项目:
https://blog.csdn.net/column/details/str2hiberspring.html
SSH图解
http://blog.51cto.com/13508140/2055675
项目(一)
1.创建HibernateSessionFactory使用了单例和线程池技术!
单例模式详解
单例模式是为了确保程序中有一个实例!
饿汉模式占用空间,懒汉模式多线程有风险,双重锁懒汉模式由于JVM乱序执行,也回线程不安全,不过在JDK1.5之后,官方也发现了这个问题,故而具体化了volatile,即在JDK1.6及以后,只要定义为private volatile static SingleTon INSTANCE = null;就可解决DCL失效问题。volatile确保INSTANCE每次均在主内存中读取,这样虽然会牺牲一点效率,但也无伤大雅。
静态内部类的优点是:外部类加载时并不需要立即加载内部类,内部类不被加载则不去初始化INSTANCE,故而不占内存。即当SingleTon第一次被加载时,并不需要去加载SingleTonHoler,只有当getInstance()方法第一次被调用时,才会去初始化INSTANCE,第一次调用getInstance()方法会导致虚拟机加载SingleTonHoler类,这种方法不仅能确保线程安全,也能保证单例的唯一性,同时也延迟了单例的实例化。
然而静态内部类也有着一个致命的缺点,就是传参的问题,由于是静态内部类的形式去创建单例的,故外部无法传递参数进去,例如Context这种参数,所以,我们创建单例时,可以在静态内部类与DCL模式里自己斟酌。
也可枚举单例,线程安全。
public enum SingleTon{
INSTANCE;
public void method(){
//TODO
}
}直接
SingleTon.INSTANCESessionFactory
1.) SessionFactory是一个与连接池的类差不多的东西,在这里存着多个Session—与数据库的会话(相当于connection)
2.) 因为连接数据库的配置信息和映射信息都在SessionFactory,比较占内存,所以在hibernate中SessionFactory只有一个
3.) SessionFactory是线程安全的
2.事物的作用!:事务管理是企业级应用程序开发中必不可少的技术,用来确保数据的完整性和一致性
事务就是一系列的动作,它们被当作一个单独的工作单元。这些动作要么全部完成,要么全部不起作用
sessionfactory的创建:
1.读取核心配置文件hibernate.cfg.xml
Configuration cfg = new Configuration();
//声明读取配置文件的类,此类在实例化时默认即读取
// 默认会先去读取classpath下的hibernate.properties,
//然后读取hibernate.cfg.xml文件,后者会覆盖前者
cfg.configure();2.创建sessionfactory(),里面有映射信息(通过metadata)见https://www.cnblogs.com/uzipi/p/8094555.html
SessionFactory sessionFactory = cfg.buildSessionFactory();类加载时机问题
http://www.cnblogs.com/javaee6/p/3714716.html?utm_source=tuicool&utm_medium=referral
总结来说:静态代码的加载,是在类加载阶段的初始化阶段,该阶段就是类加载器执行方法的过程,()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块(static{}块)中的语句合并产生的。
而只有主动引用才能触发类的初始化,即
1.创建类的实例
2.访问类的静态变量(除常量【被final修辞的静态变量】
原因:常量一种特殊的变量,因为编译器把他们当作值(value)
而不是域(field)来对待。如果你的代码中用到了常变量(constant variable),
编译器并不会生成字节码来从对象中载入域的值,而是直接把这个值插入到字节码中。
这是一种很有用的优化,但是如果你需要改变final域的值那么每一块用到那个域的
代码都需要重新编译。
2.访问类的静态方法
3.反射如(Class.forName("my.xyz.Test"))
4.当初始化一个类时,发现其父类还未初始化,则先出发父类的初始化
5.虚拟机启动时,定义了main()方法的那个类先初始化
的时候才会初始化
3.HibernateTemplate和SessionFactory
配置sessionFactory是用来产生一个session的,另外HibernateTemplate也可以,但是这里采用sessionFactory而 不用HibernateTemplate,是因为HibernateTemplate是Spring提供的,依赖于Spring,如果哪天不用Spring了,就会报错 。而sessionFactory是Hibernate提供的,没有问题。HibernateTemplate的依赖性太强了。
4.Session:
hibernate中的Session呢?是用来表示,应用程序和数据库的一次交互(会话)。在这个Session中,包含了一般的持久化方法(CRUD),不要说不知道CRUD是什么微笑。而且,Session是一个轻量级对象(线程不安全),通常将每个Session实例和一个数据库事务绑定,也就是每执行一个数据库事务,都应该先创建一个新的Session实例,在使用Session后,还需要关闭Session。
5.datasource与连接池:
https://www.cnblogs.com/albertrui/p/8421791.html
http://www.flyne.org/article/599这两篇文章讲的很好
简单地说:普通的JDBC数据库连接使用 DriverManager 来获取,每次connect开销都比较大,性能不好,为了解决这个问题采用连接池技术。
数据库连接池的基本思想就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个。
一般有1.c3p02.dbcp3.druid 三种第三方提供连接池的方式
本身也是提供连接池管理https://blog.csdn.net/qq_15037231/article/details/78735591
JNDI-> DataSource->连接池(c3p0,dbcp,Proxool等)->DriverManager->connection
连接池单例模式:https://blog.csdn.net/baidu_37107022/article/details/73658487
JNDI:底层是个哈希表,先向WEB注册数据源,然后通过LOOKUP的可以得到
6.事务管理sessionfactory
事务 :
1事务由一系列的相关的sql语句组成的最小逻辑工作单元
2oracle以事务为单位来处理数据,保证数据的一致性
3如果对事务进行提交,该事物的所有sql语句操作都会提交,成为数据库的永久组成部分
4如果事务遇到错误而被取消或者回滚,事务的所有sql语句操作都会被清除,数据库恢复到事务执行前的状态。
提交事务 :提交事务表示该事务中对数据库所做的全部操作都将永久记录在数据库中。
回滚事务:回滚事务表示该事务对数据库的所有操作都将取消 AOP详解
http://www.cnblogs.com/hongwz/p/5764917.html
AOP,简单说就是那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块之间的耦合度,并有利于未来的可操作性和可维护性。
横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处基本相似,比如权限认证、日志、事物。AOP的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。
事务就是横切关注点。
事务与AOP(即声明式事务)https://blog.csdn.net/xiaoyi52/article/details/76037699
实战(二)
7.struts2的过滤器
过滤器在服务器启动时候创建,创建过滤器时候执行init方法
在init方法中主要加载配置文件
- 包含自己创建的配置文件和struts2自带配置文件
** struts.xml
** web.xml
:struts2的核心是过滤器,不像s1是ActionServlet核心控制,s2中的过滤器是接受request请求然后判断调用哪个action,读取struts.xml文件,页面跳转..init方法
8.在web.xml中配置监听器ContextLoaderListener
在开始讲解这个之前先讲讲web工程的上下文,对于一个web容器,web容器提供了一个全局的上下文环境,这个上下文就是ServletContext,其为后面Spring IOC容器提供宿主环境。
在web容器启动时会触发容器初始化事件,contextLoaderListener监听到这个事件后其contextInitialized方法就会被调用,在这个方法中,spring会初始化一个启动上下文,这个上下文就是根上下文,也就是WebApplicationContext,实际实现类一般是XmlWebApplicationContext,这个其实就是spring的IoC容器,这个IoC容器初始化完后,Spring会将它存储到ServletContext,可供后面获取到该IOC容器中的bean。
即 一旦容器启动,就会初始化spring容器,注入applicationContext.xml中配置的bean以及其他一些配置。
9.Struts基本过程
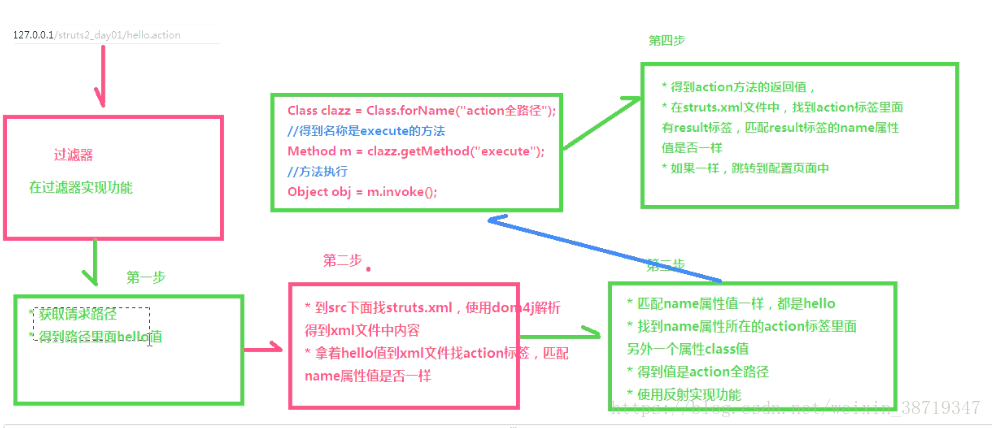
10.Strut2获取表单数据
https://blog.csdn.net/weixin_38719347/article/details/82389413
<a href="category_query.action">查询所有类别</a><br/> 这句话在JSP页面中,点击查询所有类别,会去XML
<action name="category_*" class="cn.it.shop.action.CategoryAction" method="{1}"> 找到class路径,跳转到该类的method,执行语句,
public String query() {
request.put("categoryList", categoryService.query());
session.put("categoryList", categoryService.query());
application.put("categoryList", categoryService.query());
return "index";
} 向三个域中存储了key value键值对(value对数组形式),然后返回Index,在到xml页面中<result name="index">/index.jsp</result>返回index.jsp页面
即为jsp->xml->类中方法->xml->根据result返回jsp页面
11.BaseAction的抽取
抽取ModelDriven到BaseAction:struts中肯定会有很多这种model需要获取,所以这一块我们也要抽取到BaseAction中去。
此处用到了
BaseAction中的getModel方法。
public T getModel() { //这里通过解析传进来的T来new一个对应的instance
ParameterizedType type = (ParameterizedType)this.getClass().getGenericSuperclass();
Class clazz = (Class)type.getActualTypeArguments()[0];
try {
model = (T)clazz.newInstance();
} catch (Exception e) {
throw new RuntimeException(e);
}
return model;
} 同时CategoryAction中总要调用 CategoryService(),总要写,即使注入,也麻烦,所以,也抽取到BaseAction中了
12.级联查询
public List<Category> queryJoinAccount(String type) {
String hql = "from Category c where c.type like :type";
return getSession().createQuery(hql)
.setString("type", "%" + type + "%").list();
} 此处采用一个动态查询,表示的是like后面的 %type% 的样子即可 type是个变量
//Category类中
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "account_id")
public Account getAccount() {
return this.account;
}
//Account类中
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY, mappedBy = "account")
public Set<Category> getCategories() {
return this.categories;
} cascade = CascadeType.ALL表示对主表操作同时,关联表的信息也要同步(ALL指的是保存修改删除刷新四种军同步)
详见:https://www.jb51.net/article/105097.htm
上面不止发送一条SQL语句,但是我们明明只查询了一次,为什么会发这么多语句呢?这就是常见的1+N问题。所谓的1+N问题,就是首先发出一条语句查询当前对象,然后发出N条语句查询关联对象,因此效率变得很低。这里就两个对象,如果有更多的对象,那效率就会大打折扣了,我们该如何解决这个问题呢?
public List<Category> queryJoinAccount(String type) {
String hql = "from Category c left join fetch c.account where c.type like :type";
return getSession().createQuery(hql)
.setString("type", "%" + type + "%").list();
}
} 左连接只影响右表,由连接只影响左表,左表在hql语句左边,右边在右边
左连接:left join
如A left join B 即取出A表的所有数据,由on条件关联的B表数据,有则显示,没有则为空;
右连接:right join
如 A right join B 即取出B表的所有数据,由on条件关联的A表数据,有则显示,没有则为空;
所以:A left join B 与 B right join A 是一样的效果
内连接:inner join
A inner join B 表示A,B中同时都有的数据才取出来;HQL左连接、右连接…https://www.cnblogs.com/henuyuxiang/p/3939758.html
https://www.cnblogs.com/boundless-sky/p/6594518.html
left join表示关联Account一起查询,fetch表示将Account对象加到Category中去,这样就只会发一条SQL语句了,并且返回的Category中也包含了Account对象了。
实战(八):
查询的实现,在搜素框中输入关键字,然后将关键字作为参数传给action,然后Service从数据库中拿出数据,打包成json格式传到前台来显示即可。
传给以下的
url:'category_queryJoinAccount.action', 此处是个级联查询,要看五!
删除
//1. 从获取的记录中获取相应的的id,拼接id的值,然后发送后台1,2,3,4
var ids = "";
for(var i = 0; i < rows.length; i ++) {
ids += rows[i].id + ",";
}
ids = ids.substr(0, ids.lastIndexOf(","));
//2. 发送ajax请求
$.post("category_deleteByIds.action",{ids:ids},function(result){
if(result == "true") {
//将刚刚选中的记录删除,要不然会影响后面更新的操作
$("#dg").datagrid("uncheckAll");
//刷新当前页,查询的时候我们用的是load,刷新第一页,reload是刷新当前页
$("#dg").datagrid("reload");//不带参数默认为上面的queryParams
} else {
$.messager.show({
title:'删除异常',
msg:'删除失败,请检查操作',
timeout:2000,
showType:'slide',
});
} 如果用户选择删除,首先会弹出一个对话框,当用户确定要删除后,我们首先要获取用户所勾选的商品的id,将这些id拼接成一个字符串,然后向后台发送ajax请求, .post中的内容,当后台返回一个”true”表示删除成功了,那么我们调用DataGrid里面的reload方法重新刷新页面,reload和前面查询时用的load是一样的,不同的地方在于reload刷新后停留在当前页面,而load则显示第一页。
后台部分:Category的类别删除用了一个HQL语句
@Override
public void deleteByIds(String ids) {
String hql = "delete from Category c where c.id in (" + ids + ")";
getSession().createQuery(hql).executeUpdate();
}
} 添加商品类别:首先当用户点击“添加商品”时,我们应该弹出一个“添加商品”的UI窗口(注意这里不是跳转到新的jsp,EasyUI只有一个页面),弹出这个“添加商品”的窗口后,应该锁住它父类的所有窗口(即点击其他地方无效,只能操作添加商品的窗口),等用户填好了信息后,在新弹出来的窗口上点击“添加”后,将请求发送给struts2,然后struts2拿到请求你参数,从数据库中执行添加动作,这样后台操作完成,同时前台那边要刷新一下当前页面,重新显示所有商品。
url: ‘category_save.action’, //将请求提交给categoryAction中的save方法处理
他通过EASYUI等设计好界面后总要有调用Action的时候,我就写这些
6.域对象:https://www.cnblogs.com/ssjifm/p/7402579.html
page(jsp有效)——》page域指的是pageContext.
request(一次请求)—》request域request HttpServletContext
session(一次会话)—》session域session HttpSession
application(当前web应用)—》application域指的是application ServletContext;
之所以他们是域对象,原因是他们都内置了map集合,都有setAttribute和getAttribute方法。
7.级联查询