上一篇博客介绍了mapreduce的移动流量分析的实战案例,本篇将继续分享mapreduce的并行度原理。
一、mapTask并行度的决定机制
一个job的map阶段并行度由客户端在提交Job是决定,而客户端对map阶段并行度的规划的基本逻辑为:将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每一个split分配一个mapTask并行实例处理;这段逻辑及形成的切片规划描述文件,由FileInputFormat实现类的getSplits()方法完成,其过程如下图:
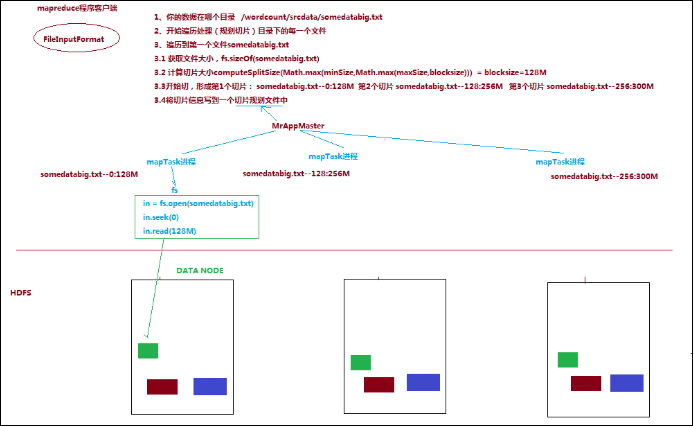
(1)FileInputFormat切片机制
切片定义在InputFormat类中的getSplit()方法;FileInputFormat中默认的切片机制:a.简单地按照文件的内容长度进行切片,b.切片大小,默认等于block大小,c.切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
比如待处理数据有两个文件:
file1.txt 320M
file2.txt 10M
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.txt.split1-- 0~128
file1.txt.split2-- 128~256
file1.txt.split3-- 256~320
file2.txt.split1-- 0~10M
(2)FileInputFormat中切片的大小的参数配置
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize)); 切片主要由这几个值来运算决定
minsize:默认值:1 配置参数: mapreduce.input.fileinputformat.split.minsize
maxsize:默认值:Long.MAXValue 配置参数:mapreduce.input.fileinputformat.split.maxsize
blocksize
因此,默认情况下,切片大小=blocksize
maxsize(切片最大值):参数如果调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值
minsize (切片最小值):参数调的比blockSize大,则可以让切片变得比blocksize还大
选择并发数的影响因素:1、运算节点的硬件配置,2、运算任务的类型:CPU密集型还是IO密集型,3、运算任务的数据量
(3)map并行度的经验之谈
如果硬件配置为2*12core + 64G,恰当的map并行度是大约每个节点20-100个map,最好每个map的执行时间至少一分钟。
如果job的每个map或者 reduce task的运行时间都只有30-40秒钟,那么就减少该job的map或者reduce数,每一个task(map|reduce)的setup和加入到调度器中进行调度,这个中间的过程可能都要花费几秒钟,所以如果每个task都非常快就跑完了,就会在task的开始和结束的时候浪费太多的时间。
配置task的JVM重用[JVM重用技术不是指同一Job的两个或两个以上的task可以同时运行于同一JVM上,而是排队按顺序执行。]可以改善该问题:
(mapred.job.reuse.jvm.num.tasks,默认是1,表示一个JVM上最多可以顺序执行的task数目(属于同一个Job)是1。也就是说一个task启一个JVM)
如果input的文件非常的大,比如1TB,可以考虑将hdfs上的每个block size设大,比如设成256MB或者512MB
二、ReduceTask并行度的决定
reducetask的并行度同样影响整个job的执行并发度和执行效率,但与maptask的并发数由切片数决定不同,Reducetask数量的决定是可以直接手动设置:
//默认值是1,手动设置为4
job.setNumReduceTasks(4); 如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜
注意: reducetask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个reducetask
尽量不要运行太多的reduce task。对大多数job来说,最好rduce的个数最多和集群中的reduce持平,或者比集群的 reduce slots小。这个对于小集群而言,尤其重要。
三、mapreduce调试
可以在本地运行mapreduce,配置远程的namenode主机对应的输入路径和输出路径进行远程调试,调试入口: boolean res = job.waitForCompletion(true);
强烈建议小伙伴们进行一次完整的调试以理解mapreduce的切片规划和提交原理。
四、切片规划
切片规划是一般会形成几个文件: job.xml(hadoop配置参数)、job.split(切片信息)、job.splitmetainfo(切片meta信息)
最后寄语,以上是博主本次文章的全部内容,如果大家觉得博主的文章还不错,请点赞;如果您对博主其它服务器大数据技术或者博主本人感兴趣,请关注博主博客,并且欢迎随时跟博主沟通交流。