作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS
功能
分布式文件系统,用来存储海量数据。
工作原理
1、HDFS集群分为两大角色:NameNode、DataNode (Secondary Namenode)
2、NameNode负责管理整个文件系统的元数据
3、 DataNode 负责管理用户的文件数据块
4、 文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
5、 每一个文件块可以有多个副本,并存放在不同的datanode上
6、Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
7、HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
工作过程
写操作
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
读操作
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件
MapReduce
功能
并行处理框架,实现任务分解和调度。
工作原理
1、通过Job的submit()方法创建一个JobSummiter实例,并且调用其submitJobInternal()方法。
2、作业提交给ResourceManager,从ResourceMananger处得到一个ApplicationID
3、JobClien检查Job的输出说明,计算输入分片,并将Job资源(包括运行的Jar包、配置和分片信息)复制到HDFS
4、通过ResourceManager上的submitApplications进行作业提交
5、ResourceManager收到submitApplication()消息后,便将请求传递给调度器(scheduler)。调度器为其分配一个容器(Container),然后资源管理器在节点管理器(NodeManger)的管理下在Container中启动应用程序的master
6、初始化Job:通过创建多个簿记录对象以保持对作业进度的跟踪,因为它将接受来自任务的进度和完成报告
7、接受HDFS在Client端计算的输入分片信息
8、连接ResourceManager,向ResourceManager进行资源申请
9、Application master 通过与节点管理器(NodeManager)进行通信启动Container,该任务有主类为YarnChiled的Java程序执行。
10、在第9步之前,需要将任务需要的资源本地化,包括运行的Jar包、配置和分片信息和HDFS的文件
11、最后运行map任务或reduce任务。
工作过程
MapReduce的工作过程分为两个步骤:map和reduce。每个阶段的输入输出都是key-value的形式,key和value的类型可以自行指定。map阶段对切分好的数据进行并行处理,处理结果传输给reduce,由reduce函数完成最后的汇总。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc

2)编写map函数和reduce函数,在本地运行测试通过
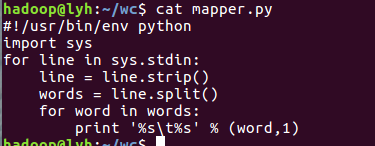

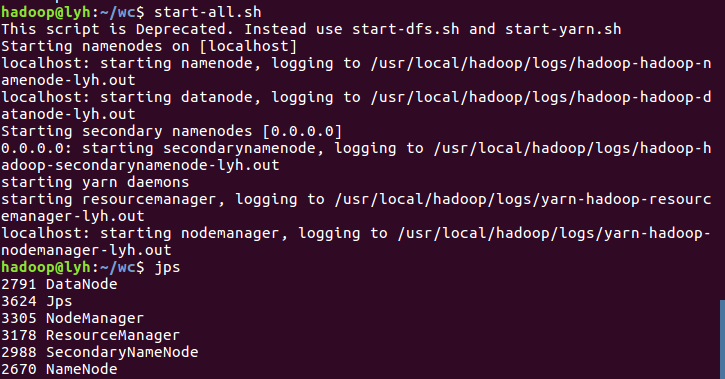
3)启动Hadoop:HDFS, JobTracker, TaskTracker
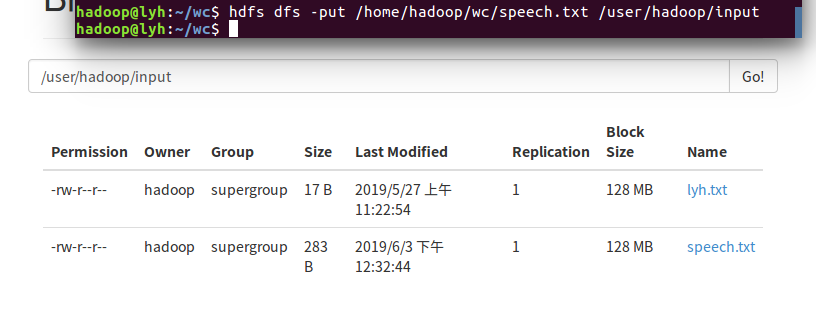
4)把文本文件上传到hdfs文件系统上 user/hadoop/input
5)streaming的jar文件的路径写入环境变量,让环境变量生效

6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh

7)source run.sh来执行mapreduce
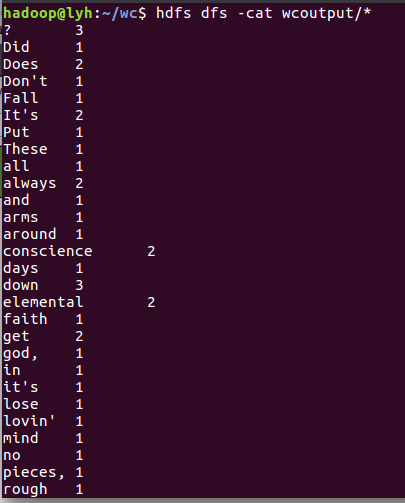
8)查看运行结果