参考,文中较为详细,本文结合该文章进行实践,主要还是学习,哈哈~~
1.网页基础知识
可以参考用python爬虫学习笔记中的第一节或者直接参考该网址
2.rvest用法简介
下面对rvest包中的主要函数的功能做一下说明:
read_html() 读取html文档的函数,其输入可以是线上的url,也可以是本地的html文件,甚至是包含html的字符串也可以。
html_nodes() 选择提取文档中制定元素的部分。可以使用css selectors,例如html_nodes(doc, “table td”);也可以使用xpath selectors,例如html_nodes(doc, xpath = “//table//td”)。本文后面的示例主要采用css selectors来提取html文档中我们想要的部分。
html_tag() 提取标签名称;html_text() 提取标签内的文本;html_attr() 提取指定属性的内容;html_attrs() 提取所有的属性名称及其内容;
html_table() 解析网页数据表的数据到R的数据框中。
html_form(),set_values()和submit_form() 分别表示提取、修改和提交表单。
在中文网页中我们经常会遇到乱码的问题,这里提供了两个函数来解决:guess_encoding()用来探测文档的编码,方便我们在读入html文档时设置正确的编码格式,repair_encoding()用来修复html文档读入后的乱码问题。
还有一些函数,用来模拟网上的浏览行为,如html_session(),jump_to(),follow_link(),back(),forward(),submit_form()等等,这部分的工作还在进行中,相信rvest也会越来越强大。
3.简单实践
因为我最近同时在学习R和Python。所以用python爬虫学习笔记的案例做一下对比,我们还是对中国旅游网站进行爬虫。
目标:爬取中国旅游网站的首页所有的标题和链接
##安装包并加载包
install.packages("rvest")
install.packages("xml2")
library(stringr)
library(xml2)
library(rvest)
## 抓取中国旅游网站消息列表
html_nodes(web,".newsList-b a")%>%html_text
补充说明:
html_nodes()里的内容为啥是那样子呢,原作者们都是对网页结构非常了解了的,而像我们这种小白,一知半解的,真的很难,没关系,但是我会依样画葫芦鸭。首先,打开原作者抓取的页面http://sports.sina.com.cn/nba/(就是我参考的文章),选中中间任意一个文字标题,右键>检查,进入开发者界面。(这部分在python里讲过),然后【ctrl+F】在对话框中输入【.news-list-b 】,哈哈,被我逮到了吧。
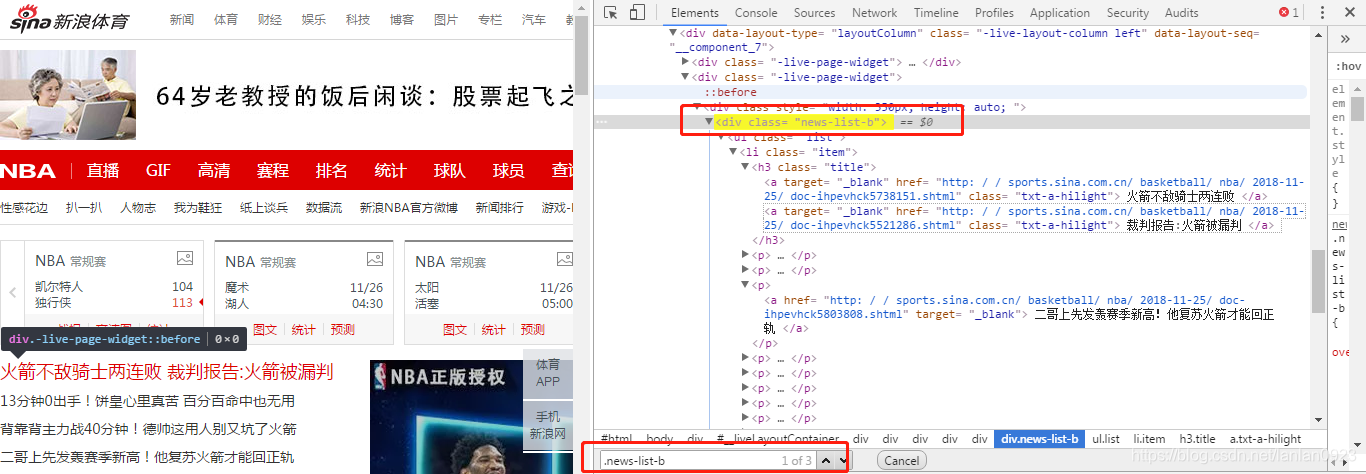
就是这个东西啦,原来原作者获取的是节点的属性值,嗯,所以原作者一开始就让我们花10分钟了解一下html了,幸亏我听话,哈哈~~
接下来,就是我们的照葫芦画瓢的时间啦
我们的节点位置应该是,如下图:
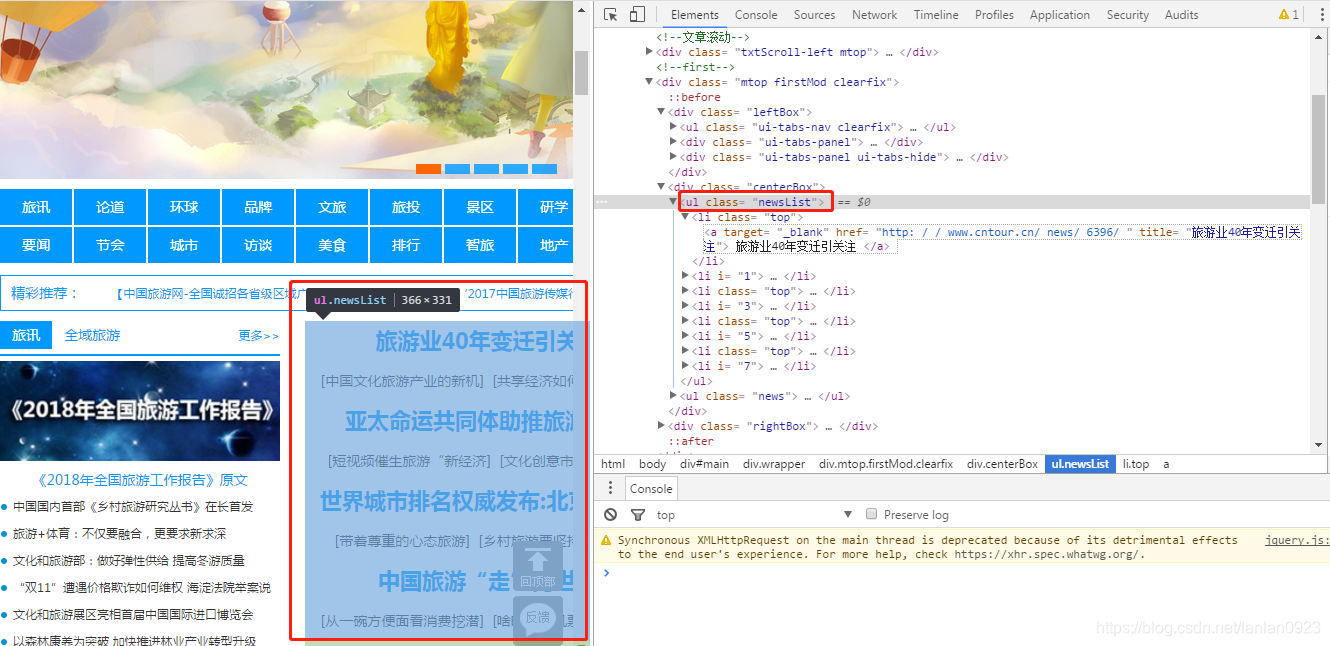 然后代码运行的结果如下图:
然后代码运行的结果如下图:

说明我的猜测非常正确啊,至此,补充说明结束。
其实,还有个问题:就是【%>%】是个什么东西,网上搜索了一下,说是什么管道操作符,其实它就是提取你节点里是text的内容。
如果我们不用这个操作符,直接提取节点里所有的额内容,可能比较简单,直接将【copy selector】的内容复制过来,然后删除冒号之后的子节点(python里面也有说过)
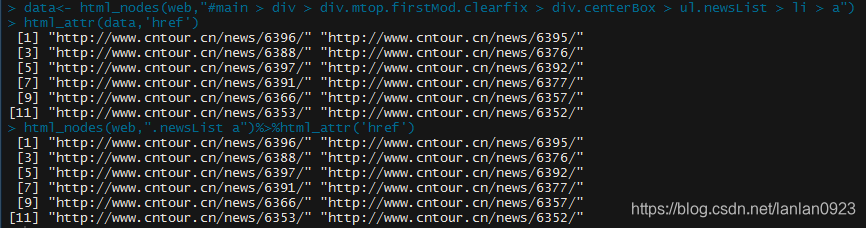
html_nodes(web,"#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a")
然后运行,得到如下结果
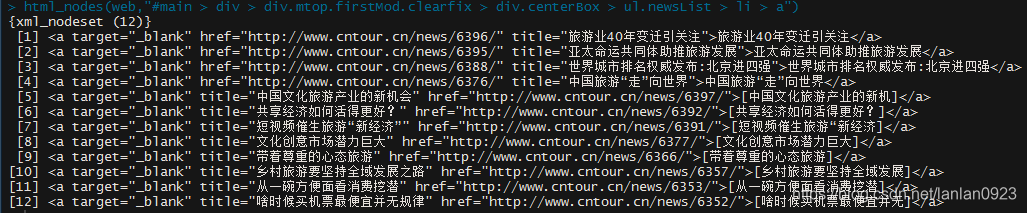
这应该是比较原始的结果,然后我们再提取我们想要的信息,比如其中的文字f标题级title中的内容,以及href中的链接。
写到这里的时候,我发现跟python实在太像啦,所以我想着能不能和python一样写个循环,把这两项信息给提取出来。接下来,实操:
data<- html_nodes(web,"#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a")
for item in data: #soup匹配到的有多个数据,用for循环取出
result={
'title':item.get_text(),
'link':item.get('href'),
}
上述代码是python里面的代码,还要改成R的,好吧,我还在入门,没有打开二者的任督二脉,宣告此路暂时不通。
那么,接下来回到我们的目标上,提取标题文字和链接,标题文字我们已经在获得了,下面就是链接。经过我一番实验,研究以下代码:
data<- html_nodes(web,"#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a")
html_attr(data,'href')
##上面两行代码等价于下面
html_nodes(web,".newsList a")%>%html_attr('href')
跑出结果如下: