基于R
相信自己,每天多学一点。
温故而知新,如有错误请指正。
东方玄学,总是充满了神奇的。
(一本正经的背景:射手座水逆的很严重啊= = )
(好吧,就是闲的没事想找找周易玄学的书了)= =
这次用到了R包 中的爬虫weapon之一 rvest。
爬虫的网站是当当网(书的资源比较舒服,爬的也舒服~~)
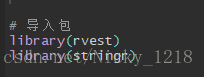
首先是导入包
首页的网址:http://category.dangdang.com/pg1-cp01.28.01.17.00.00.html

在这里我们其实已经可以找找规律了,页码在pg后位数字表示,
然后在查看源码,会发现在html中我们所需要的信息都已经包括了(不愧是超文本~~)
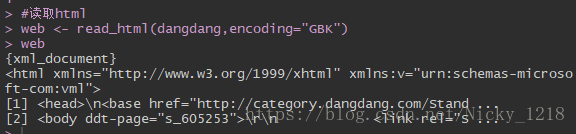
这里,我们直接可以read_html

结果会得到很多一串的东西,就是之前看到的源码
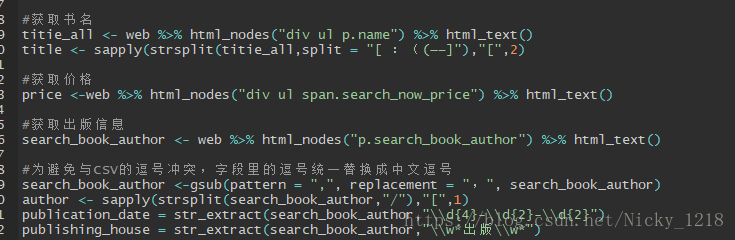
这里我们可以直接看标签正则取出来我们需要的东西的
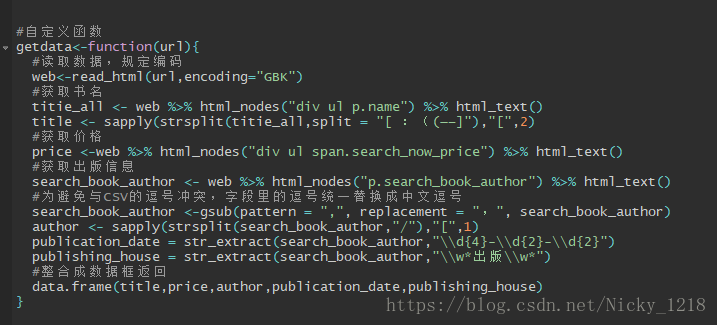
最后直接整理一下,作为数据框返回就好了~

好吧,其实到这里,mission completely~~~
但是还有一个问题的,这只是爬取了第一页的数据的,那么要是想爬取多个应该怎么办呢?
好吧,这个也很简单的。
循环搞定。
这里,我会先把上面的爬取的东西集合,作为一个自定义函数,如下:
下面,直接写一个for循环解决问题。
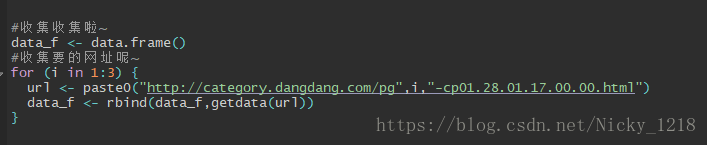
下面,没然后了,想写出为csv也行,随便咯~
我这边是写出为csv了~
看一下效果~
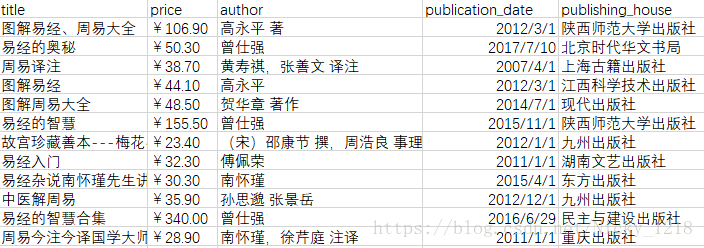
好啦,今晚就稍微皮一下就好了~~
溜了溜了~