一、任务
使用SVM和决策树两种算法预测贷款用户是否会逾期。
二、分析
数据分析
- 对缺失值进行处理
- 对包含中文数据进行映射
- 对两个时间的不确定进行删除
三、代码实现
import pandas as pd
from sklearn.model_selection import train_test_split
from pandas import Series,DataFrame
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import LinearSVC
from sklearn.metrics import f1_score,r2_score
"""读取数据"""
path= "E:/moxingxuexi/Task1/data.csv"
data = pd.read_csv(path,encoding= 'gbk')
"""
1.1 缺失值用100填充
"""
data=DataFrame(data.fillna(100))
"""
1.2 对reg_preference_for_trad 的处理 【映射】
nan=0 境外=1 一线=5 二线=2 三线 =3 其他=4
"""
n=set(data['reg_preference_for_trad'])
dic={}
for i,j in enumerate(n):
dic[j]=i
data['reg_preference_for_trad'] = data['reg_preference_for_trad'].map(dic)
"""
1.2 对source 的处理 【映射】
"""
n=set(data['source'])
dic={}
for i,j in enumerate(n):
dic[j]=i
data['source'] = data['source'].map(dic)
"""
1.3 对bank_card_no 的处理 【映射】
"""
n=set(data['bank_card_no'])
dic={}
for i,j in enumerate(n):
dic[j]=i
data['bank_card_no'] = data['bank_card_no'].map(dic)
"""
1.2 对 id_name的处理 【映射】
"""
n=set(data['id_name'])
dic={}
for i,j in enumerate(n):
dic[j]=i
data['id_name'] = data['id_name'].map(dic)
"""
1.2 对 time 的处理 【删除】
"""
data.drop(["latest_query_time"],axis=1,inplace=True)
data.drop(["loans_latest_time"],axis=1,inplace=True)
"""划分验证集,测试集"""
train, test = train_test_split(data, test_size=0.3, random_state=666)
"""分标签和 训练数据"""
y_train= train.status
train.drop(["status"],axis=1,inplace=True)
y_test= test.status
test.drop(["status"],axis=1,inplace=True)
SVM模型预测并评分分析
"""模型训练"""
print("支持向量机模型训练")
Lin_SVC = LinearSVC()
Lin_SVC.fit(train,y_train)
"""模型预测"""
y_test_pre = Lin_SVC.predict(test)
"""模型评分"""
f1 = f1_score(y_test, y_test_pre, average='macro')
print("f1分数:{}".format(f1))
r2 = r2_score(y_test, y_test_pre)
print("f2分数:{}".format(r2))
score = Lin_SVC.score(test, y_test)
print("验证集分数:{}".format(score))
评分分析

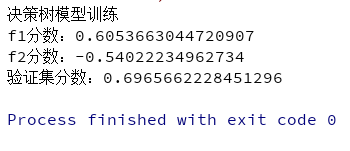
决策树模型预测并得到结果
"""模型训练"""
print("决策树模型训练")
DT = DecisionTreeClassifier()
DT.fit(train,y_train)
"""模型预测"""
y_test_pre = DT.predict(test)
"""模型评分"""
f1 = f1_score(y_test, y_test_pre, average='macro')
print("f1分数:{}".format(f1))
r2 = r2_score(y_test, y_test_pre)
print("f2分数:{}".format(r2))
score = DT.score(test, y_test)
print("验证集分数:{}".format(score))