1. JOIN
1.1 join操作
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.userid = u.userid); 1.2 MR过程
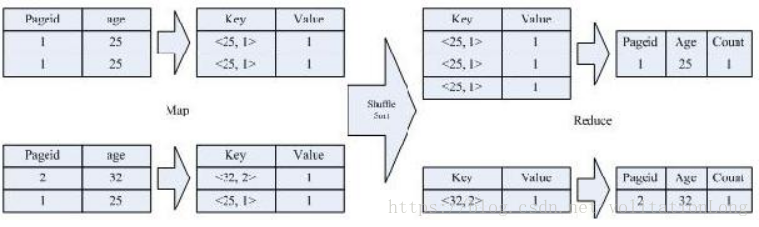
- Map
a. 以 JOIN ON 条件中的列作为 Key,如果有多个列,则 Key 是这些列的组合。
b. 以 JOIN 之后所关心的列作为 Value,当有多个列时,Value 是这些列的组合。
在 Value 中还会包含表的 Tag 信息,用于标明此 Value 对应于哪个表。
c. 按照 Key 进行排序。
- Shuffle
根据 Key 的值进行 Hash,并将 Key/Value 对按照 Hash 值推至不同对 Reduce 中。
- Reduce
Reduce根据 Key 值进行 Join 操作,并且通过 Tag 来识别不同的表中的数据。
1.3 MR过程图
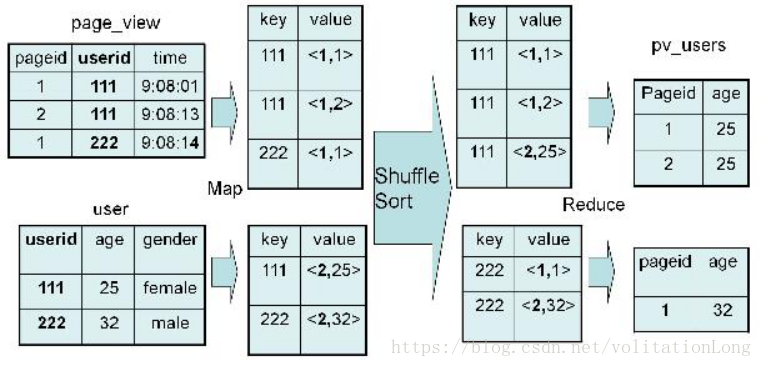
2. GROUP BY
2.1 group by操作
SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;2.2 MR过程图
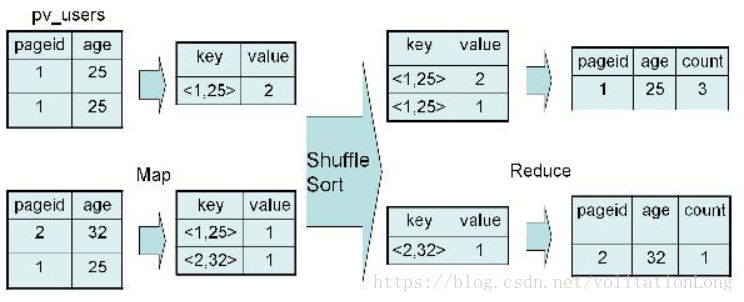
3. DISTINCT
3.1 distinct操作
SELECT age, count(distinct pageid) FROM pv_users GROUP BY age; 3.2 MR过程图