文章目录
任务
给定金融数据,预测贷款用户是否会逾期。(status是标签:0表示未逾期,1表示逾期。)
Task1 - 构建逻辑回归模型进行预测(在构建部分数据需要进行缺失值处理和数据类型转换,如果不能处理,可以直接暴力删除)
Task2 - 构建SVM和决策树模型进行预测
Task3 - 构建xgboost和lightgbm模型进行预测
Task4 - 模型评估:记录五个模型关于accuracy、precision,recall和f1-score、auc、roc的评分表格,画出auc和roc曲线图
总述
基本思路
主要分为以下几个步骤:
1)数据集预览
2)数据预处理:删除无用特征、字符型特征编码和缺失值填充。
3)特征工程:略
4)模型选择:LR、SVM(线性、多项式、高斯、sigmoid)、决策树、XGB和lightGBM。
5)模型调参:略
6)模型评估:准确率、精准率和召回率、F1-score、AUC和ROC曲线。
7)最终结果
代码部分
1. 数据集预览
import pandas as pd
data = pd.read_csv('data.csv')
print(data.shape)
data.head()
观察输出可知,数据集尺寸是(4754, 90)。
下面观察一下各列的属性名称:
data.columns
输出:‘low_volume_percent’,‘middle_volume_percent’,‘take_amount_in_later_12_month_highest’ …
2. 数据预处理
2.1 删除无用特征
# 'bank_card_no','source'的取值无区分度
# 'Unnamed: 0', 'custid', 'trade_no'和id_name'与预测无关
data.drop(['Unnamed: 0', 'custid', 'trade_no', 'bank_card_no', 'source', 'id_name'],
axis=1, inplace=True)
日期特征(暂时删除, 以后再处理)
data.drop(['first_transaction_time', 'latest_query_time', 'loans_latest_time'],
axis=1, inplace=True)
2.2 字符型特征-编码
data['reg_preference_for_trad'].value_counts()
输出:
一线城市 3403
三线城市 1064
境外 150
二线城市 131
其他城市 4
对该特征编码如下:
dic = {}
for i, val in enumerate(list(data['reg_preference_for_trad'].unique())):
dic[val] = i
data['reg_preference_for_trad'] = data['reg_preference_for_trad'].map(dic)
2.3 缺失特征处理
观察各列缺失值所占比例,从输出可以看出特征student_feature 缺失值占比超过一半,其余特征缺失值占比较低。
for feature in data.columns:
summ = data[feature].isnull().sum()
if summ:
print('%.4f'%(summ*100/4754), '%', '--', feature)
1)student_feature 缺失占比多, 需要用众数填充;
data['student_feature'].value_counts()
输出:
1.0 1754
2.0 2
用众数1.0填充缺失值
data['student_feature'].fillna(1.0, inplace = True)
2)其余特征用均值填充。
for feature in data.columns:
summ = data[feature].isnull().sum()
if summ:
data[feature].fillna(data[feature].mean(), inplace = True)
3. 特征工程
略
4. 模型选择
4.1 数据集划分
features = [x for x in data.columns if x not in ['status']]
# 划分训练集测试集
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = data[features]
y = data.status
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,random_state=2333)
# 特征归一化
std = StandardScaler()
X_train = std.fit_transform(X_train)
X_test = std.transform(X_test)
4.2 LR模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train, y_train)
4.3 SVM模型
线性核函数、多项式核函数、高斯核函数、sigmoid核函数
添加probability=True,可使用predict_proba预测概率值。
from sklearn import svm
svm_linear = svm.SVC(kernel = 'linear', probability=True).fit(X_train, y_train)
svm_poly = svm.SVC(kernel = 'poly', probability=True).fit(X_train, y_train)
svm_rbf = svm.SVC(probability=True).fit(X_train, y_train)
svm_sigmoid = svm.SVC(kernel = 'sigmoid',probability=True).fit(X_train, y_train)
4.4 决策树模型
树模型,特征不需归一化。
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(max_depth=4)
clf.fit(X_train, y_train)
4.5 XGBoost模型
from xgboost.sklearn import XGBClassifier
xgb = XGBClassifier()
xgb.fit(X_train, y_train)
4.6 LightGBM模型
from lightgbm.sklearn import LGBMClassifier
lgb = LGBMClassifier()
lgb.fit(X_train, y_train)
5. 模型调参
略
6. 模型评估
观察accuracy、precision,recall和f1-score、auc的取值,并画出roc曲线图
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import roc_auc_score,roc_curve, auc
import matplotlib.pyplot as plt
%matplotlib inline
def model_metrics(clf, X_train, X_test, y_train, y_test):
# 预测
y_train_pred = clf.predict(X_train)
y_test_pred = clf.predict(X_test)
y_train_proba = clf.predict_proba(X_train)[:,1]
y_test_proba = clf.predict_proba(X_test)[:,1]
# 准确率
print('[准确率]', end = ' ')
print('训练集:', '%.4f'%accuracy_score(y_train, y_train_pred), end = ' ')
print('测试集:', '%.4f'%accuracy_score(y_test, y_test_pred))
# 精准率
print('[精准率]', end = ' ')
print('训练集:', '%.4f'%precision_score(y_train, y_train_pred), end = ' ')
print('测试集:', '%.4f'%precision_score(y_test, y_test_pred))
# 召回率
print('[召回率]', end = ' ')
print('训练集:', '%.4f'%recall_score(y_train, y_train_pred), end = ' ')
print('测试集:', '%.4f'%recall_score(y_test, y_test_pred))
# f1-score
print('[f1-score]', end = ' ')
print('训练集:', '%.4f'%f1_score(y_train, y_train_pred), end = ' ')
print('测试集:', '%.4f'%f1_score(y_test, y_test_pred))
# auc取值:用roc_auc_score或auc
print('[auc值]', end = ' ')
print('训练集:', '%.4f'%roc_auc_score(y_train, y_train_proba), end = ' ')
print('测试集:', '%.4f'%roc_auc_score(y_test, y_test_proba))
# roc曲线
fpr_train, tpr_train, thresholds_train = roc_curve(y_train, y_train_proba, pos_label = 1)
fpr_test, tpr_test, thresholds_test = roc_curve(y_test, y_test_proba, pos_label = 1)
label = ["Train - AUC:{:.4f}".format(auc(fpr_train, tpr_train)),
"Test - AUC:{:.4f}".format(auc(fpr_test, tpr_test))]
plt.plot(fpr_train,tpr_train)
plt.plot(fpr_test,tpr_test)
plt.plot([0, 1], [0, 1], 'd--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(label, loc = 4)
plt.title("ROC curve")
# 逻辑回归
model_metrics(lr, X_train, X_test, y_train, y_test)
# 线性SVM
model_metrics(svm_linear, X_train, X_test, y_train, y_test)
# 多项式SVM
model_metrics(svm_poly, X_train, X_test, y_train, y_test)
# 高斯核SVM
model_metrics(svm_rbf, X_train, X_test, y_train, y_test)
# sigmoid-SVM
model_metrics(svm_sigmoid, X_train, X_test, y_train, y_test)
# 决策树
model_metrics(dt, X_train, X_test, y_train, y_test)
# XGBoost
model_metrics(xgb, X_train, X_test, y_train, y_test)
# lightGBM
model_metrics(lgb, X_train, X_test, y_train, y_test)
7. 最终结果
| 模型 | 准确率 | 精准率 | 召回率 | F1-score | AUC值 | ROC曲线 |
|---|---|---|---|---|---|---|
| 逻辑回归 | 训练集:0.7995 测试集: 0.8024 | 训练集: 0.7094 测试集: 0.7052 | 训练集: 0.3488 测试集: 0.3456 | 训练集: 0.4677 测试集: 0.4639 | 训练集: 0.8054 测试集: 0.8050 | 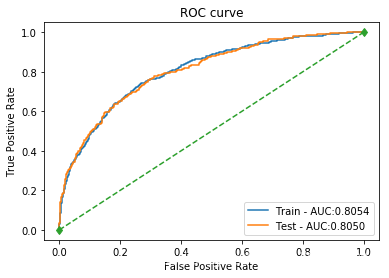 |
| SVM_linear | 训练集: 0.7908 测试集: 0.7947 | 训练集: 0.7647 测试集: 0.7885 | 训练集: 0.2476 测试集: 0.2323 | 训练集: 0.3741 测试集: 0.3589 | 训练集: 0.8042 测试集: 0.8092 | 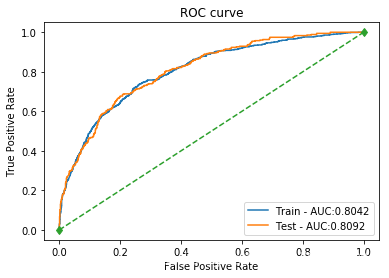 |
| SVM_poly | 训练集: 0.8284 测试集: 0.7554 | 训练集: 0.9786 测试集: 0.5208 | 训练集: 0.3274 测试集: 0.1416 | 训练集: 0.4906 测试集: 0.2227 | 训练集: 0.9391 测试集: 0.7117 | 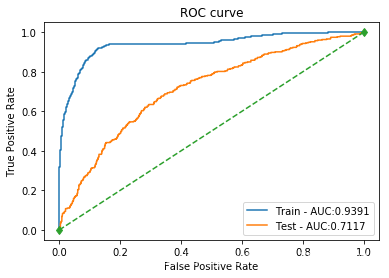 |
| SVM_rbf | 训练集: 0.8266 测试集: 0.7975 | 训练集: 0.9046 测试集: 0.7963 | 训练集: 0.3500 测试集: 0.2436 | 训练集: 0.5047 测试集: 0.3731 | 训练集: 0.9170 测试集: 0.7680 | 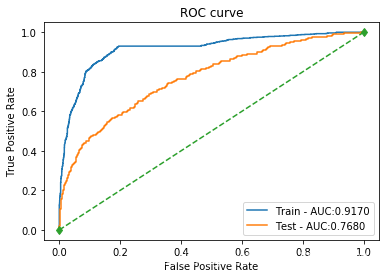 |
| SVM_sigmoid | 训练集: 0.7205 测试集: 0.7379 | 训练集: 0.4373 测试集: 0.4662 | 训练集: 0.3738 测试集: 0.4108 | 训练集: 0.4031 测试集: 0.4367 | 训练集: 0.6600 测试集: 0.6784 | 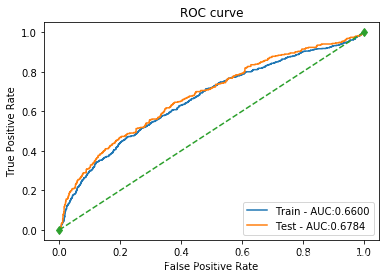 |
| 决策树 | 训练集: 0.7920 测试集: 0.7737 | 训练集: 0.6581 测试集: 0.5862 | 训练集: 0.3667 测试集: 0.2890 | 训练集: 0.4709 测试集: 0.3871 | 训练集: 0.7727 测试集: 0.7468 | 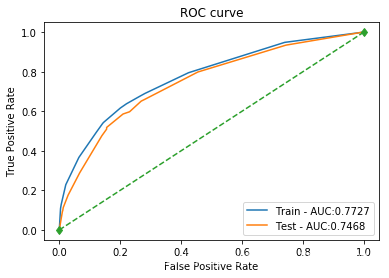 |
| XGBoost | 训练集: 0.8521 测试集: 0.8045 | 训练集: 0.8718 测试集: 0.7079 | 训练集: 0.4857 测试集: 0.3569 | 训练集: 0.6239 测试集: 0.4746 | 训练集: 0.9166 测试集: 0.7972 | 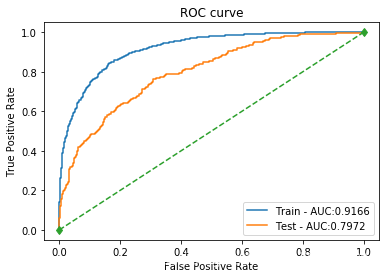 |
| LightGBM | 训练集: 0.9949 测试集: 0.7961 | 训练集: 1.0000 测试集: 0.6550 | 训练集: 0.9798 测试集: 0.3711 | 训练集: 0.9898 测试集: 0.4738 | 训练集: 1.0000 测试集: 0.7869 | 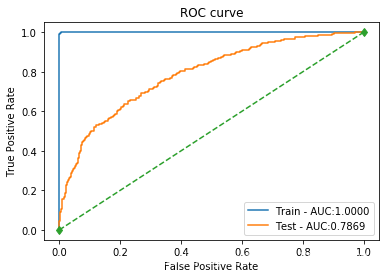 |
遇到的问题
1)pd.read_csv读取文件时,utf-8的编码问题。
解决方法:reference1
2)装完xgboost后在notebook总是显示如下错误:ImportError: cannot import name ‘MultiIndex’。
解决方法:更新scipy和xgboost后还是没有解决;后来重启了一下jupyter就好了…
3)画ROC曲线时, tpr取值为nan
解决方法:注意roc_curve里的几个参数:第二项为真实y与预测的scores而不是y_pred,而pos_label=1指在y中标签为1的是标准阳性标签,其余值是阴性。
4)SVM用函数clf.predict_proba()时候报错如下:
AttributeError: predict_proba is not available when probability=False
解决方法:clf = SVC()默认情况probability=False,添加probability=True
Reference
1)python问题–UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xff in position 0: invalid start byte
2)ML实操 - 贷款用户逾期情况分析
More
代码参见Github: https://github.com/libihan/Exercise-ML