分布式一致性算法paxos & raft
1 paxos算法
paxos算法通过多个监督者来增强可靠性
- 通过监督者投票表决状态变化
- 保证所有数据访问都遵从这种表决
多数派写
客户端写入 W >= N/2 + 1个节点,节点之间平等
多数派读
W + R > N; R >= N/2 + 1
容忍最多(N - 1) / 2个节点损坏
法定集合
将一个超过半数的节点集合成为法定集合。
法定集合的性质:任意两个法定集合,必定存在一个公共成员。
法定集合的性质是paxos算法的有效保障,paxos基于法定集合的原理
安全原则
按照paxos算法,在来自提议N的值v未来或者已经被接受的情况下,不会有一个M>N的提议提出一个不同的值u
paxos ID生成算法
s = m * n + ir
n是节点个数,m是轮数,ir是节点编号,通过增加m,使得后者的ID比前者的ID大
paxos解决活锁问题
id生成算法会造成活锁问题,即一直相互等待,节点的编号越来越大,解决办法是选取一个proposal作为leader,所有的proposal都通过leader提交。
2 Raft算法
分布式系统中的强一致性算法
日志
每一台机器保存一份日志,日志来源于客户请求
raft算法日志内容
- 一条用于状态机的指令
- 从leader收到本日志项的term号
- 在自己本机中的index值
复制状态机
复制状态机会按照日志的顺序执行这些日志
一致性模型
分布式环境下,保证多机的日志一致,从而回放到状态机中的状态是一致的
任期term
每一个任期都是一个选举,选出一个leader,如果没选出,term号自增
Raft日志变更
- 已提交的日志不可改变
- 未提交的日志可以被更新成其他日志
leader只能在日志中添加新条目,不能覆盖和删除条目
leader选举
- followers只对日志长度大于等于自己的candidate投票
- 只有包含所有已提交日志的candidate才能成为leader
Raft日志广播
- leader发送日志到follower,但不提交
- 多半以上的follower应答后,leader更新自己的commit index,再广播commit index到follower
Raft算法过度配置
不需要将服务器下线,重新配置,上线
过度配置好处
- 让集群在配置转换中依然能够相应服务器的请求
- 允许各个服务器在不影响安全性前提下,各自在不同的时间进行配置转换
过度配置能够保证在配置变更过程中,不会出现两个leader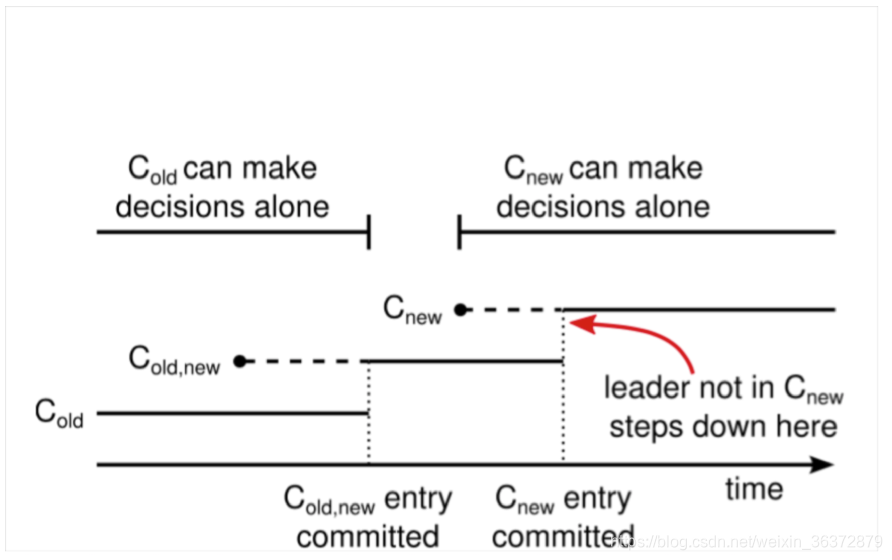
过度配置流程
- leader收到从c(old)到c(new)的请求
- 创建日志c(old-new)
- 广播c(old-new),检查是否达到多数派
- c(old-new)达到多数派,commit
- 创建日志c(new)
- 广播c(new),看是否达到多数派
- c(new)达到多数派,commit
- 不在c(new)状态的节点关闭
图中实线表示已经提交的条目,虚线表示创建之后,没达到多数派,未提交的条目,达到多数派之后,就会提交
在1~3步,c(old)为多数派,只有可能c(old)为leader
在4~6步,只有可能含有c(old-new)配置的节点成为leader
在7~8步,只有可能含有c(new)的节点成为leader
始终保证集群只有一个leader