原文链接
https://www.analyticsvidhya.com/blog/2018/06/understanding-building-object-detection-model-python/
在外网上看到一篇非常好的目标检测入门教程,特此翻译过来,希望能对他人有所帮助,也加深下自己的记忆。(大部分机器都翻译的可以,如有错误我会改正,各位也可以google看原文)
介绍
当我们看到一张图像时,我们的大脑会立即识别其中的物体。另一方面,机器识别这些对象需要大量的时间和训练数据。但是随着硬件和深度学习的进步,这个计算机视觉领域变得更加简单和直观。
以下图为例。该系统能够以令人难以置信的精确度识别图像中的不同物体。

它帮助自动驾驶汽车在交通中安全行驶,在拥挤的地方发现暴力行为,帮助运动队分析球探报告,确保制造过程中零部件的质量控制,等等。
而这些仅仅是对象检测技术所能做的皮毛而已!
然后我们将深入研究用Python构建我们自己的对象检测系统。
在本文的最后,您将拥有足够的知识来独自承担不同的目标检测挑战!
如果您还没有,或者需要复习一下,我建议您先阅读以下文章:
我们可以使用不同的方法来解决对象检测问题
方法1:原始的方法(分而治之)
方法2:增加分部的数量
方法3:执行结构化的划分
方法4:变得更有效率
方法5:使用深度学习进行特征选择并构建端到端方法
获取技术:如何使用ImageAI库构建对象检测模型
让我们(假设)为自动驾驶汽车建立一个行人检测系统。
假设您的汽车捕获了如下所示的
你如何描述这幅图像?

由于交通标志看不清楚,汽车的行人检测系统应该准确地识别出人们在哪里行走,这样我们就可以避开他们。
它所能做的就是在这些人周围创建一个包围框,这样系统就可以确定这些人在图像中的位置,然后相应地决定走哪条路径,以避免任何灾难。

2,过滤掉警示标志
在本节中,我们将研究一些可以用于检测图像中的目标的技术。
我们将从最简单的方法开始,并从那里找到我们的方法。
如果您对我们将在下面看到的方法有任何建议或替代方法,请在评论部分告诉我!
方法1:初始方法(分而治之)

2,右上角

3,左下角

4,右下角

现在,下一步是将这些部分分别输入图像分类器。
这将给我们一个输出,这部分图像是否有行人。
如果是,在原始图像中标记那个长方形。
输出结果大致如下:

这是一个很好的方法,首先尝试,但我们正在寻找一个更准确和更精确的系统。它需要识别整个对象(在本例中是一个人),因为仅定位对象的一部分可能会导致灾难性的结果。
方法2:增加分部的数量
以前的系统运行得很好,但是我们还能做什么呢?
我们可以通过成倍地增加我们输入到系统中的分部的数量来改进它。
我们的输出
当然,我们的解决方案似乎比天真的方法好一点,但它充满了许多近似相同的边界框。
这是一个问题,我们需要一个更有条理的方法来解决我们的问题。
方法3:执行结构化的划分

步骤2:定义每个部分的质心步骤
3:对于每个质心,取三个不同高度和宽高比的部分
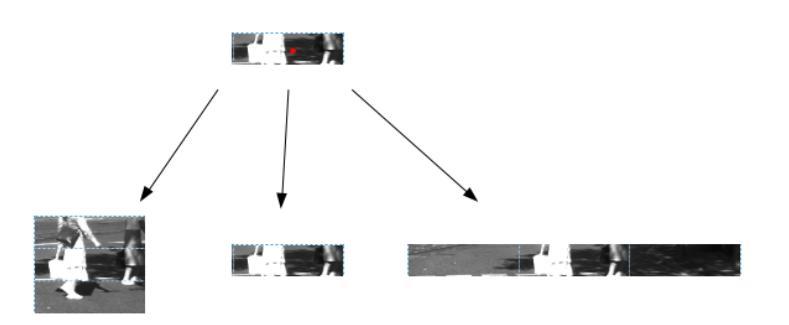
看看下面:

继续阅读,看看另一种方法将产生更好的结果。
方法4:变得更有效率
你能告诉我怎么做吗?
在我的脑海里,我可以提出一个优化方案。
如果我们考虑方法3,我们可以做两件事使我们的模型更好。

在这里,我们可以从一个锚点上取9个形状,即3个不同高度的正方形斑块和6个不同高度的垂直和水平矩形斑块。
这将为我们提供不同的长宽比的补丁。
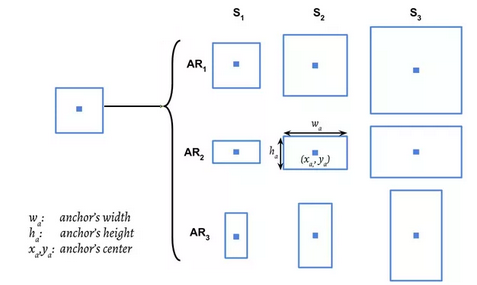
但它将再次创造一个爆炸的所有补丁,我们必须通过我们的图像分类模型。
例如,我们可以构建一个中间分类器,它试图预测补丁是否具有背景,或者是否可能包含一个对象。
这将大大减少我们的图像分类模型必须看到的补丁。
让我们再看一遍方法3的输出:

我们可以选择其中任何一个。
所以为了做出预测,我们考虑所有“说同样的话”的补丁,然后选择最有可能发现一个人的补丁。
我们几乎很有把握了,但是你能猜出少了什么吗?
当然是深度学习了!
方法5:使用深度学习进行特征选择并构建端到端方法
你能推荐我们在哪里以及如何利用它来解决我们的问题吗?
我列出了一些方法如下:
我们也可以使用神经网络来建议选择的补丁
我们可以强化一种深度学习算法,以给出尽可能接近原始边界框的预测。
这将确保算法提供更紧密和更精细的包围框预测
这样做的好处是,每个较小的神经网络组件将有助于优化同一神经网络的其他部分。
这将有助于我们共同培养整个深度模型。
我们将在下一节中看到如何使用Python创建它。

我们将使用ImageAI,这是一个python库,它支持用于计算机视觉任务的最先进的机器学习算法。
我们不需要通过复杂的安装脚本才能开始。
我们甚至不需要GPU来生成预测!
我们将使用这个ImageAI库来获得我们在方法#5中看到的输出预测。
我强烈建议您(在您自己的机器上)写下下面的代码,因为这将使您能够从本节中获得最大限度的知识。
一旦您在本地系统中安装了Anaconda,您就可以开始执行以下步骤。
conda create -n retinanet python=3.6 anaconda
激活环境并安装必要的包。
source activate retinanet
conda install tensorflow numpy scipy opencv pillow matplotlib h5py keras
然后安装ImageAI库。
pip install https://github.com/OlafenwaMoses/ImageAI/releases/download/2.0.1/imageai-2.0.1-py3-none-any.whl
步骤4:现在下载生成预测所需的预训练模型。
这个模型是基于RetinaNet(一篇后续文章的主题)的。
点击链接下载-视网膜网络预训练模型https://github.com/OlafenwaMoses/ImageAI/releases/download/1.0/resnet50_coco_best_v2.0.1.h5
将图像命名为image.png
from imageai.Detection import ObjectDetection
import os
execution_path = os.getcwd()
detector = ObjectDetection()
detector.setModelTypeAsRetinaNet()
detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5"))
detector.loadModel()
custom_objects = detector.CustomObjects(person=True, car=False)
detections = detector.detectCustomObjectsFromImage(input_image=os.path.join(execution_path , "image.png"), output_image_path=os.path.join(execution_path , "image_new.png"), custom_objects=custom_objects, minimum_percentage_probability=65)
for eachObject in detections:
print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
print("--------------------------------")
png,它包含图像的边框框。
from IPython.display import Image
Image("image_new.png")

您已经为行人检测创建了自己的对象检测模型。
这有多棒?
最后指出
我们还了解了如何使用ImageAI库构建用于行人检测的对象检测模型。
如果你确实用上述方法解决了这样的问题,特别是为社会事业,请在下面的评论中告诉我!