蛋壳页面上的租房信息不直观,举个例子,如果我是一个程序员,在望京上班的话,附近的地铁线路有13,14,15号线,如果我要尽可能的减少通勤时间,希望能够找到一个价格便宜距离地铁站又比较近的居所,在蛋壳的页面上找的话,我需要一个个点开房源信息,这样太浪费时间。并且我平时又比较忙,没有的太多的时间去现地看房。能不能尽快地帮助我找到符合要求的房源,快速筛选出3-5个最佳的选项。利用python爬虫就可以实现这个功能。
开发环境
- windows 7 x64
- python2.7
- vscode
代码实现
我要找15号线沿线的房源
在蛋壳租房的官网上的选择按地铁线,选择15,租金勾选1500-2000元和2000-3000元
生成的url为https://bj.zu.ke.com/ditiezufang/li43143633/rp2rp3/
直接上代码吧。
#-*- coding:utf-8 -*-
#danke_spider.py
#使用方法 python danke_spider.py [要爬取的信息第一页] [要保存的文件名]
#如python spider.py https://bj.zu.ke.com/ditiezufang/li43143633/rp2rp3/ 15
import requests,re,pickle,sys
from bs4 import BeautifulSoup
from requests.packages import urllib3
urllib3.disable_warnings()
#全局变量
room_info_list = []
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0',
'Origin':'https://bj.zu.ke.com'
}
#获取普通房源情况
def get_room_info(url):
#用来保存房源的信息
room_info={
'url':url}
#发出请求
res = requests.get(url=url,headers=headers,verify=False)
if res.status_code == 200:
#bs解析文档
soup = BeautifulSoup(res.text,'lxml')
#房源的title
room_info['title'] = soup.find('p',class_='content__title').text
print room_info['title']
#房源的价格
room_info['price'] = soup.find('div',class_='content__aside--title').span.text.strip().replace('\n',',')
print room_info['price']
#房源的标签
room_info['tags'] = soup.find('p',class_='content__aside--tags').text.strip().replace('\n',',')
print room_info['tags']
#房源的其它信息
room_info['info'] = soup.find('ul',class_='content__aside__list').text.strip().replace('\n',',').strip()
print room_info['info']
#房源的位置信息
room_info['position_info']= soup.find('h3',text=u'地址和交通').find_next_siblings('ul')[-1].text.strip().replace('\n','').replace(' ','')
print room_info['position_info']
#将房源信息存入room_list列表
room_info_list.append(room_info)
#获取公寓信息
def get_apartment_info(url):
room_info ={
'url':url}
res = requests.get(url=url,headers=headers,verify=False)
if res.status_code == 200:
#bs解析文档
soup = BeautifulSoup(res.text,'lxml')
p = soup.find('p',class_='content__aside--title')
room_info['title'] = p.span.text.strip()
room_info['price'] = p.find_all('span')[1].text.strip()
room_info['position_info'] = soup.find('p',class_='flat__info--subtitle').text.strip().split(' ')[0]
for k,v in room_info.items():
print k,v
room_info_list.append(room_info)
#爬虫函数
def spider():
#页码
i = 1
while True:
print 'page',i
url = '%spg%d/'% (sys.argv[1][:-1],i)
print url
res = requests.get(url=url,headers=headers,verify=False)
if res.status_code == 200:
if u'没有找到相关房源' in res.text:
print u'没有找到相关房源'
break
#使用bs4解析html文档
soup = BeautifulSoup(res.text,'lxml')
#找到每个房源的标签
content_list =soup.find('div',class_='content__list').find_all('div',class_='content__list--item')
for item in content_list:
#房源的url
room_url = 'https://bj.zu.ke.com' + item.a['href']
try:
#若为公寓
if 'apartment' in room_url:
get_apartment_info(room_url)
#其它的房源
else:
get_room_info(room_url)
except Exception as e:
#若出现错误不处理
print e
i += 1
#主函数
def main():
try:
spider()
finally:
#将房源信息序列化存储在本地
pickle.dump(room_info_list,open('%s.db' % sys.argv[2],'wb'))
#将房源信息以csv格式输出到本地
keys =['title','price','tags','info','position_info','url']
content = [','.join(keys)]
for item in room_info_list:
line = [item.get(x,'') for x in keys]
line =','.join(map(lambda x:x.encode('utf-8').replace(',',''),line))
content.append(line)
open('%s.csv' % sys.argv[2],'w').write('\n'.join(content))
main()
结果
结果如下图所示,这是15号地铁沿线的房源信息
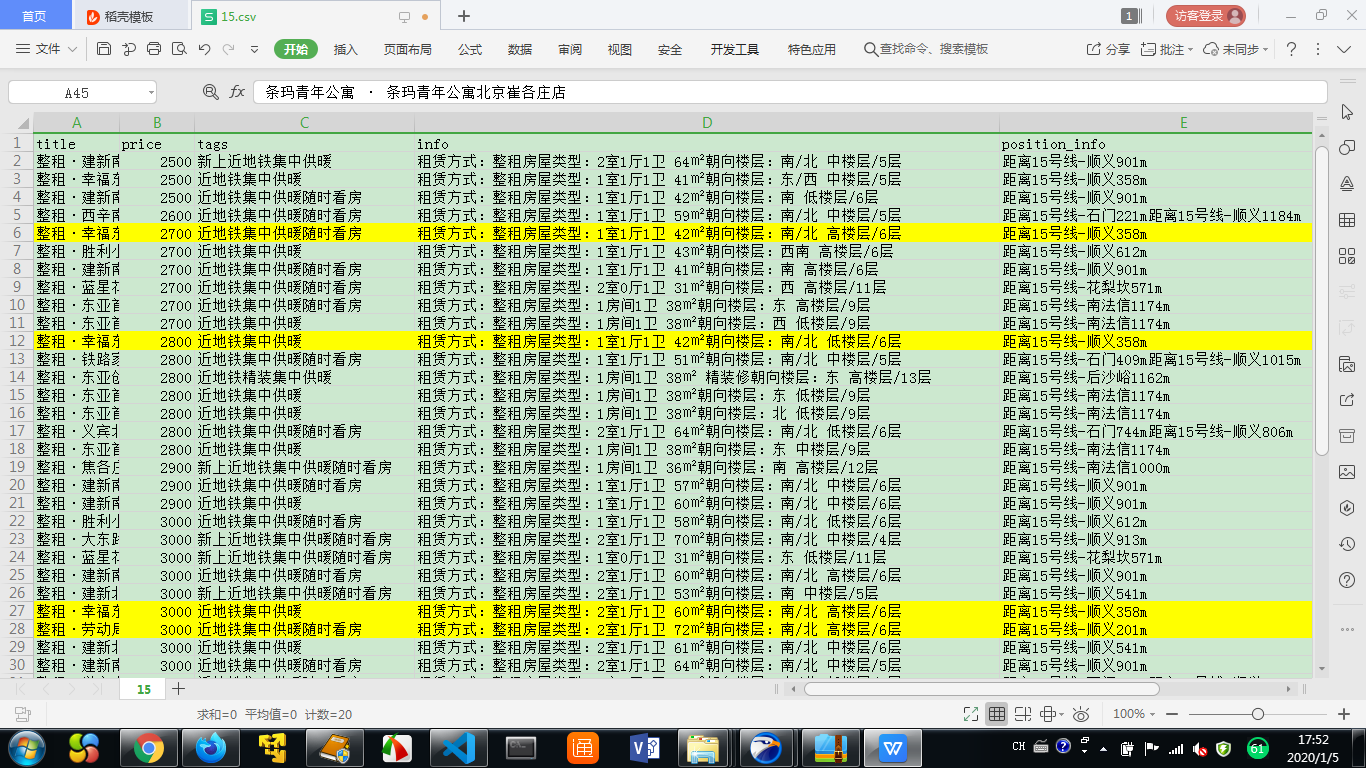
使用wps打开csv文件,房源的租金,地理位置(主要是距离地铁站的距离)等一目了然,便于我们快速的筛选出需要关注的房源。
参考资料
- bs4中文文档
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#