1 . MapTask并行度决定机制
maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度。那么,mapTask并行实例是否越多越好呢?其并行度又是如何决定呢?
mapTask并行度的决定机制
map阶段的并行度由客户端在提交job时决定,而客户端对map阶段并行度的规划的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),这里区分hdfs上的blk物理分块,然后每一个split分配一个mapTask并行实例处理。
这段逻辑及形成的切片规划描述文件job.split,都是由FileInputFormat实现类的**getSplits()**方法完成,其过程如下图:
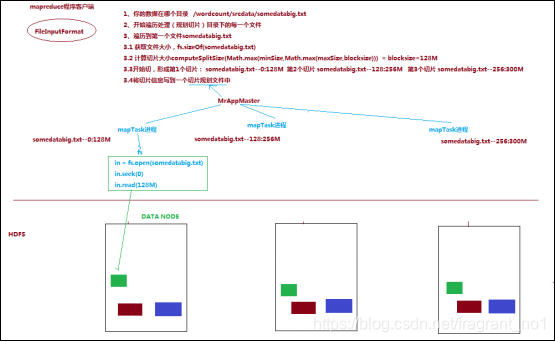
FileInputFormat切片机制
- FileInputFormat中默认的切片机制
1,切片大小,默认等于block的默认大小128M;
2,切片时不考虑数据集整体,而是逐个针对每一个文件单独切片;

- FileInputFormat中切片的大小的参数配置
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize)); 切片主要由这几个值来运算决定,所以可以手动更改配置。

源码解析原理流程图:
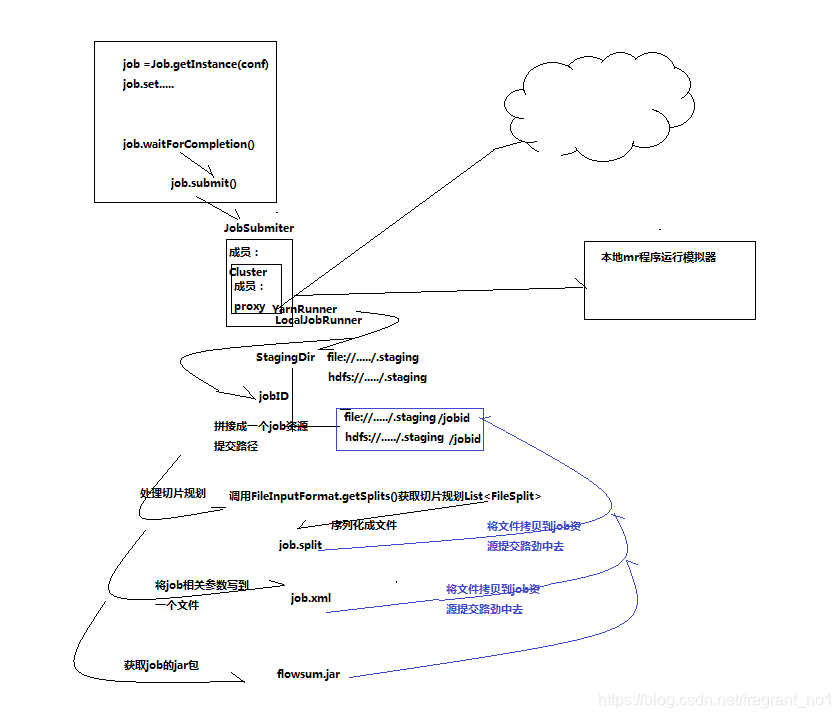
流程图说明:
1,job提交方法waitForCompletion()内部调用的还是submit,然后submit里面有调用jobSubmiter对象。
2,jobSubmiter对象中持有成员Cluster,而其中又持有一个代理对象成员,根据提交本地还是服务器分为:
LocalJobRunner,YarnRunner。
3,然后连接yarn/本地模拟器后会得到一个代理对象,然后返回一个提交资源的路径StagingDir,并拿到一个jobID。
4,客户端根据StagingDir,jobID拼接成一个最终的job资源提交路径,然后分别处理逻辑切片规划,job配置整理,jar上传的工作,具体如图所示。
补充说明:
1,maptask内部切片核心规则是:当前文件剩余长度/切片长度>1.1才会进行下一个切片,反之就会将剩余的部分作为一个切片,而不会在分成两个切片了。比如:默认128M切片大小,而文件剩余130M,那么不满足>1.1的比例,所以会将剩余的130M都放在一个切片中。
2 . ReduceTask并行度的决定
reducetask的并行度同样影响整个job的执行并发度和执行效率,但与maptask的并发数由切片数决定不同,Reducetask数量的决定是直接手动设置的;
/默认值是1,可以手动设置为6
job.setNumReduceTasks(6);
如果数据的采集分布不均匀,就有可能在reduce阶段产生数据倾斜,比如reducetask1中处理的数据比较多,而且他的reducetask处理的数据比较少,这跟具体数据源的数据分布有关。
注意:
1,reducetask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个reducetask;
2,maptask分几个区,那么一般reducetask就对应有几个,其比例可以:1:1,N:1,1:N,但是不能出现reducetask的数量不为1,而且少于分区数的情况,这样框架就不知道该分给谁。如果reducetask的数量多于分区数,那么其他分区就产生一个空文件。
3,尽量不要运行太多的reduce task。
其他问题说明:
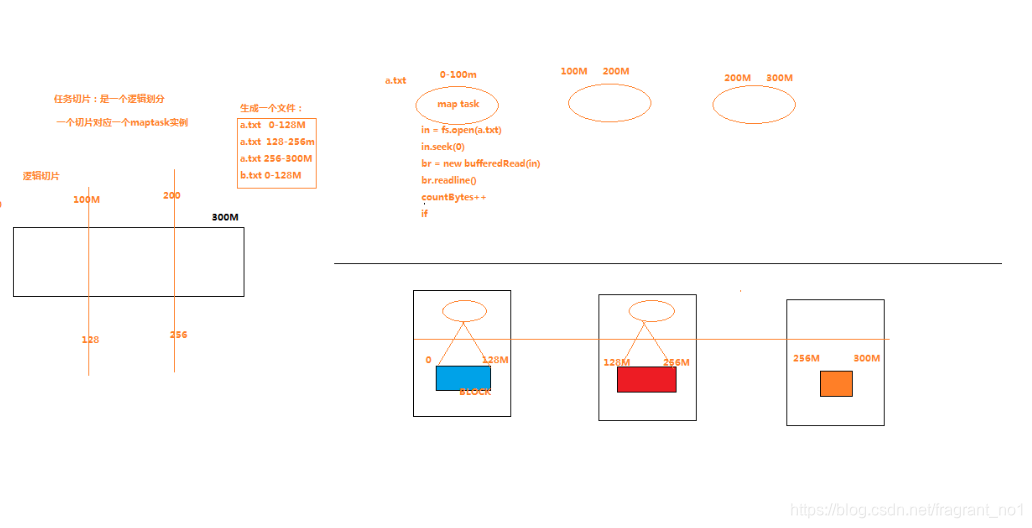
说明:
1,客户端的逻辑分片和hdfs的blk物理分片互不相关,没有任何关系,所以客户端在分片大小上可以任意选取。