爬虫思路分析:
1. 观察小猪短租(北京)的网页
首页:http://www.xiaozhu.com/?utm_source=baidu&utm_medium=cpc&utm_term=PC%E6%A0%87%E9%A2%98&utm_content=pinzhuan&utm_campaign=BDPZ
选择“北京”,然后点“搜索小猪”,获取北京市的首页url:http://bj.xiaozhu.com/
观察右侧详情,页面最下面有分页,点击第2、第3页观察url的变化
http://bj.xiaozhu.com/search-duanzufang-p2-0/
http://bj.xiaozhu.com/search-duanzufang-p3-0/
验证首页是否可以写作:http://bj.xiaozhu.com/search-duanzufang-p0-0/(答案是ok的,大部分分页行的网站首页都是可以与其他分页统一化的)
因此,分页的URL可以这么构造:http://bj.xiaozhu.com/search-duanzufang-p{}-0/.format(number),其中number是几就是第几页

2. 观察右侧的信息,发现每个房源的信息不全,需要手动点击进去才能看到详情
因此需要获取每个房源的详情页面的URL
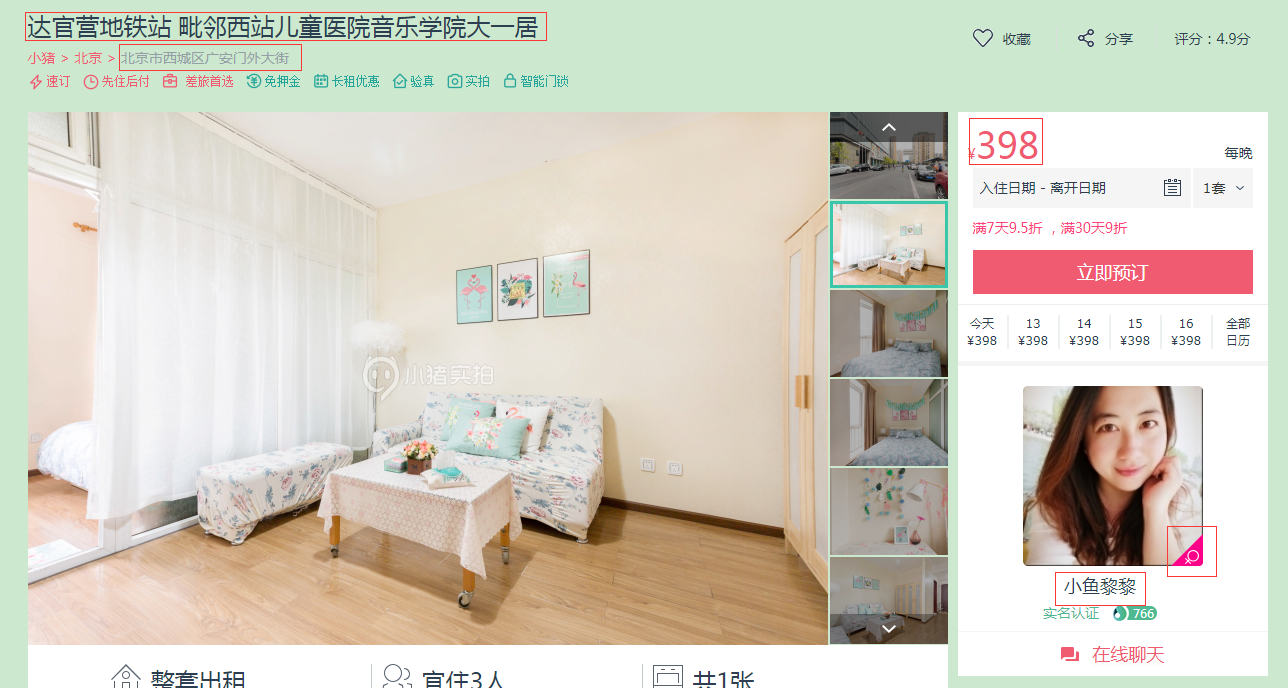
3. 观察某一房源的详细信息,这里我们提取“标题、地址、价格、房东名字、性别”等
源代码:
import requests
from bs4 import BeautifulSoup as bs
4
headers = {
'User-Agent':'User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
"""获取每一个房源的网址,参数是分页url"""
def get_link(url):
html_data = requests.get(url, headers = headers)
soup = bs(html_data.text, 'lxml')#bs4推荐使用的的解析库
#print(soup.prettify()) #标准化输出url中的源代码(有可能跟网页查看中的不一致,网页中有可能标签书写不规范)以此为基础抓取,如果抓取失败,用此命令查看源代码
links = soup.select('#page_list > ul > li > a')#注意循环点!!!直接粘贴过来的是“#page_list > ul > li:nth-child(1) > a > img”,需要去掉:nth-child(1),注意每个标签前后有空格
#print(links)
for link in links:
link = link.get('href')
#print(link)
get_info(link)
"""
"""#获取每一个房源的详细信息,参数url是每个房源的网址"""
def get_info(url):
html_data = requests.get(url, headers = headers)
soup = bs(html_data.text, 'lxml')#bs4推荐使用的的解析库
# print(soup.prettify()) #标准化输出url中的源代码(有可能跟网页查看中的不一致,网页中有可能标签书写不规范)以此为基础抓取,如果抓取失败,用此命令查看源代码
title = soup.select('div.wrap.clearfix.con_bg > div.con_l > div.pho_info > h4 > em')[0].string
# 用网页copy过来的全部是“body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > h4 > em”,但是使用这个爬不出来数据(我也不知道why),把body去掉或者用下面最简短的方式(只使用最近的且唯一的div)
# title = soup.select('div.pho_info > h4 > em ')
# 查询结果title格式是一维列表,需要继续提取列表元素(一般就是[0]),列表元素是前后有标签需要继续提取标签内容,使用get_text()或者string
address = soup.select('div.wrap.clearfix.con_bg > div.con_l > div.pho_info > p > span')[0].string.strip()
price = soup.select('#pricePart > div.day_l > span')[0].string.strip() # div中的id=pricePart是唯一性的,因此不用写前面的div
name = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > a')[0].string.strip()
img = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img')[0].get('src').strip() # 获取标签的属性值
sex = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > div')[0].get('class')[0].strip() # 获取标签的属性值
#将详细数据整理成字典格式
data = {
'标题':title,
'地址':address,
'价格':price,
'房东姓名':name,
'房东性别':sex,
'房东头像':img
}
print(data)
"""
"""#程序主入口"""
if __name__=='__main__':
for number in range(0,1):
url = 'http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(number) #构造分页url(不是房源详情的url)
get_link(url)