MapReduce并行计算框架
基本知识
前言
- MapReduce计算框架是Google提出的一种并行计算框架,是Google云计算模型MapReduce的java开源实现,用于大规模数据集(通常1TB级以上)的并行计算。但其实,MR不仅是一种分布式的运算技术,也是简化的分布式编程模式,是用于解决问题的程序开发模型。
核心概念
计算模型
- 计算模型的 核心概念 是”Map(映射)”和”Reduce(归约)”。用户需要指定一个Map函数,用来把一组键值对映射成一组新的键值对,并指定并发的Reduce函数用来合并所有的具有相同中间key值的中间的value值。作业的输入和输出都会被存储在文件系统中。整个框架负责 任务的调度和监控,以及重新执行已经失败的任务 。
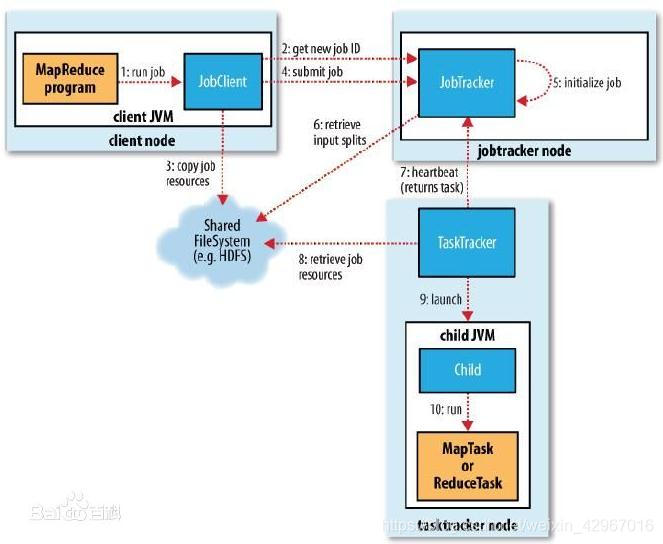
系统架构
-
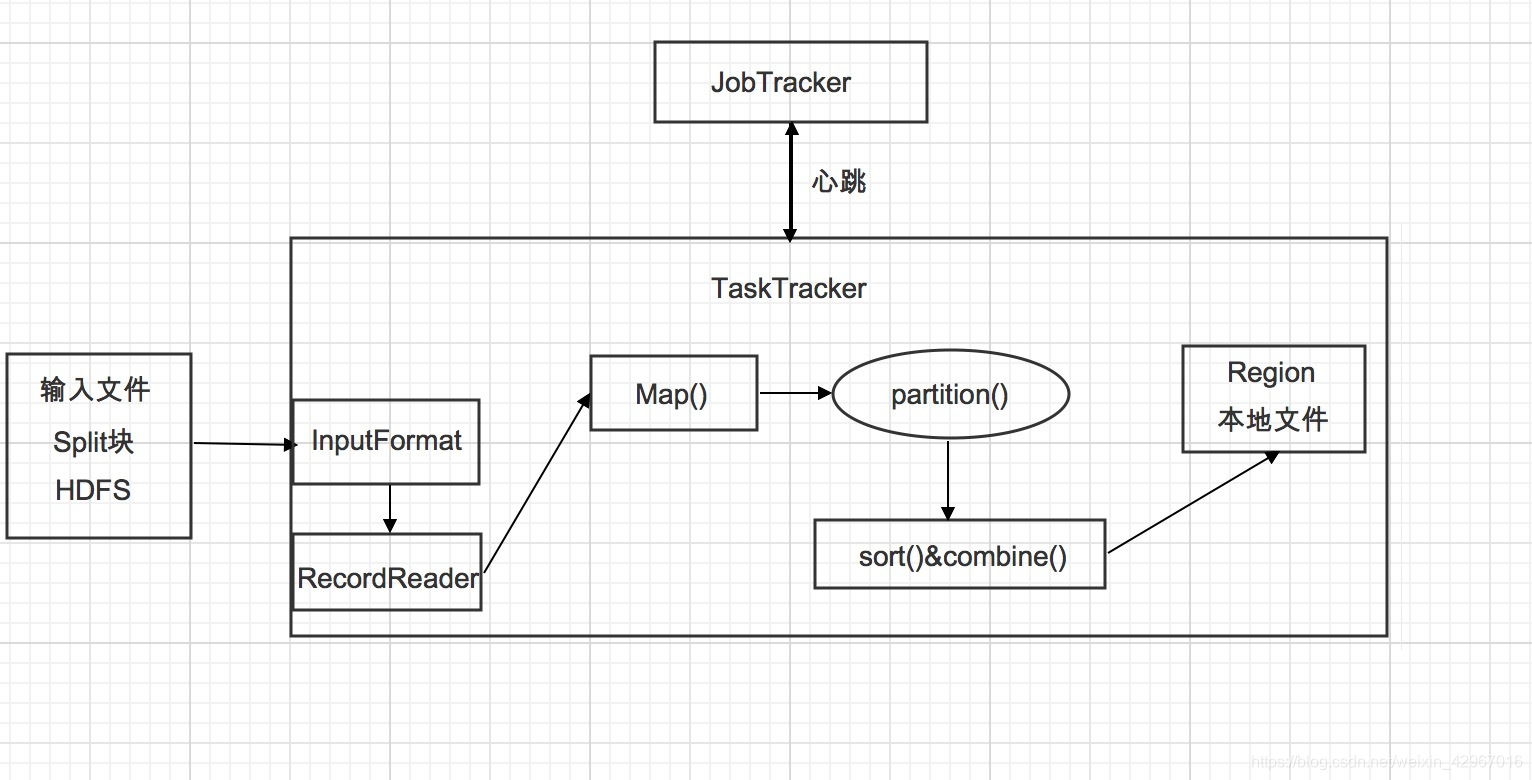
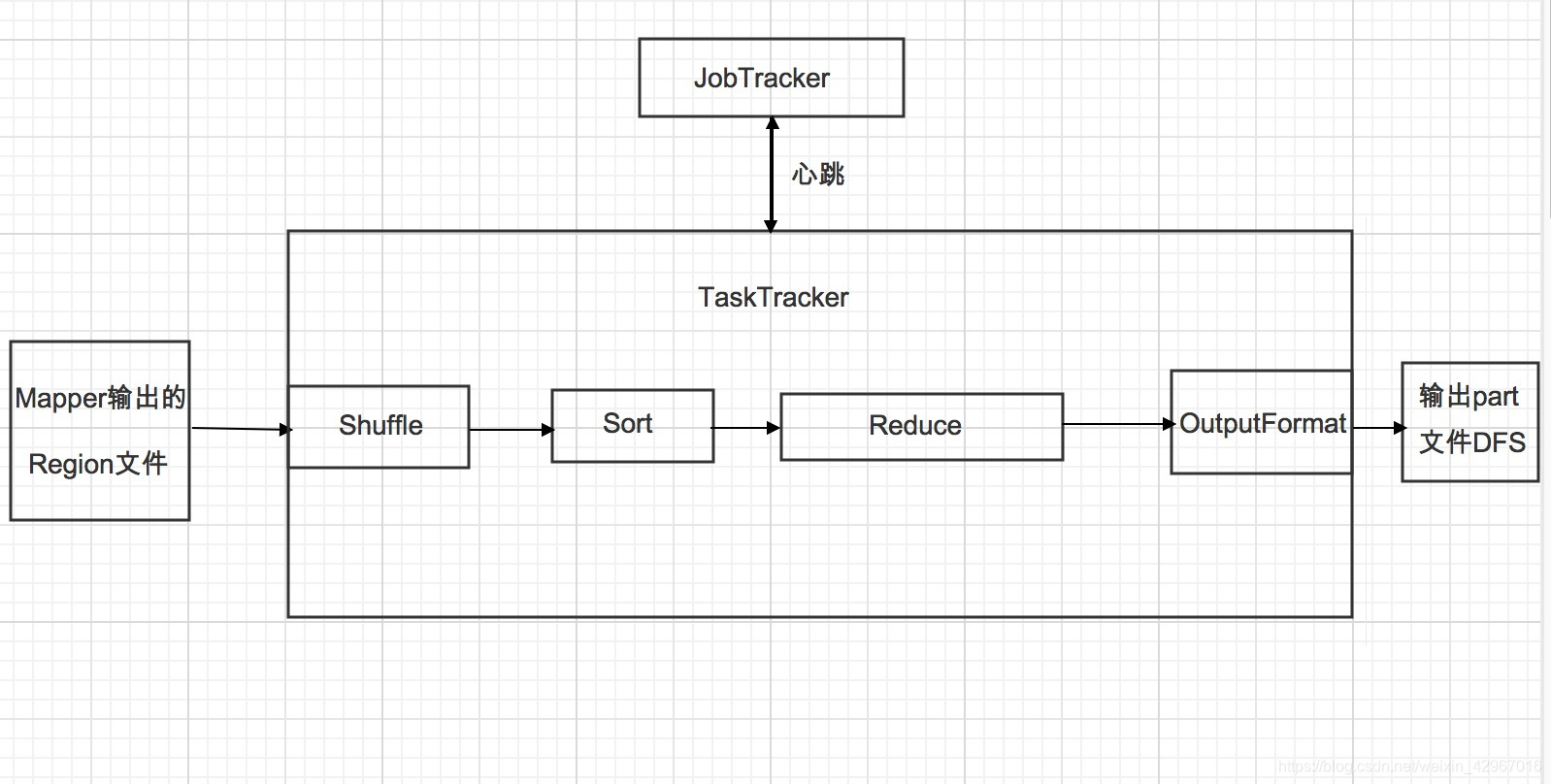
在系统架构上,MapReduce框架是一种主从架构,由一个单独的JobTracker节点和多个TaskTracker节点共同组成。
1)JobTracker是MapReduce的Master,负责调度构成一个作业的所有任务,这些任务分布在不同 的TaskTracker节点上,监控它们的执行,重新执行已经失败的任务,同时提高状态和诊断信息给作业客户端。
2)TaskTracker是MapReduce的Slave,仅负责运行由Master指派的任务执行。
作业配置
- 对于用户来讲,我们应该在应用程序中 指明输入和输出的位置路径,并通过实现合适的接口或抽象类来提供Map和Reduce函数,再加上其他作业的参数,就构成了作业配置。
计算流程与机制
作业提交和初始化
- (作业提交)命令行提交->作业上传->产生切分文件->提交作业到JobTracker->(作业初始化)->(Setup Task->Map Task->Reduce Task->Cleanup Task)
具体过程会在之后的文章介绍
Mapper
- Mapper是MapReduce框架给用户暴露的Map编程接口,用户在实现自己的Mapper类时需要继承这个基类。执行Map Task任务:将输入键值对(key/value pair)映射到一组中间格式的键值对集合。
处理流程如下:
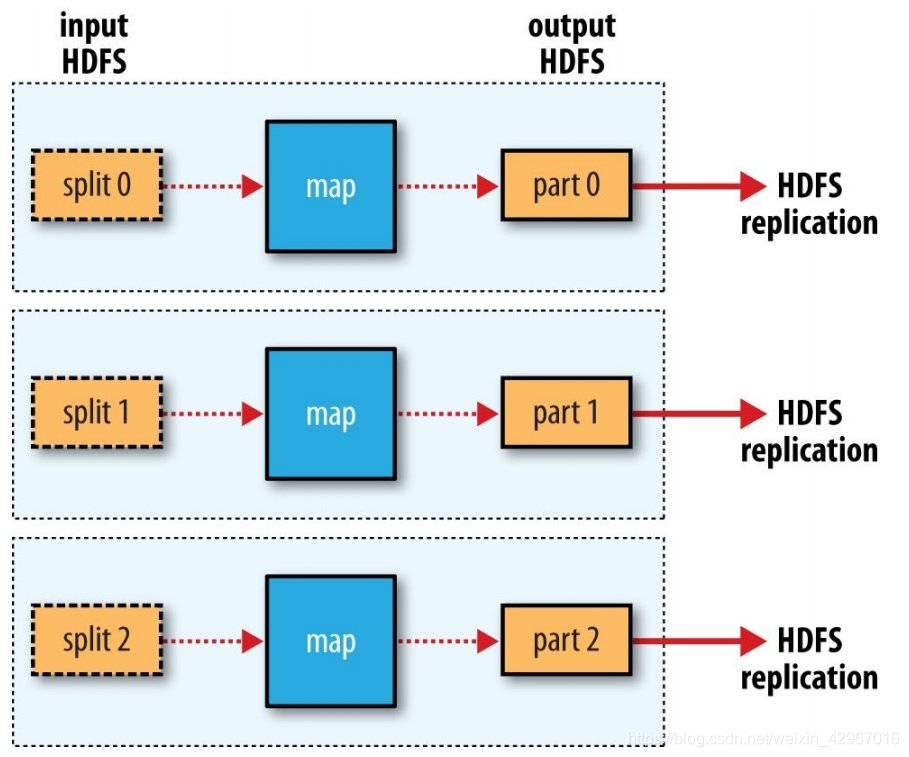
- 通过InputFormat接口获得InputSplit的实现,然后对输入的数据切分。每一个Split分块对应一个Mapper任务。
- 通过RecordReader对象读取生成<k,v>键值对。Map函数接受数据并处理后输出<k1,v1>键值对。
- 通过context.collect方法写入context对象中。当键值对集中被收集后,会被Partition类中的partition()函数以指定方式区分并写入输出缓冲区(系统默认的是HashPartitioner),同时调用sort()进行排序。
- 如果用户指定了Combiner,则会将键值对进行combine合并(相当于map端的reduce),输出到reduce写入文件。
Reducer
-
Reducer将与一个key关联的一组中间数值集归约为一个更小的数值集。
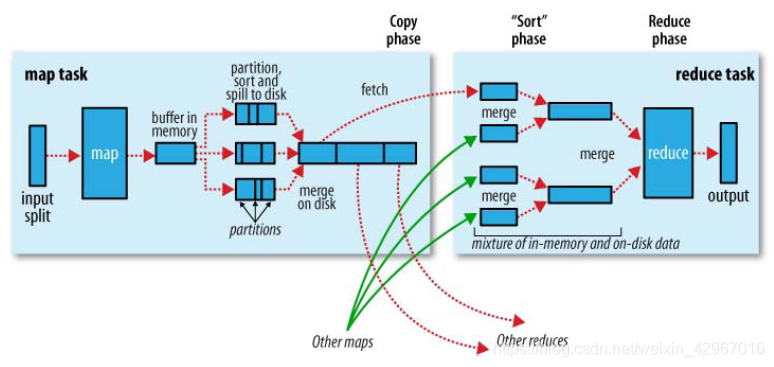
1.Shuffle阶段。框架通过HTTP协议为每个Reducer获得所有Mapper输出中与之相关的分块,这一阶段也称混洗阶段,所做的大量操作就是数据复制,因此也可以称为数据复制阶段。
2.Sort阶段。 框架按照key的值对Reducer的输入进行分组(因为不同的Mapper输出可能会有相同的key)。 Shuffle和Sort是同时进行的,Map的输出也是一边被取回一边被合并的。 如果需要改变分组方式,则需要指定一个Compartor,实现二次排序(后面会介绍)。
3.Reduce阶段。 调用Reduce()函数,对Shuffle和sort得到的<key,(list of values)>进行处理,输出结果到DFS中。
结构图示
输入/输出格式(常用)
- InputFormat
- 检查作业输入的有效性。
- 把输入文件切分成多个逻辑InputSplit实例,并把每个实例分发给一个Mapper(一对一);FileSplit是默认的InputSplit,通过write(DataOutput out)和readFields(DataInput in)两种方法进行序列化和反序列化。
- 提供RecordReader实现。
- OutputFormat
- 检验作业的输出。
- 验证输出结果类型是否如在Config中所配置的。
- 提供一个RecordWriter的实现,用来输出作业结果。
核心问题
Map和Reduce数量
-
Map数量通常由 Hadoop集群的DFS块大小确定 ,也就是输入文件的总块数。大致是每一个Node是10~100个。
Reduce的数量有3种情况:0(特殊),1,多个。
-
单个Reduce:

-
多个Reduce

-
数量为0(适应于不需要归约和处理的作业)
作业配置
- 作业配置的相关设置方法
| 作业配置方法 | 功能说明 |
|---|---|
| setNumReduceTasks | 设置reduce数目 |
| setNumMapTasks | 设置Map数目 |
| setInputFormatClass | 设置输入文件格式类 |
| setOutputFormatClass | 设置输出文件格式类 |
| setMapperClass | 输出Map类 |
| setCombiner | 设置Combiner类 |
| setReducerClass | 设置Reduce类 |
| setPartitionerClass | 设置Partitioner类 |
| setMapOutputKeyClass | 设置Map输出的Key类 |
| setMapOutputValueClass | 设置Map输出的Value类 |
| setOutputKeyClass | 设置输出key类 |
| setCompressMapOutput | 设置Map输出是否压缩 |
| setOutputValueClass | 设置输出value类 |
| setJobName | 设置作业名字 |
| setSpeculativeExecution | 设置是否开启预防性执行 |
| setMapSpeculativeExecution | 设置是否开启Map任务的预防性执行 |
| setReduceSpeculativeExecution | 设置是否开启Reduce任务的预防性执行 |
作业调度
- 调度的功能是将各种类型的作业在调度算法作用下分配给Hadoop集群中的计算节点,从而达到 分布式和并行计算 的目的。
- 调度算法模块中至少涉及两个重要流程:1.作业的选择 2.任务的分配。
调度过程 :
-
1)MapReduce框架中作业通常是通过JobClient.runJob(job)方法提交到JobTracker,JobTracker接收到JobClient的请求后将其加入作业调度队列中。
2)然后JobTracker一直等待JobClient通过RPC向其提交作业,而TaskTracker则一直通过RPC向JobTracker发送心跳信号询问是否有任务可执行,有则请求JobTracker派发任务给它执行。
3)如果JobTracker的作业队列不为空,则TaskTracker发送的心跳将会获得JobTracker向它派发的任务。
这是一个主动请求的任务:slave的TaskTracker主动向master的JobTracker请求任务。4)当TaskTracker接到任务后,通过自身调度在本slave建立起Task,执行任务。
常用调度器 主要包括:JobQueueTaskScheduler(FIFO调度器),CapacityScheduler(容量调度器),Fair Scheduler(公平调度器)等。
有用的MapReduce特性
- Counters 计数器
- DistributedCache 分布式缓存
- Tool 工具
- Compression 数据压缩
(后面会做介绍)