参考文献:
《深入浅出DPDK》
https://www.cnblogs.com/LubinLew/p/cpu_affinity.html
......................................................................
前言:
处理器提高性能主要是通过两个途径,一个是提高IPC(CPU每一时钟周期内所执行的指令多少),另一个是提高处理器的主频率。每一代微架构的调整都伴随着对IPC的提高,从而提高处理器的性能,只是提升幅度有限。但是提高处理器主频率对于性能的提升作用史明显而且直接的。但是一味的提高主频很快会触及频率墙,因为功耗正比与主频的三次方
所以最终我们还是回到了提升IPC的方式上做突破,后来发现通过提高指令的并行度来提高IPC来提高IPC,而提高并行度有两个方法,一种是提高微架构的指令并行度,另一种是采用多核并发,下面我们就了解DPDK是如何利用这两种方式提高性能的
一. 多核性能和可扩展性
多核处理器是指一个处理器中集中两个或者多个完整的内核(及计算引擎), 如果把处理器性能伴随着频率的提升看作是垂直扩展,那么多核处理器的出现使得性能水平扩展成为可能。原本在单核上执行的任务按照逻辑划分为若干个子任务,分别在不同的核上并行执行,在任务颗粒度上使得指令执行的并行度得到提升
那么随着核数的增加,性能是否会持续提升呢????Amdahl定律说:假如一个任务的工作量不变,多核并行计算理论时的延时加速上取决于那些不能并行处理部分的比例,也就是说不能完全依赖核数的数量让性能一直线性提高
对于DPDK的主要领域--数据包处理, 多核场景并不是完成一个固定的工作量任务,更关注单位时间内的吞吐量。Gustafson定律对于固定时间下的推导给我们更多的指导意义,多核并行计算的吞吐率随着核数的增加而线性扩展,可并行处理器部分占整个任务比重越高,则增长的斜率越大。DPDK或许就是利用的这一点来提高性能的
二. 亲和性
CPU亲核性就是指在Linux系统中能够将一个或多个进程绑定到一个或多个处理器上运行.
一个进程的CPU亲合力掩码决定了该进程将在哪个或哪几个CPU上运行.在一个多处理器系统中,设置CPU亲合力的掩码可能会获得更好的性能
在linux内核中,所有的线程都有一个相关的数据结构,称为task_struct。linux内核API提供了一些方法让用户可以修改位掩码或者查看当前的位掩码
- sched_set_affinity():用来修改位掩码
- sched_get_affinity():用来查看当前的位掩码
注意:cpu_affinity会被传递给子线程,因此应该适当调用sched_set_affinity
为什要介绍亲核性呢?为什么DPDK使用亲核性呢?
将线程与cpu绑定,最直观的好处是提高了CPU Cache 的命中率,从而减少内存访问损耗,提高程序速度
我们简单用个例子来看一下affinity 如何使用的
这个例子来源于Linux的man page.
1 #define _GNU_SOURCE 2 #include <pthread.h> //不用再包含<sched.h> 3 #include <stdio.h> 4 #include <stdlib.h> 5 #include <errno.h> 6 7 #define handle_error_en(en, msg) \ 8 do { errno = en; perror(msg); exit(EXIT_FAILURE); } while (0) 9 10 int 11 main(int argc, char *argv[]) 12 { 13 int s, j; 14 cpu_set_t cpuset; 15 pthread_t thread; 16 17 thread = pthread_self(); 18 19 /* Set affinity mask to include CPUs 0 to 7 */ 20 CPU_ZERO(&cpuset); 21 for (j = 0; j < 8; j++) 22 CPU_SET(j, &cpuset); 23 24 s = pthread_setaffinity_np(thread, sizeof(cpu_set_t), &cpuset); 25 if (s != 0) 26 { 27 handle_error_en(s, "pthread_setaffinity_np"); 28 } 29 30 /* Check the actual affinity mask assigned to the thread */ 31 s = pthread_getaffinity_np(thread, sizeof(cpu_set_t), &cpuset); 32 if (s != 0) 33 { 34 handle_error_en(s, "pthread_getaffinity_np"); 35 } 36 37 printf("Set returned by pthread_getaffinity_np() contained:\n"); 38 for (j = 0; j < CPU_SETSIZE; j++) //CPU_SETSIZE 是定义在<sched.h>中的宏,通常是1024 39 { 40 if (CPU_ISSET(j, &cpuset)) 41 { 42 printf(" CPU %d\n", j); 43 } 44 } 45 exit(EXIT_SUCCESS); 46 }
除了affinity, linux 还提供了一个命令可以绑定:taskset
man taskset出现
CPU affinity is a scheduler property that "bonds" a process to a given set of CPUs on the system. The Linux scheduler will honor the given CPU affinity and the process will not run on any other CPUs. Note that the Linux scheduler also supports natural CPU affinity:
翻译:
taskset设定cpu亲和力,cpu亲和力是指
CPU调度程序属性关联性是“锁定”一个进程,使他只能在一个或几个cpu线程上运行。 对于一个给定的系统上设置的cpu。给定CPU亲和力和进程不会运行在任何其他CPU。注意,Linux调度器还支持自然CPU关联:(不能让这个cpu只为这一个进程服务)
这里要注意的是我们可以把某个程序限定在某一些CPU上运行,但这并不意味着该程序可以独占这些CPU,其实其他程序还是可以利用这些CPU运行。如果要精确控制CPU,taskset就略嫌不足,cpuset才是可以
选项以及使用:
-a, --all-tasks 操作所有的任务线程-p, --pid 操作已存在的pid-c, --cpu-list 通过列表显示方式设置CPU
(1)指定1和2号cpu运行25718线程的程序
taskset -cp 1,2 25718
(2),让某程序运行在指定的cpu上 taskset -c 1,2,4-7 tar jcf test.tar.gz test
(3)指定在1号CPU上后台执行指定的perl程序
taskset –c 1 nohup perl pi.pl &
三. DPDK 的多线程
DPDK的多线程是基于pthread接口创建的,属于抢占式线程模型,受内核支配。DPDK通过在多核设备上创建多个线程,每个线程绑定到单独的核上,减少线程调度的开销,来提高性能
DPDK可以作为控制线程也可以作为数据线程,控制线程一般绑定到主核上,受用户配置,传递配置参数给数据线程,数据线程分布在不同核上处理数据包
1)EAL中的lcore
DPDK的lcore指的是EAL线程,本质是基于pthread 封装实现。Lcore由remote_launch函数指定任务创建并管理,每个EAL pthread 中,有一个TLS称为_lcore_id。当DPDK的EAL 'c' 参数指定coremask的时候,EAL pthread 生成相应个数的lcore并默认是1:1 亲和到coremask 对应的cpu逻辑核,_lcore_id 和 CPU ID是一致的
在这里我们简单介绍一下lcore的初始化:
1) rte_eal_cpu_init() 函数中,读取 /sys/devices/system/cpu/ 下的信息, 确定当前每个核属于那个CPU Socket
2)eal_parse_args()函数,解析-c 参数,确定那些CPU核是可以使用的
3)给每个SLAVE核创建线程,调用eal_thread_set_affinity() 绑定CPU。
注册:
不同模块需要调用rte_dal_mp_remote_launch(),将自己的回调函数注册到lcore_config[].f中,以了l2fwd为例,注册回调处理函数是:
l2fwd_launch_on_lcore()
四. lcore亲和性
默认情况下,lcore和逻辑核是一一绑定的,带来性能提升的同时也牺牲了一定的灵活性
下图是多线程的场景图:
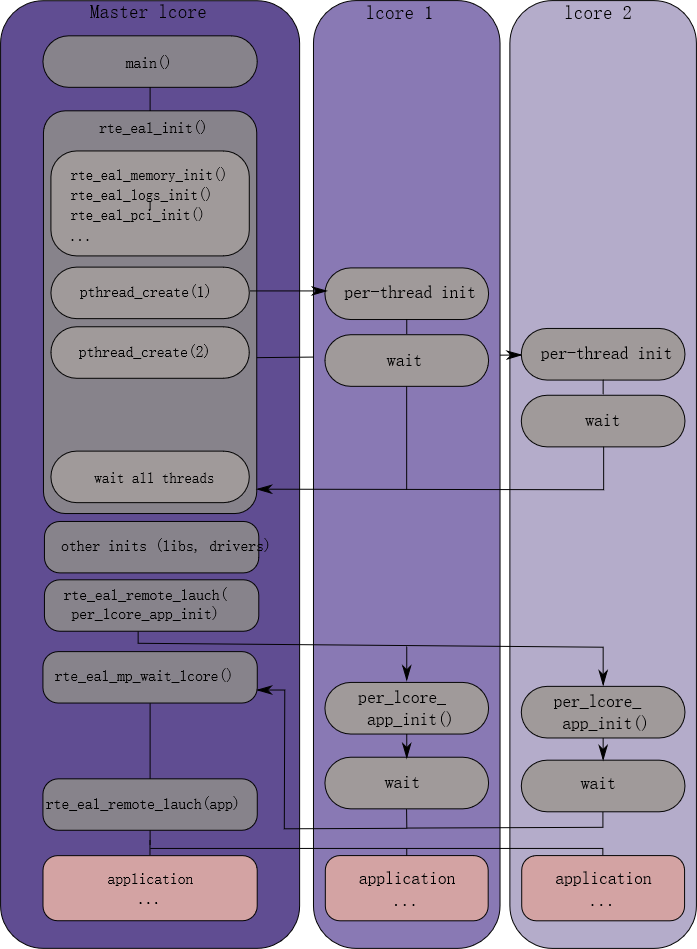
下面解析一下代码如何处理运作的: