因为教材基本都是把1作为串的开始索引计算,而本人觉得string的索引是从0开始的,本文全片以串的索引为0开始,说明算法。
一、朴素模式匹配算法
在主串 s t r str str中匹配子串 s u b S t r subStr subStr,若 s t r str str中存在 s u b S t r subStr subStr,则返回字串在主串中第一次出现的索引。不存在,则返回-1。
在 “helloworld” 中匹配 “llo”,匹配成功时的指针状态。

朴素模式匹配算法的实现代码:
int Index(string str, string subStr){
int cur = 0;
int j = 0;
int i = cur;
while(j < subStr.size() && cur < str.size()){
if(str[i] != subStr[j]){
cur++; // 主串当前遍历的位置后移
i = cur; // 不相等,开始找下一个字串
j = 0; // 子串的索引j还原,准备下一轮匹配
}else{
i++;
j++;
}
}
return j >= subStr.size() ? cur : -1;
}
算法缺点: 一旦进行 指针i 和 指针j 指向的字符不同,指针i 就得退回到指针cur的地方,等待下一轮匹配。若在匹配过程中,指针i 经常性的回溯,算法效率就会很低。
二、KMP算法
为了解决朴素模式匹配算法经常回溯的问题,我们将算法改进,得到KMP算法
在KMP算法中,我们让主串的指针cur不回溯,而模式串的指针回溯
首先,我们需要构造一个数组next,next[j] 表示模式串的 j号字符 与主串对比,不匹配时应该回溯到的目标索引,其中 0 ≤ j < s u b S t r . s i z e ( ) 0 \le j < subStr.size() 0≤j<subStr.size()
介绍一个构造next数组的简单方法
当子串的j号字符匹配失败时,由前面的 0 0 0号 到 j − 1 j - 1 j−1号字符组成的串记为 S S S
- n e x t [ j ] = S next[j] = S next[j]=S 的最长的相等前后缀长度
- n e x t [ 1 ] = 0 next[1] = 0 next[1]=0
- n e x t [ 0 ] = − 1 next[0] = -1 next[0]=−1
注:
- 串的前缀: 包含第一个字符,且不包含最后一个字符的任意子串
- 串的后缀: 包含最后一个字符,且不包含第一个字符的任意子串
- 对于不同的模式串, n e x t [ 1 ] = 0 next[1] = 0 next[1]=0 和 n e x t [ 0 ] = − 1 next[0] = -1 next[0]=−1必然成立
以模式串为 a b a b a a ababaa ababaa说明,next数组的构造
1. j = 5
此时 S = a b a b a S=ababa S=ababa。很容易得到当前缀、后缀长度都为3时,前后缀长度最长且相等,前后缀都是 a b a aba aba。而长度为4时,前缀为 a b a b abab abab,后缀为 b a b a baba baba,前后缀不相等,故 n e x t [ 5 ] = 3 next[5]=3 next[5]=3
2. j = 4
此时 S = a b a b S=abab S=abab。同理,当前缀、后缀长度都为2时,前后缀长度最长且相等,前后缀都是 a b ab ab。而长度为3时,前缀为 a b a aba aba,后缀为 b a b bab bab,前后缀不相等,故 n e x t [ 4 ] = 2 next[4]=2 next[4]=2
3. j = 3、2
同理,我们得到 n e x t [ 3 ] = 1 , n e x t [ 2 ] = 0 next[3]=1,next[2]=0 next[3]=1,next[2]=0
4. j = 1
此时 S = a S=a S=a。由于前缀不能包含串的最后一个字符,且后缀不能包含串的第一个字符,故前缀和后缀只能为空串,也就是最大长度为0。即 n e x t [ 1 ] = 0 next[1]=0 next[1]=0
5. j = 0
此时表示,模式串的0号元素就不匹配。我们的操作是将主串的指针cur后移一位,将指针j置为-1,让指针cur 和 指针j同时自增,就达到了同时将指针cur自增 和指针j置0 的目的。故 n e x t [ 0 ] = − 1 next[0] = -1 next[0]=−1
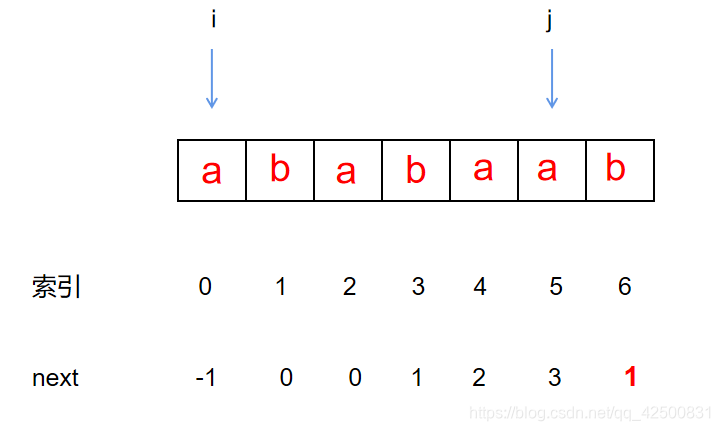
于是我们得到模式串 a b a b a a ababaa ababaa 的 n e x t 数 组 为 [ − 1 , 0 , 0 , 1 , 2 , 3 ] next数组为 [-1,0,0,1,2,3] next数组为[−1,0,0,1,2,3]
n e x t next next数组的构造代码如下:
vector<int> getNext(string subStr) {
vector<int> next(subStr.size());
next[0] = -1;
int i = -1; //指向已匹配前缀的后一个元素
int j = 0; //遍历子串的指针
while (j < (int)subStr.size() - 1) {
if (i == -1 || subStr[i] == subStr[j]) {
i++; // 字符相等,当前匹配的长度 + 1,用于给next[j+1]赋值
next[++j] = i; // 当前是j,实际上填写的是 j+1 号元素
}else{
i = next[i]; // 利用以前匹配的前缀,再次进行匹配
}
}
return next;
}
由于是复习,没太多时间写博客,我只讲构造数组时最精华的部分: i = n e x t [ i ] i = next[i] i=next[i]
一定有很多朋友就是想不明白,这指针i回溯为什么是这样的: i = n e x t [ i ] i = next[i] i=next[i],说真的,我也理解了很长时间。
划重点!!!!
首先我们要明白, n e x t next next数组存放的值,就是用来回溯的依据。为什么要根据 n e x t next next数组的值回溯?
因为我们是通过计算当前字符前面的串中,最长前缀后缀的长度来填写 n e x t next next数组的。而且每次填写 n e x t next next数组的时候,都是在已经匹配的前缀的基础上,再看当前指针i 和 指针j所指字符是否相同,相同则直接将已经匹配的前缀+1,然后填写 n e x t next next数组。
在指针i 和 指针j所指字符不同时,才进行回溯。这里需要指出:next数组存放的,是一个个已经匹配的前缀。不信你看:

数组中填写1、2、3是一路在已经匹配的前缀的基础上加1,没有回溯。(本质上是i加1,并不是根据前一个next值得到)
- 对于 n e x t [ 5 ] = 3 next[5]=3 next[5]=3,表示此时匹配的前缀为 a b a aba aba
- 对于 n e x t [ 4 ] = 2 next[4]=2 next[4]=2,表示此时匹配的前缀为 a b ab ab
- 对于 n e x t [ 3 ] = 1 next[3]=1 next[3]=1,表示此时匹配的前缀为 a a a
而此时,指针i 和 指针j所指字符不同。由于我们每次都是在已经匹配成功的前缀基础上加1,得到当前 n e x t next next数组的值。那我们能不能看一下,我们之前匹配的前缀中,有没有能和当前字符匹配的前缀?如果有,那我们就直接可以加1填写数组了。
这就很妙啊!
那现在知道 i = n e x t [ i ] i=next[i] i=next[i]就是利用以前已经匹配的前缀了。但我们回溯,不是利用所有已经匹配完成的前缀,只利用一部分。究竟哪一部分呢?接着看。
如图,这时 指针i 想:既然我不能利用前缀 a b a aba aba得到当前需要计算的 n e x t next next值,那我就利用我前面的串S( a b a aba aba)中,最长的、且已经匹配的前缀( n e x t [ i ] next[i] next[i])再进行匹配,即指针i回溯到 n e x t [ i ] next[i] next[i]
于是,我们回溯到前面已经匹配成功的前缀处,于是我们 回溯到上一个前缀 a a a处:
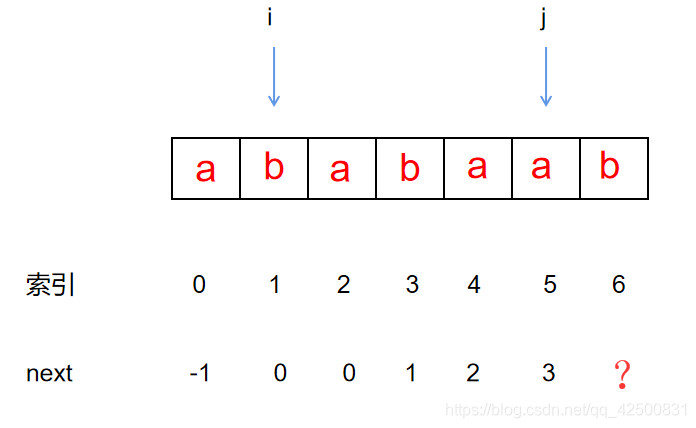
指针i 和 指针j所指字符依然不同,我们回溯到上一个前缀处(此时为空串):
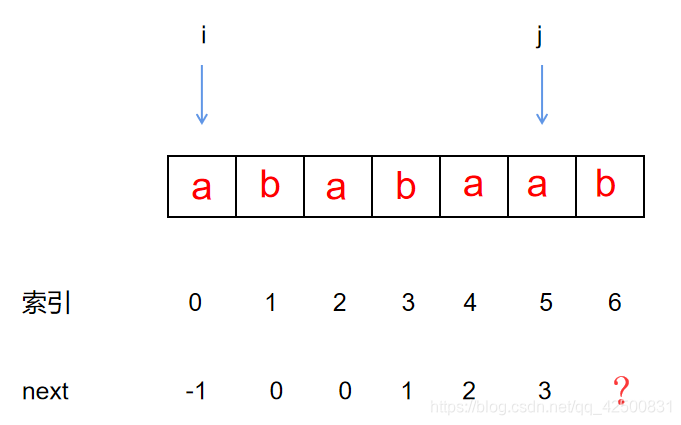
此时,指针i 和 指针j所指字符相同。利用已经匹配成功的串长+1(空串)填写 n e x t next next数组
朴素模式匹配算法结合 n e x t next next数组优化后,就是KMP算法。代码根据朴素模式的代码改造即可。
int Index_KMP(string str, string subStr, vector<int> next) {
int cur = 0; // 指向主串,不回溯
int j = 0; // 指向子串,经常回溯
//一定注意size()方法返回无符号整型,需转为有符号整型再进行比较
while (j < (int)subStr.size() && cur < (int)str.size()) {
if (j == -1 || str[cur] == subStr[j]) {
cur++;
j++; // 继续比较后继字符
}else {
j = next[j]; // 当前匹配失败,子串的指针回溯
}
}
return j >= (int)subStr.size() ? cur - subStr.size() : -1;
}