Paxos
写在前面
Google Chubby的作者Mike Burrows说过这个世界上只有一种一致性算法,那就是Paxos,其它的算法都是残次品。
Paxos算法也因为晦涩难懂而臭名昭著。不仅理解它的执行流程,还要理解算法的推导过程,最难得是实现。。。
相关背景及概念
简单说来,Paxos的目的是让整个集群的结点对某个值的变更达成一致。Paxos算法基本上来说是个民主选举的算法——大多数的决定会成个整个集群的统一决定。任何一个点都可以提出要修改某个数据的提案,是否通过这个提案取决于这个集群中是否有超过半数的结点同意(所以Paxos算法需要集群中的结点是单数)。
Proposer :提议者,提出一个提案,等待大家批准为结案
Acceptor:决策者,负责对提案进行投票。
Learner:最终决策学习者,被告知结案结果,并与之统一,不参与投票过程。
在具体的实现中,一个节点可能同时充当多种角色。比如一个节点可能既是Proposer又是Acceptor又是Learner。并且,算法需要满足 safety 和 liveness 两方面的约束要求(实际上这两个基础属性是大部分分布式算法都该考虑的):
- safety:保证决议结果是对的,无歧义的,不会出现错误情况。
- 决议(value)只有在被 proposers 提出的 proposal 才能被最终批准;
- 在一次执行实例中,只批准(chosen)一个最终决议,意味着多数接受(accept)的结果能成为决议;
- liveness:保证决议过程能在有限时间内完成。
- 决议总会产生,并且 learners 能获得被批准(chosen)的决议。
基本过程包括 proposer 提出提案,先争取大多数 acceptor 的支持,超过一半支持时,则发送结案结果给所有人进行确认。一个潜在的问题是 proposer 在此过程中出现故障,可以通过超时机制来解决。极为凑巧的情况下,每次新的一轮提案的 proposer 都恰好故障,系统则永远无法达成一致(概率很小)。
Paxos 能保证在超过1/2的正常节点存在时,系统能达成共识。
一个Accepter
假设只有一个Acceptor(可以有多个Proposer),只要Acceptor接受它收到的第一个提案,则该提案被选定,该提案里的value就是被选定的value。这样就保证只有一个value会被选定。但是,如果这个唯一的Acceptor宕机了,那么整个系统就无法工作了,这类似于主从模式,应用较为广泛。
多个Acceptor
既然单接收者都会出现故障,那么就得允许出现多个提案者和多个接收者。问题一下子变得复杂了。
同一时间片段内可以出现多个提案者。那同一个节点可能收到多份提案,怎么对他们进行区分呢?这个时候采用只接受第一个提案而拒绝后续提案的方法也不适用。很自然的,提案需要带上不同的序号。节点需要根据提案序号来判断接受哪个。比如接受其中序号较大(往往意味着是接受新提出的,因为旧提案者故障概率更大)的提案。
如何为提案分配序号呢?一种可能方案是每个节点的提案数字区间彼此隔离开,互相不冲突。为了满足递增的需求可以配合用时间戳作为前缀字段。
此外,提案者即便收到了多数接收者的投票,也不敢说就一定通过。因为在此过程中系统可能还有其它的提案。
两阶段的提交
提案者发出提案之后,收到一些反馈。一种结果是自己的提案被大多数接受了,另一种结果是没被接受。没被接受的话好说,过会再试试。
即便收到来自大多数的接受反馈,也不能认为就最终确认了。因为这些接收者自己并不知道自己刚反馈的提案就恰好是全局的绝大多数。
很自然的,引入了新的一个阶段,即提案者在前一阶段拿到所有的反馈后,判断这个提案是可能被大多数接受的提案,需要对其进行最终确认。
Paxos 里面对这两个阶段分别命名为准备(prepare)和提交(commit)。准备阶段解决大家对哪个提案进行投票的问题,提交阶段解决确认最终值的问题。
准备阶段:
- 提案者发送自己计划提交的提案的编号到多个接受者,试探是否可以锁定多数接受者的支持。
- 接受者时刻保留收到过提案的最大编号和接受的最大提案。如果收到的提案号比目前保留的最大提案号还大,则返回自己已接受的提案值(如果还未接受过任何提案,则为空)给提案者,更新当前最大提案号,并说明不再接受小于最大提案号的提案。
提交阶段:
- 提案者如果收到大多数的回复(表示大部分人听到它的请求),则可准备发出带有刚才提案号的接受消息。如果收到的回复中不带有新的提案,说明锁定成功,则使用自己的提案内容;如果返回中有提案内容,则替换提案值为返回中编号最大的提案值。如果没收到足够多的回复,则需要再次发出请求。
- 接受者收到接受消息后,如果发现提案号不小于已接受的最大提案号,则接受该提案,并更新接受的最大提案。
一旦多数接受了共同的提案值,则形成决议,成为最终确认的提案。
举个例子
假设这个有三个结点:A,B,C
Prepare阶段
A把申请修改的请求Prepare请求和Sequence Number发给所有的结点A,B,C,这个提案号会和修改请求一同发出,任何结点在“Prepare阶段”时都会拒绝其值小于当前提案号的请求。所以,结点A在向所有结点申请修改请求的时候,需要带一个提案号,越新的提案,这个提案号就越是是最大的。
如果接收结点收到的提案号n大于其它结点发过来的提案号,这个结点会回应Yes(本结点上最新的被批准提案号),并保证不接收其它
Raft
概述
与Paxos不同,Raft相对来说易于理解,在Raft中把复杂的问题分解,分为三个子问题:选举(Leader election)、日志复制(Log replication)、安全性(Safety)。Raft的流程:Raft开始时在集群中选举出Leader负责日志复制的管理,Leader接受来自客户端的事务请求(日志),并将它们复制给集群的其他节点,然后负责通知集群中其他节点提交日志,Leader负责保证其他节点与他的日志同步,当Leader宕掉后集群其他节点会发起选举选出新的Leader。
相关概念
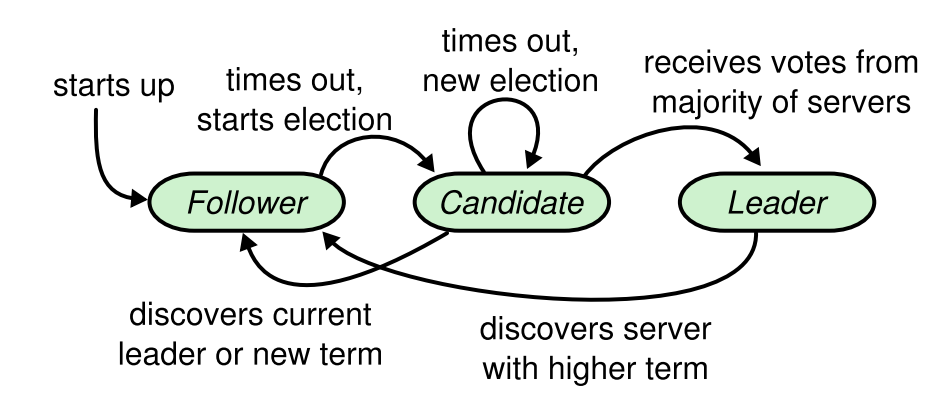
Raft把集群中的节点分为三种状态:Leader、 Follower 、Candidate,理所当然每种状态下负责的任务也是不一样的,Raft运行时只存在Leader与Follower两种状态。
- Leader(领导者):负责日志的同步管理,处理来自客户端的请求,与Follower保持这heartBeat的联系;
- Follower(追随者):刚启动时所有节点为Follower状态。响应Candidate的请求,选举完成后它的责任是响应Leader的日志同步请求,把请求到Follower的事务转发给Leader;
- Candidate(候选者) 负责选举投票,一轮选举开始时节点从Follower转为Candidate发起选举,选举出Leader后从Candidate转为Leader状态;
角色转换图
Term
在Raft中使用了一个可以理解为周期/任期的概念,用Term作为一个周期,每个Term都是一个连续递增的编号,每一轮选举都是一个Term周期,在一个Term中只能产生一个Leader;先简单描述下Term的变化流程: Raft开始时所有Follower的Term为1,其中一个Follower逻辑时钟到期后转换为Candidate,Term加1这是Term为2(任期),然后开始选举,这时候有几种情况会使Term发生改变:
- 如果当前Term(N)的任期内没有选举出Leader或出现异常,则Term递增Term(N+1),开始新一任期选举
- Leader宕掉了,然后其他Follower转为Candidate,Term递增,开始新一任期选举
- 当Leader或Candidate发现自己的Term比别的Follower小时Leader或Candidate将转为Follower,Term递增
- 当Follower的Term比别的Term小时Follower也将更新Term保持与其他Follower一致
每次Term的递增都将发生新一轮的选举,Raft保证一个Term只有一个Leader,在Raft正常运转中所有的节点的Term都是一致的,如果节点不发生故障一个Term(任期)会一直保持下去,当某节点收到的请求中Term比当前Term小时则拒绝该请求;
选举(Election)
有这么几种情况会发起选举,1:Raft初次启动,不存在Leader,发起选举;2:Leader宕机或Follower没有接收到Leader的heartBeat,发生election timeout从而发起选举。
raft初始状态时所有节点都处于Follower状态,并且随机睡眠一段时间,这个时间在0~1000ms之间。最先醒来的节点 A进入Candidate状态,Candidate状态的节点 A有权利发起投票,向其它所有节点发出requst_vote请求,这个过程会有三种结果:
自己被选成了主。当收到了majority的投票后,状态切成leader,并且定期给其它的所有server发心跳消息(其实是不带log的AppendEntriesRPC)以告诉对方自己是current_term_id所标识的term的leader。每个term最多只有一个leader,term id作为logical clock,在每个RPC消息中都会带上,用于检测过期的消息,比如自己是一个过期的leader(term id更小的leader)。当一个server收到的RPC消息中的rpc_term_id比本地的current_term_id更大时,就更新current_term_id为rpc_term_id,并且如果当前state为leader或者candidate时,将自己的状态切成follower。如果rpc_term_id比本地的current_term_id更小,则拒绝这个RPC消息。
别人成为了主。如1所述,当candidate在等待投票的过程中,收到了大于或者等于本地的current_term_id的声明对方是leader的AppendEntriesRPC时,则将自己的state切成follower,并且更新本地的current_term_id。
没有选出主。当投票被瓜分,没有任何一个candidate收到了majority的vote时,没有leader被选出。这种情况下,每个candidate等待的投票的过程就超时了,接着candidates都会将本地的current_term_id再加1,发起RequestVoteRPC进行新一轮的leader election。
投票策略:
每个server只会给每个term投一票,具体的是否同意和后续的Safety有关。
日志复制(Log Replication)
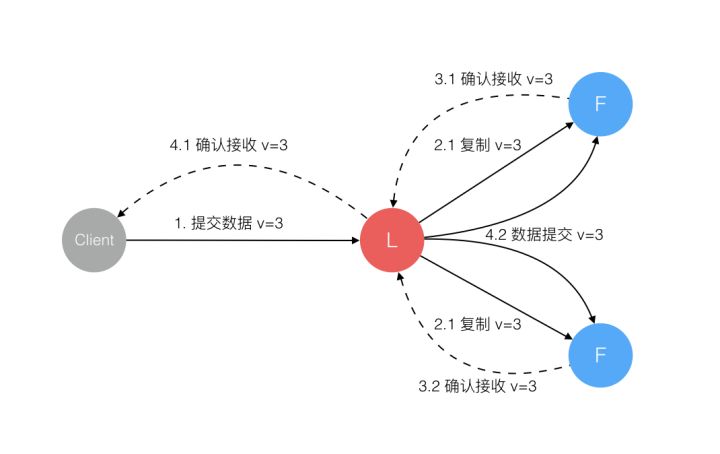
Leader选举出来后,就可以开始处理客户端请求。Leader收到客户端请求后,每个请求包含一条需要被replicated state machines执行的命令。leader会把它作为一个log entry,append到它的日志中。并向其它server发送AppendEntriesRPC(添加日志)请求。其它server收到AppendEntriesRPC请求后,判断该append请求满足接收条件,如果满足条件就将其添加到本地的log中,并给Leader发送添加成功的response。如果某个follower宕机了或者运行的很慢,或者网络丢包了,则会一直给这个follower发AppendEntriesRPC直到日志一致。Leader在收到大多数server添加成功的response后,就将该条log正式提交。提交后的log日志就意味着已经被raft系统接受,并能应用到状态机中了。
当一个新的leader选出来的时候,它的日志和其它的follower的日志可能不一样,这个时候,就需要一个机制来保证日志是一致的。如下图所示,一个新leader产生时,集群状态可能如下:
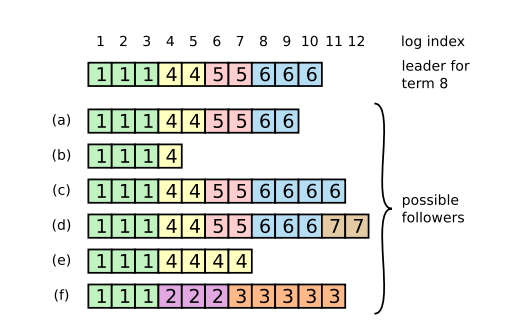
最上面这个是新leader,a~f是follower,每个格子代表一条log entry,格子内的数字代表这个log entry是在哪个term上产生的。
新leader产生后,log就以leader上的log为准。其它的follower要么少了数据比如b,要么多了数据,比如d,要么既少了又多了数据,比如f。
需要有一种机制来让leader和follower对log达成一致,leader会为每个follower维护一个nextIndex,表示leader给各个follower发送的下一条log entry在log中的index,初始化为leader的最后一条log entry的下一个位置。leader给follower发送AppendEntriesRPC消息,带着(term_id, (nextIndex-1)), term_id即(nextIndex-1)这个槽位的log entry的term_id,follower接收到AppendEntriesRPC后,会从自己的log中找是不是存在这样的log entry,如果不存在,就给leader回复拒绝消息,然后leader则将nextIndex减1,再重复,直到AppendEntriesRPC消息被接收。
举个例子
以leader和b为例:初始化,nextIndex为11,leader给b发送AppendEntriesRPC(6,10),b在自己log的10号槽位中没有找到term_id为6的log entry。则给leader回应一个拒绝消息。接着,leader将nextIndex减一,变成10,然后给b发送AppendEntriesRPC(6, 9),b在自己log的9号槽位中同样没有找到term_id为6的log entry。循环下去,直到leader发送了AppendEntriesRPC(4,4),b在自己log的槽位4中找到了term_id为4的log entry。接收了消息。随后,leader就可以从槽位5开始给b推送日志了。
Safety
Raft增加了如下两条限制以保证安全性:
拥有最新的已提交的log entry的Follower才有资格成为Leader。
这个保证是在RequestVoteRPC阶段做的,candidate在发送RequestVoteRPC时,会带上自己的最后一条log entry的term_id和index,server在接收到RequestVoteRPC消息时,如果发现自己的日志比RPC中的更新,就拒绝投票。日志比较的原则是,如果本地的最后一条log entry的term id更大,则更新,如果term id一样大,则日志更多的更大(index更大)。
- Leader只能推进commit index来提交当前term的已经复制到大多数服务器上的日志,旧term日志的提交要等到提交当前term的日志来间接提交(log index 小于 commit index的日志被间接提交)。
之所以要这样,是因为可能会出现已提交的日志又被覆盖的情况:
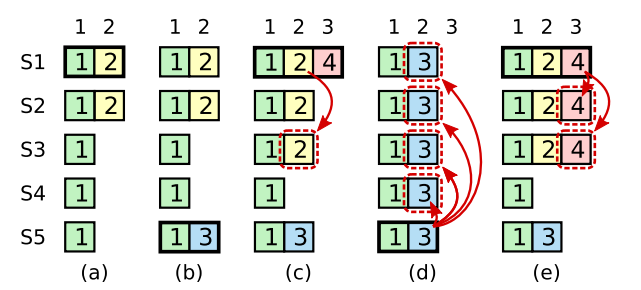
在阶段a,term为2,S1是Leader,且S1写入日志(term, index)为(2, 2),并且日志被同步写入了S2;
在阶段b,S1离线,触发一次新的选主,此时S5被选为新的Leader,此时系统term为3,且写入了日志(term, index)为(3, 2);
S5尚未将日志推送到Followers就离线了,进而触发了一次新的选主,而之前离线的S1经过重新上线后被选中变成Leader,此时系统term为4,此时S1会将自己的日志同步到Followers,按照上图就是将日志(2, 2)同步到了S3,而此时由于该日志已经被同步到了多数节点(S1, S2, S3),因此,此时日志(2,2)可以被提交了。;
在阶段d,S1又下线了,触发一次选主,而S5有可能被选为新的Leader(这是因为S5可以满足作为主的一切条件:1. term = 5 > 4,2. 最新的日志为(3,2),比大多数节点(如S2/S3/S4的日志都新),然后S5会将自己的日志更新到Followers,于是S2、S3中已经被提交的日志(2,2)被截断了。
增加上述限制后,即使日志(2,2)已经被大多数节点(S1、S2、S3)确认了,但是它不能被提交,因为它是来自之前term(2)的日志,直到S1在当前term(4)产生的日志(4, 4)被大多数Followers确认,S1方可提交日志(4,4)这条日志,当然,根据Raft定义,(4,4)之前的所有日志也会被提交。此时即使S1再下线,重新选主时S5不可能成为Leader,因为它没有包含大多数节点已经拥有的日志(4,4)。