一个graph中各种不同特征的node,tf需要依据一定的规则将不同的node放在不同的device上,这点对于分布式或者单机多卡比较重要。tf在node的分配算法上有placer和costmodel(代价模型);这里简单分析一下placer算法。代价模型是依据算子对设备的要求、设备的情况等,做出一个模拟的运行时间评估,力争将node分配到不同的合适的device上,以实现node运行时的最大效率。
代价模型的代码实现在:core/graph/costmodel.h
源码目录在:core/common_runtime/placer.h
该算法的实现核心在:Placer::Run接口中,现在来看一下该接口的主体流程。
Placer::Run
// 1. 通过Edge来查找src_node和dst_node
// 2. 规则一:如果该node是0输入,单输出,则该节点与该edge相连的dst节点在同一个设备上,比如权值W,
IsGeneratorNode
// 3. 规则二:如果该节点的计算不依赖其他数据,仅仅是元数据计算,则该节点和src_node在同一个设备上。如reshape节点
IsMetadata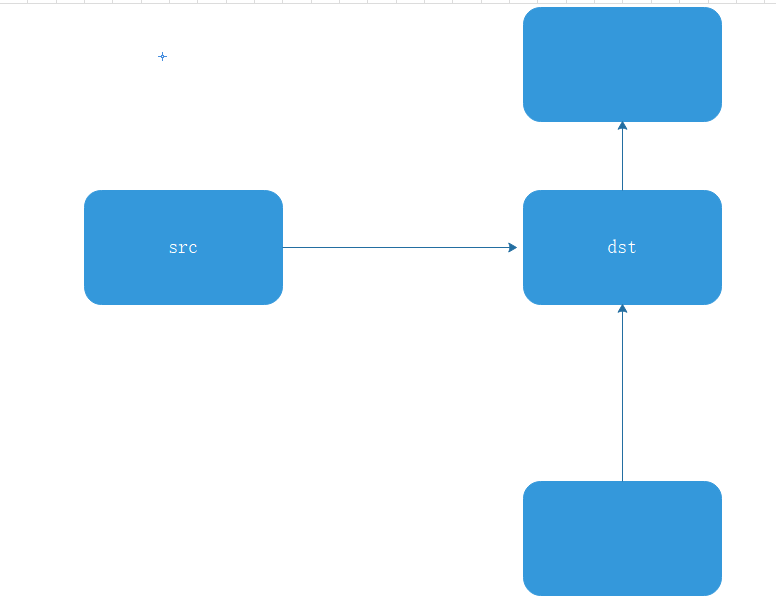
node分配算法,与应用场景有关系,与设备负载、算子对运行设备的要求等有关系。比如某个算子没有GPU实现,则只能在CPU上运行,系统不能将该算子分配到GPU上;再例如:GPU0满载,GPU1空载,则应该将算子分配到GPU1上去。因此算子的分配应当是个动态的过程,依据当时的运行环境、系统资源而定。这里暂不对算子分配规则做深入分析,毕竟不同的设备、不同的运行环境,都可以有最适合自己的一套规则。