目标检测基础知识介绍
Author:Mr. Sun
Date: 2019.03.16
Location:DaLian university of technology
导语:最近看了很多的关于目标检测的博客和论文,看的似懂非懂;因此今天开始写一下自己的学习心得,希望能给需要的人一些帮助。
摘要:
在今天之前我的大部分时间都花在学习图像的分类上,主要是学习经典的卷积神经网络(LeNet/AlexNet/NIN/VGG/Google/ResNet)等等,然后利用迁移学习(transfer learning)技术对不同图像的分类任务(classification)进行训练(train)。但是,一直以来没有学习关于目标检测(object detection)的相关内容,就觉得自己的知识始终是有很大的空缺。因此从今天开始学习目标检测的相关知识,这篇博客将主要用来记录一些很基础的知识或者这个方向的研究现状和发展趋势(trend)。
1、计算机视觉(CV,Computer Vision)领域任务是什么?
目前计算机视觉(CV,computer vision)与自然语言处理(Natural Language Process, NLP)及语音识别(Speech Recognition)并列为人工智能(AI,artificial intelligence)·机器学习(ML,machine learning)·深度学习(DL,deep learning)方向的三大热点方向 。
图像分类、目标检测、分割是计算机视觉领域的三大任务。
如何从图像中解析出可供计算机理解的信息,是机器视觉(Machine Vision)的中心问题。深度学习模型由于其强大的表示能力,加之数据量的积累和计算力的进步,成为机器视觉的热点研究方向。那么,如何理解一张图片呢?根据任务的需要,有图1中所示三个主要的层次:

图1:机器理解图像的三个层次
一是分类(Classification),即是将图像结构化为某一类别的信息,用事先确定好的类别(category)或实例ID来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。其中,ImageNet是最权威的评测集,每年的ILSVRC催生了大量的优秀深度网络结构,为其他任务提供了基础。在应用领域,人脸、场景的识别等都可以归为分类任务。
二是检测(Detection)。分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息(classification + localization)。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因此检测模型的输出是一个列表,列表的每一项使用一个数组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
三是分割(Segmentation)。分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别(实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
图像分类(image classification)是将图像划分(divide)为单个类别,通常对应于图像中最突出的物体。但是现实世界的很多图像通常包含的不只是一个物体,此时如果使用图像分类模型为图像分配一个单一标签其实是非常粗糙的,并不准确。对于这样的情况,就需要目标检测(object detection)模型,目标检测模型可以识别一张图片的多个物体,并可以定位出不同物体(给出边界框)。目标检测在很多场景有用,如无人驾驶和安防系统。
2、常用的目标检测(Object Detection)算法的综述
常见的经典目标检测算法如下图2所示:

图2:常用的经典目标检测算法图
目标检测的基本思路:同时解决定位(localization) + 识别(Recognition)。
多任务学习,带有两个输出分支。一个分支用于做图像分类,即全连接+softmax判断目标类别,和单纯图像分类区别在于这里还另外需要一个“背景”类。另一个分支用于判断目标位置,即完成回归任务输出四个数字标记包围盒位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为“背景”时才使用。详细结构如下图3所示:
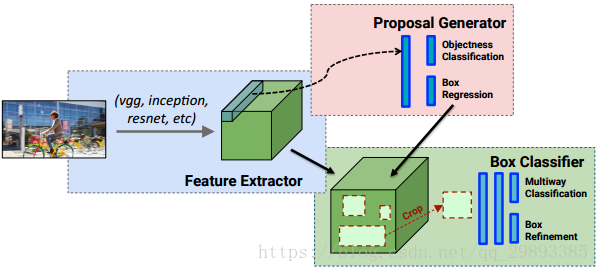
图3:目标检测的多任务学习结构
传统的目标检测框架,主要包括三个步骤:
(1)利用不同尺寸的滑动窗口框住图中的某一部分作为候选区域;
(2)提取候选区域相关的视觉特征。比如人脸检测常用的Harr特征;行人检测和普通目标检测常用的HOG特征等;
(3)利用分类器进行识别,比如常用的SVM模型。
目前目标检测领域的深度学习方法主要分为两类:两阶段(Two Stages)的目标检测算法;一阶段(One Stage)目标检测算法。
两阶段(Two Stages):首先由算法(algorithm)生成一系列作为样本的候选框,再通过卷积神经网络进行样本(Sample)分类。
常见的算法有R-CNN、Fast R-CNN、Faster R-CNN等等。
一阶段(One Stage ):不需要产生候选框,直接将目标框定位的问题转化为回归(Regression)问题处理(Process)。
常见的算法有YOLO、SSD等等。
基于候选区域(Region Proposal)的,如R-CNN、SPP-net、Fast R-CNN、Faster R-CNN、R-FCN;
基于端到端(End-to-End),无需候选区域(Region Proposal)的,如YOLO、SSD。
对于上述两种方式,基于候选区域(Region Proposal)的方法在检测准确率和定位精度上占优,基于端到端(End-to-End)的算法速度占优。相对于R-CNN系列的“看两眼”(候选框提取和分类),YOLO只需要“看一眼”。总之,目前来说,基于候选区域(Region Proposal)的方法依然占据上风,但端到端的方法速度上优势明显,至于后续的发展让我们拭目以待。
3、目标检测的候选框是如何产生的?
如今深度学习发展如日中天,RCNN/SPP-Net/Fast-RCNN等文章都会谈及候选边界框(Bounding boxes)的生成与筛选策略。那么候选框是如何产生的?又是如何进行筛选的呢?其实物体候选框获取当前主要使用图像分割与区域生长技术。区域生长(合并)主要由于检测图像中存在的物体具有局部区域相似性(颜色、纹理等)。目标识别与图像分割技术的发展进一步推动有效提取图像中信息。
根据目标候选区域的提取方式不同,传统目标检测算法可以分为基于滑动窗口的目标检测算法和基于选择性搜索的目标检测算法。滑窗法(Sliding Window)作为一种经典的物体检测方法,个人认为不同大小的窗口在图像上进行滑动时候,进行卷积运算后的结果与已经训练好的分类器判别存在物体的概率。选择性搜索(Selective Search)是主要运用图像分割技术来进行物体检测。
(1)滑动窗口(Sliding Window)
采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了。但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。接下来,我们看一下滑窗法的物体检测流程图如图4所示:
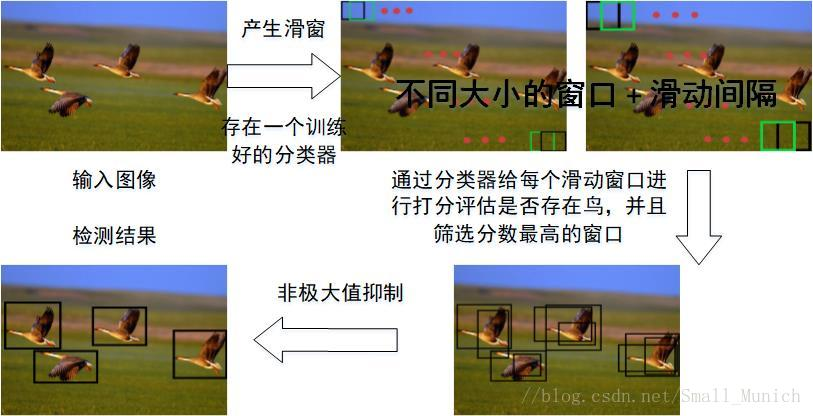
图4:滑窗法目标检测流程图
(2)选择性搜索