背景
在一个分布式系统中,如何保证集群中所有节点中的数据完全相同并且能够对某个提案(Proposal)达成一致是分布式系统正常工作的核心问题,而共识算法就是用来保证分布式系统一致性的方法。
然而分布式系统由于引入了多个节点,所以系统中会出现各种非常复杂的情况;随着节点数量的增加,节点失效、故障或者宕机就变成了一件非常常见的事情,解决分布式系统中的各种边界条件和意外情况也增加了解决分布式一致性问题的难度。
在一个分布式系统中,除了节点的失效是会导致一致性不容易达成的主要原因之外,节点之间的网络通信收到干扰甚至阻断以及分布式系统的运行速度的差异都是解决分布式系统一致性所面临的难题。
CAP
在 1998 年的秋天,加州伯克利大学的教授 Eric Brewer 第一次发布了 CAP 理论,在 1999 年论文 Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services 正式发布,其中总结了 Eric Brewer 提出的 CAP 理论。
CAP即:保证一致性(Consistency)、可用性(Availability)和分区容错性(Partition-tolerance) 。在异步的网络模型中,所有的节点由于没有时钟仅仅能根据接收到的消息作出判断,每一个系统只能在这三种特性中选择两种。
不过这里讨论的一致性其实都是强一致性,也就是所有节点接收到同样的操作时会按照完全相同的顺序执行,被一个节点提交的更新操作会立刻反映在其他通过异步或部分同步网络连接的节点上,如果想要同时满足一致性和分区容错性,在异步的网络中,我们只能中心化存储所有数据,通过其他节点将请求路由给中心节点达到这两个目的。
但是在现实世界中其实并不存在绝对异步的网络环境,如果我们允许每一个节点拥有自己的时钟,这些时钟虽然有着完全不同的时间,但是它们的更新频率是完全相同的,所以我们可以通过时钟得知接收消息的间隔时间,在这种更宽松的前提下,我们能够得到更强大的服务。
然而在部分同步的网络环境中,我们仍然没有办法同时保证一致性、可用性和分区容错性,证明的过程其实非常简单,可以直接阅读 论文 的 4.2 节,然而时钟的出现能够让我们知道当前消息有多久没有得到回应,通过超时时间就能在一定程度上解决信息丢失的问题。
由于网络一定会存在延时,所以没有办法在分布式系统中做到强一致性的同时保证可用性,不过我们可以通过降低对一致性的要求,在一致性和可用性之间做出权衡,而这其实也是设计分布式系统首先需要考虑的问题,由于强一致性的系统会导致系统的可用性降低,仅仅将接受请求的工作交给其他节点对于高并发的服务并不能解决问题,所以在目前主流的分布式系统中都选择最终一致性。
最终一致性允许多个节点的状态出现冲突,但是所有能够沟通的节点都能够在有限的时间内解决冲突,从不一致的状态恢复到一致,这里列出的两个条件比较重要,一是节点直接可以正常通信,二是冲突需要在有限的时间内解决,只有在这两个条件成立时才能达到最终一致性。
共识算法
在分布式系统中,我们会遇到节点故障宕机或者不响应等情况,这便有了Paxos 和 Raft。
Paxos 和 Raft
Paxos 和 Raft 是目前分布式系统领域中两种非常著名的解决一致性问题的共识算法,两者都能解决分布式系统中的一致性问题,但是前者的实现与证明非常难以理解,后者的实现比较简洁并且遵循人的直觉,它的出现就是为了解决 Paxos 难以理解并和难以实现的问题。
我们先来简单介绍一下 Paxos 究竟是什么,Paxos 其实是一类能够解决分布式一致性问题的协议,它能够让分布式网络中的节点在出现错误时仍然保持一致;Leslie Lamport 提出的 Paxos 可以在没有恶意节点的前提下保证系统中节点的一致性,也是第一个被证明完备的共识算法,目前的完备的共识算法包括 Raft 本质上都是 Paxos 的变种。
作为一类协议,Paxos 中包含 Basic Paxos、Multi-Paxos、Cheap Paxos 和其他的变种,在这一小节我们会简单介绍 Basic Paxos 和 Multi-Paxos 这两种协议。
Basic Paxos
Basic Paxos 是 Paxos 中最为基础的协议,每一个 Basic Paxos 的协议实例最终都会选择唯一一个结果;使用 Paxos 作为共识算法的分布式系统中,节点都会有三种身份,分别是 Proposer(提案)、Acceptor 和 Learner。
我们在这里会忽略最后一种身份 Learner 简化协议的运行过程,便于读者理解;Paxos 的运行过程分为两个阶段,分别是准备阶段(Prepare)和接受阶段(Accept),当 Proposer 接收到来自客户端的请求时,就会进入如下流程:
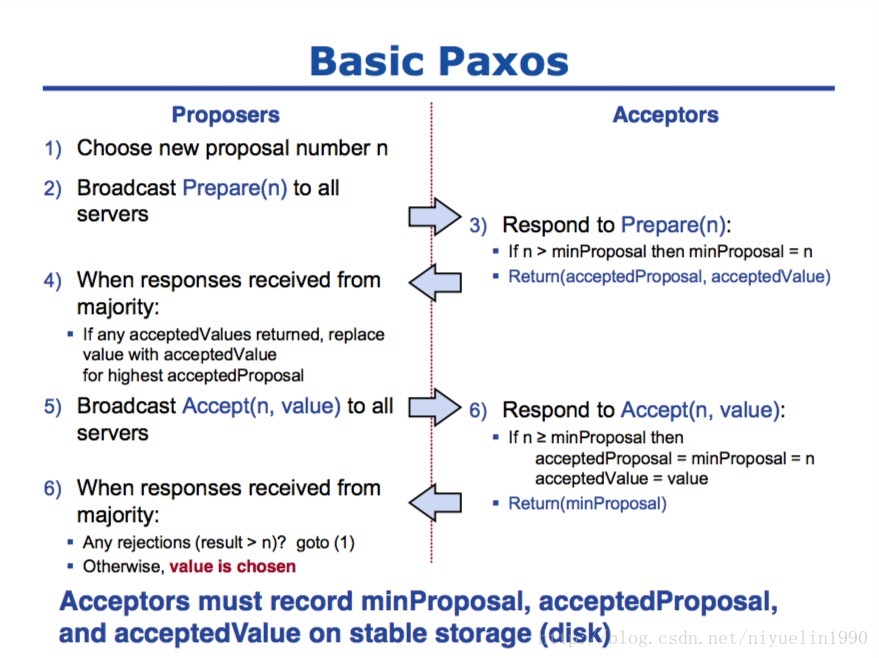
在整个共识算法运行的过程中,Proposer 负责提出提案并向 Acceptor 分别发出两次 RPC 请求,Prepare 和 Accept;Acceptor 会根据其持有的信息 minProposal、acceptedProposal 和 acceptedValue 选择接受或者拒绝当前的提案,当某一个提案被过半数的 Acceptor 接受之后,我们就认为当前提案被整个集群接受了
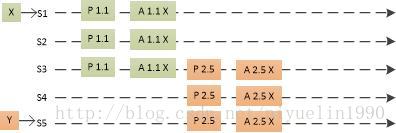
我们简单举一个例子介绍 Paxos 是如何在多个提案下保证最终能够达到一致性的,上述图片中 S1 和 S5 分别收到了来自客户端的请求 X 和 Y,S1 首先向 S2 和 S3 发出 Prepare RPC 和 Accept RPC,三个服务器都接受了 S1 的提案 X;在这之后,S5 向 S3 和 S4 服务器发出 Prepare(2.5) 的请求,S3 由于已经接受了 X,所以它会返回接受的提案和值 (1.1, X),这时服务器使用接收到的提案代替自己的提案 Y,重新向其他服务器发送 Accept(2.5, X) 的 RPC,最终所有的服务器会达成一致并选择相同的值。
Multi-Paxos
由于大多数的分布式集群都需要接受一系列的值,如果使用 Basic Paxos 来处理数据流,那么就会导致非常明显的性能损失,而 Multi-Paxos 是前者的加强版,如果集群中的 Leader 是非常稳定的,那么我们往往不需要准备阶段的工作,这样就能够将 RPC 的数量减少一半。
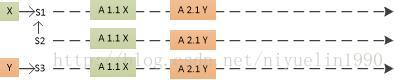
上述图片中描述的就是稳定阶段 Multi-Paxos 的处理过程,S1 是整个集群的 Leader,当其他的服务器接收到来自客户端的请求时,都会将请求转发给 Leader 进行处理。
当然,Leader 角色的出现自然会带来另一个问题,也就是 Leader 究竟应该如何选举,在 Paxos Made Simple 一文中并没有给出 Multi-Paxos 的具体实现方法和细节,所以不同 Multi-Paxos 的实现上总有各种各样细微的差别。
Raft
Raft 其实就是 Multi-Paxos 的一个变种,Raft 通过简化 Multi-Paxos 的模型,实现了一种更容易让人理解的共识算法,它们两者都能够对一系列连续的问题达成一致。
Raft 在 Multi-Paxos 的基础之上做了两个限制,首先是 Raft 中追加日志的操作必须是连续的,而 Multi-Paxos 中追加日志的操作是并发的,但是对于节点内部的状态机来说两者都是有序的,第二就是 Raft 对 Leader 选举的条件做了限制,只有拥有最新、最全日志的节点才能够当选 Leader,但是 Multi-Paxos 由于任意节点都可以写日志,所以在选择 Leader 上也没有什么限制,只是在选择 Leader 之后需要将 Leader 中的日志补全。

在 Raft 中,所有 Follower 的日志都是 Leader 的子集,而 Multi-Paxos 中的日志并不会做这个保证,由于 Raft 对日志追加的方式和选举过程进行了限制,所以在实现上会更加容易和简单。
从理论上来讲,支持并发日志追加的 Paxos 会比 Raft 有更优秀的性能,不过其理解和实现上还是比较复杂的,很多人都会说 Paxos 是科学,而 Raft 是工程,当作者需要去实现一个共识算法,会选择使用 Raft 和更简洁的实现,避免因为一些边界条件而带来的复杂问题。
总结
在这篇文章中,我们首先介绍了分布式系统中面对的最重要问题,分布式一致性。这里介绍了解决非拜占庭问题下一致性算法 Paxos 和 Raft。现在工程上常用的一致性工程是ETCD。