GPU并行计算包括同步模式和异步模式:
异步模式:
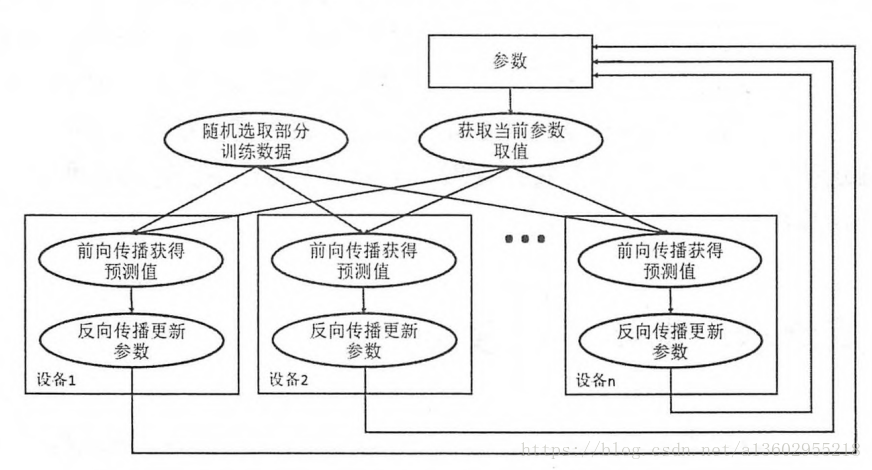
同步模式:
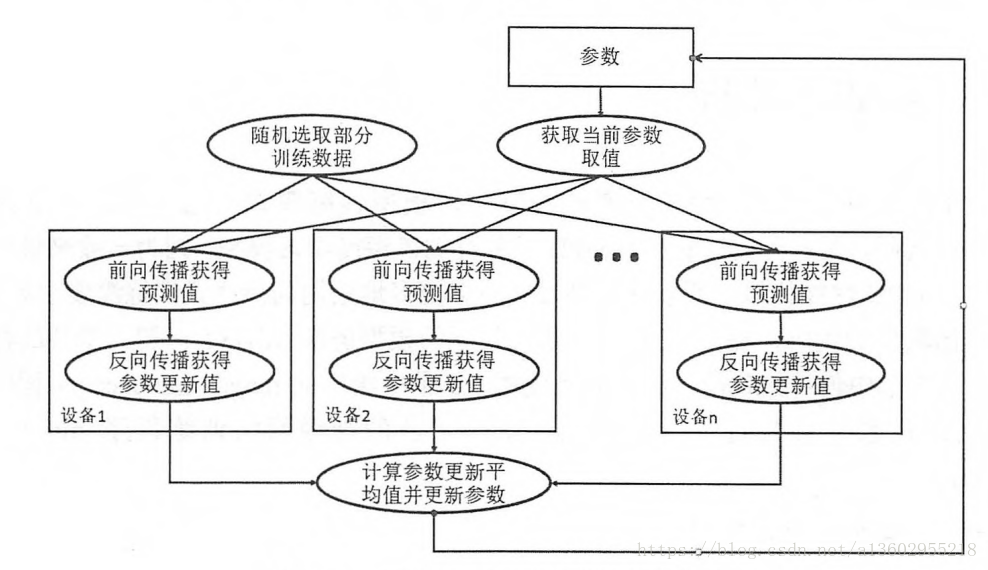
异步模式的特点是速度快,不用等待其他GPU计算完毕再更新,但是更新的不确定性可能导致到达不了全局最优。
同步模式需要等到所有GPU计算完毕,并计算平均梯度,最后赋值,缺点是需要等待最后一个GPU计算完毕,时间较慢。
实践中通常视情况使用上述两种方式。
实例
from datetime import datetime
import os
import time
import tensorflow as tf
BATCH_SIZE = 128
LEARNING_RATE_BASE = 0.1
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 1000
MOVING_AVERAGE_DECAY = 0.99
N_GPU = 1
MODEL_SAVE_PATH = 'logs_and_models/'
MODEL_NAME = 'model.ckpt'
DATA_PATH = './output.tfrecords'
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
#获取权重张量,并将L2损失加入损失集合中
def get_weight_variable(shape, regularizer):
weights = tf.get_variable("weights", shape, initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(weights))
return weights
#实现两层的全连接神经网络
def inference(input_tensor, regularizer):
with tf.variable_scope('layer1'):
weights = get_weight_variable([INPUT_NODE, LAYER1_NODE], regularizer)
biases = tf.get_variable("biases", [LAYER1_NODE], initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights) + biases)
with tf.variable_scope('layer2'):
weights = get_weight_variable([LAYER1_NODE, OUTPUT_NODE], regularizer)
biases = tf.get_variable("biases", [OUTPUT_NODE], initializer=tf.constant_initializer(0.0))
layer2 = tf.matmul(layer1, weights) + biases
return layer2
#通过DataSet的方式获取输入
def get_input():
dataset = tf.data.TFRecordDataset(DATA_PATH)
def parser(record):
features = tf.parse_single_example(
record,
features={
'image_raw':tf.FixedLenFeature([],tf.string),
'pixels':tf.FixedLenFeature([],tf.int64),
'label':tf.FixedLenFeature([],tf.int64)
}
)
decode_image = tf.decode_raw(features['image_raw'],tf.uint8)
reshape_image = tf.reshape(decode_image,[784])
retype_image = tf.cast(reshape_image,tf.float32)
label = tf.cast(features['label'],tf.int32)
return retype_image,label
dataset = dataset.map(parser).shuffle(buffer_size=10000).repeat(100).batch(BATCH_SIZE)
iterator = dataset.make_one_shot_iterator()
features,labels = iterator.get_next()
return features,labels
#获取计算前向传播总的损失
def get_loss(x,y_,regularizer,scope):
with tf.variable_scope(scope,reuse=tf.AUTO_REUSE):
y = inference(x,regularizer)
cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=y_))
regularization_loss = tf.add_n(tf.get_collection('losses'))
loss = cross_entropy + regularization_loss
return loss
#获取所有张量的平均梯度
def average_gradients(tower_grads):
#tower_grads的格式[[('var1',1.0),('var2',2.0)],[('var1',2.0),('var2',1.0)]]
average_grads = []
#*tower_grads:[('var1',1.0),('var2',2.0)],[('var1',2.0),('var2',1.0)]
#zip(*tower_grads):[[('var1',1.0),('var1',2.0)],[('var2',2.0),('var2',1.0)]]
for grad_and_vars in zip(*tower_grads):
grads = []
for g,_ in grad_and_vars:
expended_g = tf.expand_dims(g,0)
grads.append(expended_g)
grad = tf.concat(grads,0)
grad = tf.reduce_mean(grad,0)
v = grad_and_vars[0][1]
grad_and_var = (grad,v)
#average_grads:[('var1',1.5),('var2',1.5)]
average_grads.append(grad_and_var)
return average_grads
def main(_):
#将前向传播和反向传播放在GPU中,其他操作放在CPU中
with tf.Graph().as_default(),tf.device('/cpu:0'):
x,y_ = get_input()
print(x)
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
global_step = tf.get_variable('global_step',[],initializer=tf.constant_initializer(0),trainable=False)
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
60000/BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True
)
opt = tf.train.GradientDescentOptimizer(learning_rate)
tower_grads = []
#将相同的操作放在不同的GPU上
#opt的compute_gradients和apply_graditents根据自己的需求计算并更新梯度
for i in range(N_GPU):
with tf.device('/gpu:%d'%i):
with tf.variable_scope('GPU_%d'%i) as scope:
cur_loss = get_loss(x,y_,regularizer,scope)
grads = opt.compute_gradients(cur_loss)
tower_grads.append(grads)
#获取平均梯度
grads = average_gradients(tower_grads)
for grad,var in grads:
if grad is not None:
tf.summary.histogram('gradients_on_average/%s'%var.op.name,grad)
#更新张量
apply_gradient_op = opt.apply_gradients(grads,global_step)
for var in tf.trainable_variables():
tf.summary.histogram(var.op.name,var)
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
ema_op = ema.apply(tf.trainable_variables()+tf.moving_average_variables())
train_op = tf.group(apply_gradient_op,ema_op)
saver = tf.train.Saver()
summary_op = tf.summary.merge_all()
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=True)) as sess:
sess.run(tf.global_variables_initializer())
summary_writer = tf.summary.FileWriter(MODEL_SAVE_PATH,sess.graph)
for step in range(TRAINING_STEPS):
start_time = time.time()
_,loss_value = sess.run([train_op,cur_loss])
duration = time.time() - start_time
if step != 0 and step % 10 == 0:
num_examples_per_step = BATCH_SIZE * N_GPU
examples_per_sec = num_examples_per_step / duration
sec_per_batch = duration / N_GPU
print('{}: step {},loss={:.2f}({:.1f} example/sec;{:.3f} sec/batch)'.format(
datetime.now(),step,loss_value,examples_per_sec,sec_per_batch
))
summary = sess.run(summary_op)
summary_writer.add_summary(summary,step)
if step % 1000 == 0 or (step+1) == TRAINING_STEPS:
checkpoint_path = os.path.join(MODEL_SAVE_PATH,MODEL_NAME)
saver.save(sess,checkpoint_path,global_step=step)
if __name__ == '__main__':
tf.app.run()