分布式系统设计中,几乎都需要在服务可用性性 和数据一致性之间做权衡,也因此诞生了一系列的一致性协议,常见的有2PC一致性协议、3PC一致性协议、Paxos一致性算法、Raft一致性算法。
一、2PC一致性协议
2PC,也叫做二阶段提交协议,是指将在分布式环境下多个分布节点的事务提交过程分成两个阶段来进行处理:
第一个阶段是事务执行,即多个节点先提交,但是不commit事务;
第二个阶段是事务提交,即协调者统计多个节点第一个阶段是否都执行成功,都执行成功再让多个节点commit事务。
(1)阶段一:执行事务
- 协调者节点向多个参与者节点发送事务内容,
- 参与者节点收到命令后就开始执行事务操作,同时将Undo(保证一致性)和Redo(保证事务原子性和持久性)信息记入事务日志中;
- 如果每个节点事务都执行成功,则回复"YES"响应给协调者;否则返回"No"响应。
(2)阶段二:执行事务提交
- 如果协调者节点发现所有参与者节点都返回了"YES"响应,则向所有参与者节点发送"Commit"指令;
- 参与者节点收到"Commit"指令之后,执行事务的提交;事务提交之后向协调者节点发送"ACK"响应;
- 协调者接收到所有"ACK"响应之后,完成整个事务操作。
以电商购买商品为例,减库存和扣减账户金额需要保证事务一致性。正常情况下阶段一、阶段二操作如下:

(3)事务中断
如果在阶段一或阶段二任一节点协调者与参与者失去联系,都要进行事务中断操作。
若在第2个阶段中,协调者发现有节点返回"NO"或者没有接收到所有参与者节点返回的"YES"响应,就会发起事务中断操作。
- 协调者向参与者节点发起"Rollback"请求,进行事务回滚;
- 参与者节点收到Rollback请求后,会利用Undo日志中记录的日志信息进行事务回滚;完成之后返回"ACK";
- 协调者收到所有参与节点的"ACK"响应之后,完成事务中断。

2PC优缺点:
优点:原理简单
缺点:
- 同步阻塞问题:第一、二阶段中,由于协调者等待参与者节点是同步阻塞,即协调者在收到所有参与者的响应之前是不会处理任何请求的,性能差;
- 协调者单点问题:如第一阶段中,如果协调者在向第1节点发送执行事务命令后,还未来得及向第3个参与者节点发送事务执行命令后发生宕机,那么第二个阶段就无法完成,并可能导致参与者节点一直处于锁定事务资源状态中;
- 多个节点数据不一致问题:第二阶段如果协调者发送的’Commit’指令无法保证所有节点都能收到,这样就会出现部分节点Commit事务操作,部分节点未执行导致节点间数据不一致
- 保守:任一个节点响应失败都会进行回滚,影响性能;
二、3PC一致性协议
3PC,三阶段提交,在2PC的基础上优化了阶段一执行事务操作过程,最终形成CanCommit、Precommit和do Commit 三个阶段组成的事务处理协议。
三阶段提交整个流程如下:

三阶段协议看起来与二阶段似乎并无太大差别,但是作为2PC的改进版,3PC与2PC的区别在于:
(1)第一个阶段是不阻塞的,降低了参与者阻塞范围;
(2)3PC对于参与者设置了超时机制(2PC只有协调者有):2PC在第二阶段协调者节点发送Commit操作时,如果协调者节点发生单点故障问题,会导致部分参与者节点接收并执行,部分参与者节点无法接收到不会执行,出现分布式节点数据不一致的问题;而对应的在3PC第三阶段,协调者节点发完doCOmmit操作发生单点故障,部分节点接收、部分节点未接收,为了防止出现数据不一致的问题,在第三节点3PC对参与者节点加上了等待超时的概念,如果部分节点在指定时间内未接收到协调者发送的doCOmmit 操作后,会自动进行事务提交,最终保证所有节点数据一致性;
注:如果3PC第三阶段发送的是中断事务指令,部分节点接收到进行事务回滚,部分节点未接收到等待超时后依然执行doCommit操作,就出现数据不一致情况;
三阶段优缺点
优点:降低参与者的阻塞范围,并且能够在出现单点故障后继续达成一致;
缺点:参与者接收到preCommit消息后,如果此时与协调者发生网络分区,该参与者依然会进行事务的提交。会出现数据的不一致性。
三、Paxos一致性算法
Paxos算法是Leslie Lamport 与1990年提出的基于消息传递且具有高度容错性的一致性算法,用于解决在一个可能发生异常的分布式系统中,如何集群中快速在对某个值达成一致的算法。
在Paxos算法中,有3种角色:Proposer(提议者)、Acceptor(接受者)、Learner(学习者):

-
Proposer(提议者):提案发起者;
-
Acceptor(接受者):提案决策者,对每个提议的值进行投票,并存储接受的值;
-
Learner(学习者):最终决策的学习者,被告知投票的结果,接受达成共识的值进行保存,一般用于数据备份。
关于以上3个角色,我们可以这样形象地去比喻:公司某个广告方案设计会议,Proposer好比公司中多个设计人员就某个广告提出的不同设计方案,而Acceptor好比CEO,去决定选择哪个方案(一般怕CEO突然不来会议或者挂了,会选择多个副的CEO来共同投票选择方案);而Learner就像普通员工,在Acceptor宣布选择哪个方案后,去告知Learner投票结果。
在实际开发场景中,Proposer代表接收到客户端请求,发起二阶段提交,请求对某个值达成一致;Acceptor代表投票选择对提议的值进行投票达成共识的值;学习者不参与共识协商,只接受达成共识的值进行存储保存。一个节点既可以是Proposer也可以是Acceptor。
提案生成
Paxos算法中提案生成主要分为两个阶段(二阶段提交):
(1)阶段一:Proposer生成提案
- Proposer选择一个编号为Mn的提案,向超过半数的Acceptors发出Prepare请求,请求Acceptors对该方案进行投票;
- Acceptors接收到Mn提案后,保证不再响应任何比Mn编号小的提案,同时将接收到的比Mn编号小的最大编号返回给Proposer(假设Mn=M8,Acceptors接收了M7、M5,那么则返回M7);
(2)阶段二:Acceptor接受提案
- 如果Proposer收到半数以上的Acceptors的响应,那么Proposer就提出一个针对提案[Mn, Vn]的Accept的请求给Acceptors,Vn是收到的Acceptors响应中最大的值;
- 如果Acceptors收到这个[Mn, Vn]Accept请求,只要该Acceptor尚未对编号大于Mn的Prepare请求作出相应,就可以通过该提案。
整个过程如下:

下面举一个多个节点就某个值达成一致的过程熟悉Paxos算法。假设节点Node4、Node5、Node6中保存有某件商品数量;客户端Node1、Node2同时发起请求修改该商品数量,假设Node1请求中需要将该商品数量修改为v1;Node2请求中需要将该商品数量修改为v2。
(1)Proposer生成提案:节点Node1、Node分别生成编号为1001、1002的唯一值作为提案。
-
首先Node4、5先收到客户端Node1的请求[1001, ],由于Node4、5之前并未批准任何提案,所以响应给Node1:【Prepare响应:尚未提案】,同时承诺不再响应编号 <= 1002 的提案,不会批准小于 < 1002的提案;;
之后再收到客户端Node2的请求[1002, ],由于Node4、5之前并未批准任何提案,所以也响应给Node2:【Prepare响应:尚未提案】,同时承诺不再响应编号 <= 1002 的提案,不会批准小于 < 1002的提案;
-
Node6先收到客户端Node2的请求[1002, ],由于Node6之前并未批准任何提案,所以响应给Node2:【Prepare响应:尚未提案】,并同时承诺不再响应编号 <= 1002 的提案,不会批准小于 < 1002的提案;
之后再收到客户端Node1的请求[1001, ],由于1001编号比1002小,所以抛弃;

(2)Acceptor接受提案:
-
客户端Node1收到半数接受者的响应后,由于没有指定提案值,所以将自己将要修改的值设置为提案的值:[1001, v1],发起accept请求;同样Node2也发起提案为[1002, v2]的Accept请求;
-
Node4、5、6接收到客户端的Accept请求:[1001, v1], 由于承诺不再批准比1002小的提案,所以抛弃;
接着接收到客户端Node2的Accept请求:[1002, v2], 由于提案1002不比之前承诺的1002小,所以3个节点都通过该提案,将该商品数量改为v2。这样3个节点就达成了一致。

提案获取
当Acceptors选定提案后,Learner需要获取提案。
所有的Acceptors将批准的提案发送特定的Learner,为避免出现单点故障问题,Learner一般设置多个主Learner集群,由主Learner将同步到的结果再同步给其他Learner。

四、Raft一致性算法
Raft算法是目前分布式系统开发选用较多的共识算法,它在Paxos算法的基础上做了简化和限制。
Raft算法的本质是通过领导者为准的方式来实现值的共识和日志的一致。
Raft算法中有3种基本角色:
- Leader(领导者):集群中只有一个,负责处理客户端写请求、管理日志复制和不断地发送心跳消息通知其他节点;
- Candidate(候选人):候选人向其他节点发送RequestVote RPC消息通知其他节点投票,如果赢得大多数选票则晋升为Leader;
- Follower(跟随者):接受和处理Leader的消息;当与Leader心跳超时时就推荐自己当候选人;
Raft算法主要有两个过程:Leader选举和日志复制。
1、Leader选举
(1)Server启动时,各个节点初始状态均为Follower,每个节点会给自己设置一个选举超时时间(一般为150~300ms);
(2)先如果在各自设置的超时时间内收到来自Leader或Candidate的心跳消息,则定时器重启;否则会发起一次选举过程,向其他服务器发出选举自己的请求(先超时的节点先发起投票);
如图,节点A因为超时时间最短,最先因没有收到心跳消息而向其他节点发起投票请求,请求他们选举自己为领导人(增加自己的任期,并推荐自己为候选人)。
(3)其他节点(C、D)在编号为1的任期内未投票,则将选票投给节点A,并增加自己的任期编号;
(4)即使节点B宕机,只要节点A收到半数以上选票(3票)则当选为Leader,并不断发生心跳消息给其他节点,防止其他节点篡权再次发起投票。
当Leader节点发生宕机时,集群会再次发起选举过程。
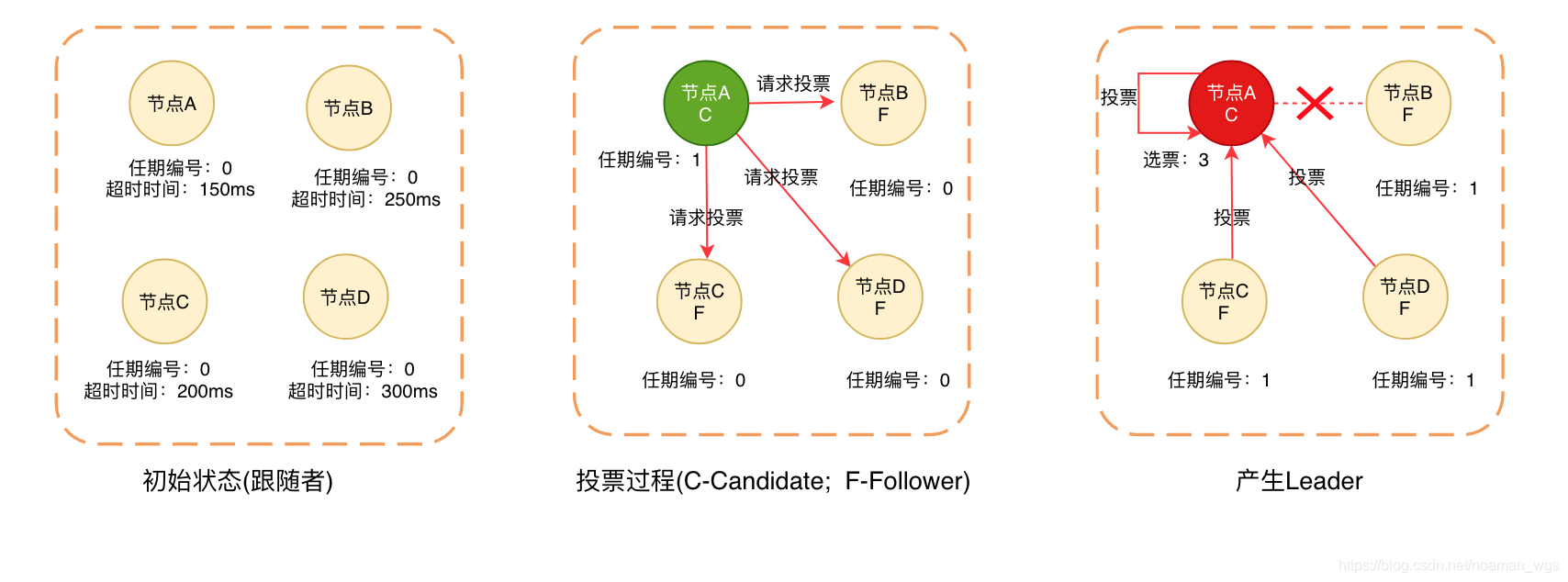
关于Leader选举有如下注意点:
- 节点间通过RPC通信
- 请求投票RPC:候选人发起,用于通知其他节点投票;
- 日志复制RPC:Leader发起,用于复制日志和提供心跳消息;
- 任期:Raft算法中Leader有任期,每次选举都会增加任期。
- 跟随者在超时或者心跳超时,会推荐自己成功Candidate,并且任期+1;
- 当服务器节点收到别的节点的RPC消息时发现自己的任期编号过小,会更新自己的任期编号;
- 如果任期编号为3的Leader节点A因为网络分区,恢复之后,收到任期编号为4的Leader节点B的心跳消息,节点A会立即变成跟随者状态;
- 如果节点收到比自己任期编号小的请求,会直接拒绝;
- 选举规则
- 一个服务器节点对同一个任期编号只会投一次票,遵循“先到先得”的原则;
- 日志完整性高的跟随者拒绝投票给低的跟随者;
- 超时时间
- 如果选举过程中出现刚好票数均匀导致选举失败的情况,会给每个节点设置超时时间,达到只有一个服务器节点先发起选举,避免选举失败的情况;
2、日志复制
Raft算法中,Leader节点收到来自客户端请求后,会将处理过程中以复制和应用日志项到状态机中。为了实现数据一致性,会将日志同步到跟随者节点中,副本数据是以日志的形式存在。Raft中日志必须是连续的。
Raft算法中日志项是一种数据格式,包括指令、索引值、任期编号等,如下:

(图片来源:https://time.geekbang.org/column/article/205784)
-
指令:客户端请求指定的数据;
-
索引值:日志项对应的索引值,连续、单调递增,用来标识日志项;
-
任期编号:创建日志项的领导者的任期编号;
那么领导者是如何将日志项复制到别的客户端上呢?
- 首先,领导者节点收到客户端请求后创建一个新日志项,追加到本地日志中,然后通过日志复制RPC将新的日志项复制到其他跟随者服务器;
- 跟随者节点收到日志复制RPC请求后,会将日志复制到本地,并返回响应给领导者节点;
- 领导者收到一半以上跟随者响应后,会将日志项应用到状态机中(理解为提交),并将执行结果返回给客户端;
- 领导者将日志项应用到日志项中之后,没有必要发送消息通知跟随者,而是通过心跳响应或者下次的日志RPC消息,通知跟随者将该日志项应用到其本地状态机中;

注意:如果在日志复制过程中,领导者会通过日志复制RPC一致性检查,找到跟随者节点上与自己相同日志项的最大索引值,然后通过复制并更新覆盖索引值之后的日志项,实现节点间日志的一致。
Raft算法和Paxos算法的区别
- Raft算法中不是所有节点都能当选领导者,只有日志较为完整的节点(即日志完整度不比半数节点低的节点)才能当选领导者;
- 日志必须是连续的。