并行计算:用很多台电脑去共同完成计算,每一个参与计算的电脑叫节点。
并行计算的方法(3步):
1、 将数据拆分到每个节点上
思考:如何拆分,一共有几个节点,每个节点能承受的数量是多大,拆分能保证每个节点独立的计算(不能一个节点上的数据依赖另一个节点的数据)
2、 每个节点并行的计算出结果
思考:每个节点要算出一个什么结果,最后来汇总
3、 将结果汇总
思考:通过每个节点的结果来汇总出最后想要的结果。

外部排序(如何排序10G个元素)
方法:扩展的归并排序
归并排序:将数据分为左右两半,分别归并排序,再把两个有序数据归并。
如何归并:
[1,3,6,7],[1,2,3,5]->1
[3,6,7],[1,2,3,5]->1
[3,6,7],[2,3,5]->2
[3,6,7],[3,5]->3
…..
两边最小的数作比较,最小的数是哪一个,把最小的放出来,当两边一样大的时候,选择左边那个。
外部排序:

并行计算的思路:把数据分成很多段,第一步,把数据进行切分,每一段送给一个节点去进行排序,每一段数据量小到在内存里放得下,然后各节点做普通排序就可以了(归并、快排…),排完之后,每个节点的结果都是有序的序列。
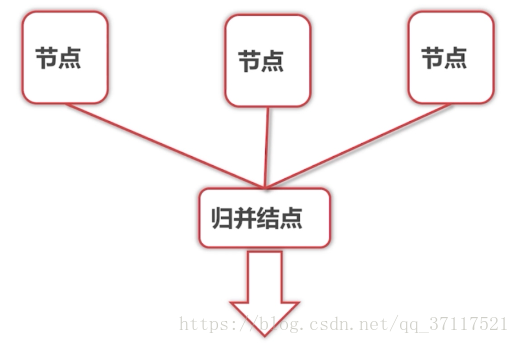
归并节点:再每个序列里一直选最小的数出来
归并节点的实现:
K路归并:

优化出一个堆
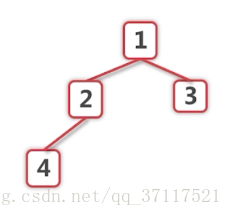
堆的好处:树根是最小的数(在1拿走后,看左右儿子,谁小谁就是新的树根,然后递归2的左右儿子)(顺着树根一直比下去,logN就能取出)
K路归并-库里的另一种实现:PriorityQueue(原理:优先队列)
分别把最小的push()进去,然后pop()一个补一个
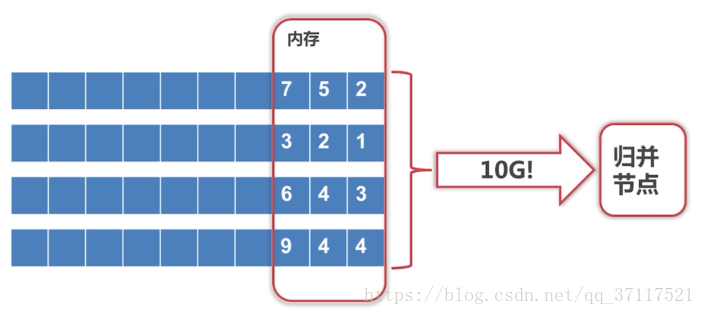
把一部分数据放入内存,可以作为缓冲区,不用每次补元素的时候都从硬盘取过来(这样比较慢)。
归并节点非常复杂,有个归并算法,还有PriorityQueue的数据结构要维护,从数据源取数据还不是一口气拿的,有时候从内存里拿,有时候从硬盘上拿。所以归并节点的程序写出来会很复杂,很难写。还好有Iterable<T>接口
归并:使用Iterable<T>接口
1、 可以不断获取下一个元素的能力
2、 元素存储/获取方式被抽象,与归并节点无关。
3、 Iterable<T> merge(List<Iterable<T>>sortedDate);
结构:
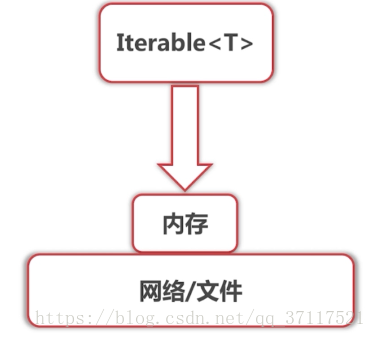
归并数据源来自Iterable<T>.next()
先充每一个数据源调用next获取他们最小的元素,加到PriorityQueue里面去,然后不断从PriorityQueue里面pop()一个元素,pop()完后再获得这个pop()元素的数据源,以此来获得下一个元素。
1、 如果缓冲区空,读取下一批元素放入缓冲区
2、 给出缓冲区第一个元素
3、 可配置项:缓冲区大小,如何获取下一批元素
好处:归并节点就不需要考虑缓冲区的情况,只要不断跟每个数据源调next即可