小猪短租是一个租房网站,上面有很多优质的民宿出租信息,下面我们以成都地区的租房信息为例,来尝试爬取这些数据。
小猪短租(成都)页面:http://cd.xiaozhu.com/

1.爬取租房标题
按照惯例,先来爬下标题试试水,找到标题,复制xpath。
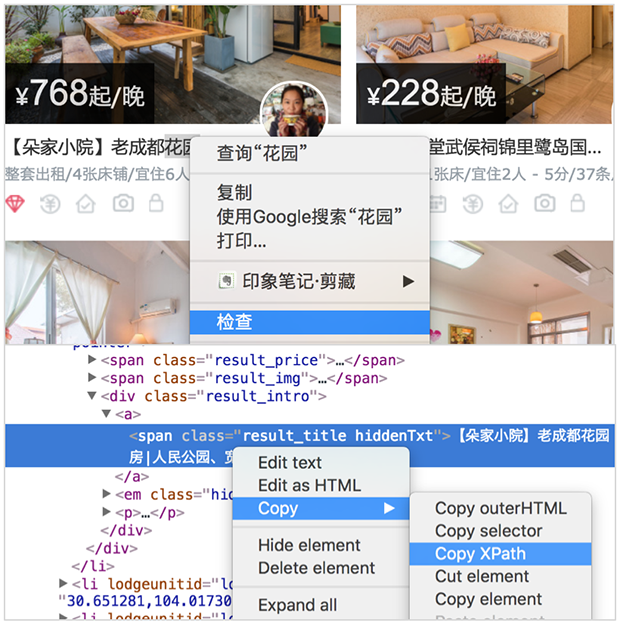
多复制几个房屋的标题 xpath 进行对比:
//*[@id="page_list"]/ul/li[1]/div[2]/div/a/span
//*[@id="page_list"]/ul/li[2]/div[2]/div/a/span
//*[@id="page_list"]/ul/li[3]/div[2]/div/a/span
瞬间发现标题的 xpath 只在<li>后序号变化,于是,秒写出爬取整页标题的 xpath:
//*[@id=“page_list”]/ul/li/div[2]/div/a/span
还是固定的套路,让我们尝试把整页的标题爬下来:

小猪在IP限制方面比较严格,代码中务必要加入 sleep() 函数控制爬取的频率
好了,再来对比下 xpath 信息:

顺着标题的标签网上找,找到整个房屋信息标签, xpath 对比如下:
//*[@id=“page_list”]/ul/li #整体
//*[@id=“page_list”]/ul/li/div[2]/div/a/span #标题
你应该知道该怎么来改代码了吧,写一个循环:
file=s.xpath(‘//*[@id=“page_list”]/ul/li’)
for div in file:
title=div.xpath("./div[2]/div/a/span/text()")[0]
好了,来运行一下试试:

2.爬取多个元素的信息
对比其他元素的 xpath:
//*[@id=“page_list”]/ul/li #整体
//*[@id=“page_list”]/ul/li/div[2]/div/a/span #标题
//*[@id=“page_list”]/ul/li/div[2]/span[1]/i #价格
//*[@id=“page_list”]/ul/li/div[2]/div/em #描述
//*[@id=“page_list”]/ul/li/a/img #图片
然后可以写出代码:
file=s.xpath(“//*[@id=“page_list”]/ul/li”)
for div in file:
title=div.xpath(“./div[2]/div/a/span/text()”)[0]
price=div.xpath(“./div[2]/span[1]/i/text()”)[0]
scrible=div.xpath(“./div[2]/div/em/text()”)[0].strip()
pic=div.xpath(“./a/img/@lazy_src”)[0]
来尝试运行一下:

3.翻页,爬取更多页面
看一下翻页时候 url 的变化:
http://cd.xiaozhu.com/search-duanzufang-p1-0/ #第一页
http://cd.xiaozhu.com/search-duanzufang-p2-0/ #第二页
http://cd.xiaozhu.com/search-duanzufang-p3-0/ #第三页
http://cd.xiaozhu.com/search-duanzufang-p4-0/ #第四页
……………………
url 变化的规律很简单,只是 p 后面的数字不一样而已,而且跟页码的序号是一模一样的,这就很好办了……写一个简单的循环来遍历所有的url。
for a in range(1,6):
url = ‘http://cd.xiaozhu.com/search-duanzufang-p{}-0/’.format(a)
# 我们这里尝试5个页面,你可以根据自己的需求来写爬取的页面数量
完整的代码如下:
from lxml import etree
import requests
import time
for a in range(1,6):
url = 'http://cd.xiaozhu.com/search-duanzufang-p{}-0/'.format(a)
data = requests.get(url).text
s=etree.HTML(data)
file=s.xpath('//*[@id="page_list"]/ul/li')
time.sleep(3)
for div in file:
title=div.xpath("./div[2]/div/a/span/text()")[0]
price=div.xpath("./div[2]/span[1]/i/text()")[0]
scrible=div.xpath("./div[2]/div/em/text()")[0].strip()
pic=div.xpath("./a/img/@lazy_src")[0]
print("{} {} {} {}\n".format(title,price,scrible,pic))
看一下爬了5个页面下来的效果:

相信你已经掌握爬虫基本的套路了,但你还需要去不断熟悉,能独立写出代码为止。
写代码不仅要细心,也需要耐心。很多人从入门到放弃,并不是因为编程这件事情有多难,而是某次实践过程中,遇到一个小问题。
好了,这节分享就到这里!