9 \end{array}\)
我们进行桶排序,这个过程类似这样:空桶[ 待排数组[ i ] ]++。
\(\begin{array} {|c||c||c|} a& T & Tn \\ \\6&0&0 \\8&1&1 \\7&0&2 \\4&1&3 \\2&1&4 \\5&1&5 \\0&1&6 \\0&1&7 \\0&0&8 \\0&0&9 \end{array}\)
若T[i]!=0,输出其对应的Tn[i+1].
2.考点:桶排很多时候只是程序的一部分,他是一种思路,如P2119 魔法阵
3.关键代码:
①计数排序:(即普通桶排,所排数组不超过int范围)
for(int i=1;i<=N;i++)
{
T[a[i]]++;
}
for(int i=1,j=1;i<=M;i++)//M为a[]最大值
{
while((T[i]--)>0)
{
a[j++]=i;
}
}②离散化(所排数组不在int范围内)
STL库map<>
map<LL,LL>T;
for(int i=1;i<=N;i++)
{
T[a[i]]++;
}
for(int i=1,j=1;i<=M;i++)//M为a[]最大值
{
while((T[i]--)>0)
{
a[j++]=i;
}
}4.时间复杂度:
\(O\left ( N\right )\),为线性排序,是排序中最快的。
5.空间复杂度:
\(O\left ( Maxn\right )\),其中\(Maxn\)为a【】中最大的数

总结:
排序算法除了上述以外,还有基数排序(稳定,\(O\left ( N\right )\)),希尔排序(不稳定,\(O\left ( N^{1.25}\right )\)),直接插入排序(稳定,\(O\left ( N^2\right )\)),下面是一张排序算法的时间复杂度表
| 排序方法 | 平均时间 | 最好时间 | 最坏时间 |
|---|---|---|---|
| 桶排序(稳定) | \(O\left ( N\right )\) | \(O\left ( N\right )\) | \(O\left ( N\right )\) |
| 基数排序(稳定) | \(O\left ( N\right )\) | \(O\left ( N\right )\) | \(O\left ( N\right )\) |
| 归并排序(稳定) | \(O\left ( N\log N\right )\) | \(O\left ( N\log N\right )\) | \(O\left ( N\log N\right )\) |
| 快速排序(不稳定) | \(O\left ( N\log N\right )\) | \(O\left ( N\log N\right )\) | \(O\left ( N^2 \right )\) |
| 堆排序(不稳定) | \(O\left ( N\log N\right )\) | \(O\left ( N\log N\right )\) | \(O\left ( N\log N\right )\) |
| 希尔排序(不稳定) | \(O\left ( N^{1.25}\right )\) | ||
| 冒泡排序(稳定) | \(O\left ( N^2 \right )\) | \(O\left ( N\right )\) | \(O\left ( N^2 \right )\) |
| 选择排序(不稳定) | \(O\left ( N^2 \right )\) | \(O\left ( N^2 \right )\) | \(O\left ( N^2 \right )\) |
| 直接插入排序(稳定) | \(O\left ( N^2 \right )\) | \(O\left ( N\right )\) | \(O\left ( N^2 \right )\) |