前言:
通过上次的TripAdvisor爬虫实战,我们学会了如何使用requests发送一个网页请求,并使用BeautifulSoup来解析页面,从中提取出我们的目标内容,并将其存入文档中。同时我们也学会了如何分析页面,并提取出关键数据。
下面我们将进一步学习,并爬去小猪短租的详情页面,提取数据。
Just do it~~!
目标站点分析
目标URL:http://bj.xiaozhu.com/search-duanzufang-p1-0/
明确内容:
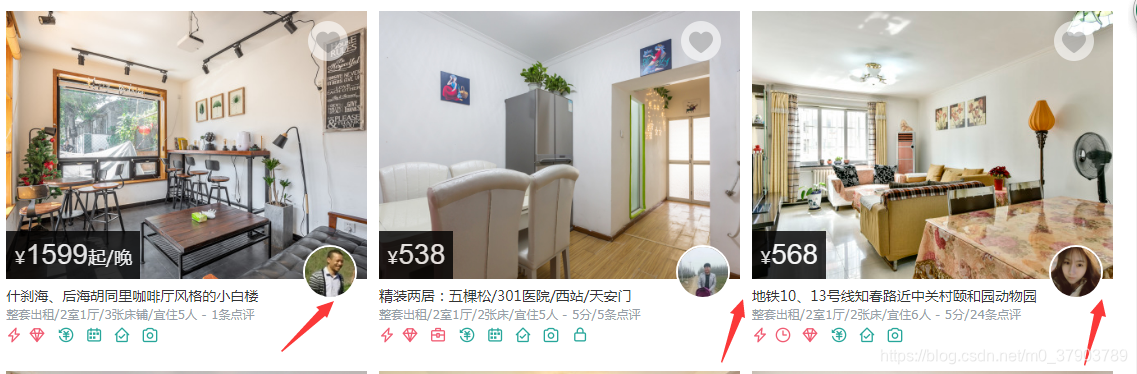
在点击URL后我们进入了列表页面,在列表页面没有我们想要的信息,我们需要进入详情页面,看有没有我们所需要的数据。
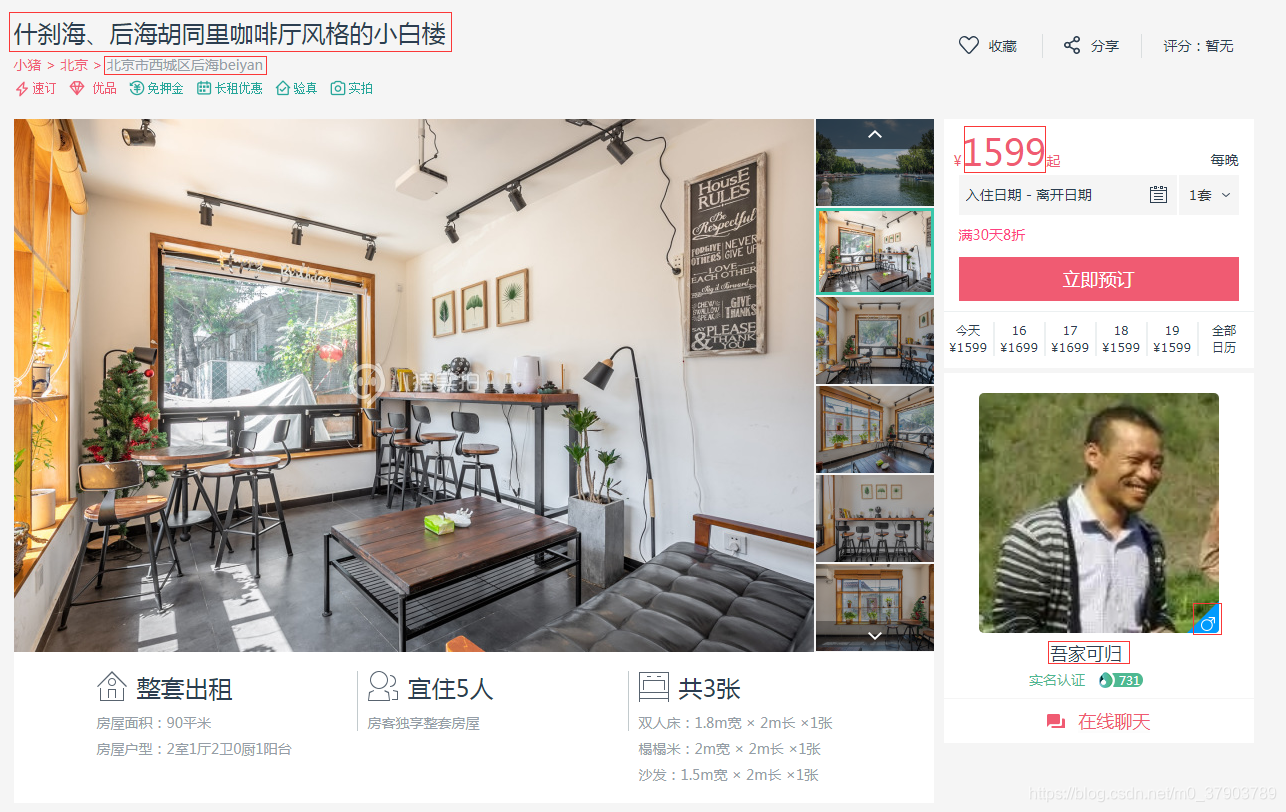
在详情页面中,我们找的了我们需要的数据:如title,address,price,host_name,host_gender等(红色方框中的内容),当然我们也可以提取详情页中的图片,居住人数等,这就当个小练习,交给大家实现吧~
下面我们需要遍历所有的列表页面,提取所有的详情页面URL,再提取详情页中的目标数据。
业务逻辑:
1.查找规律,遍历所有的列表页,再下翻几页后,我们发现***pX***(其中X为1,2,3,4…)
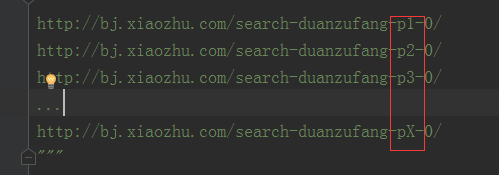
2.提取列表页中的详情页URL
# 解析列表页面,并提取详情页的URL
def parse_html(self, html):
soup = BeautifulSoup(html, 'lxml')
lis = soup.select("div#page_list > ul > li")
for li in lis:
# 提取详情页URL
page_url = li.select("a")[0].attrs['href']
3.提取详情页的数据
# 解析详情页,并提取数据
def parse_page(self, html):
item_list = []
soup = BeautifulSoup(html, 'lxml')
temp_title = soup.select('div.pho_info > h4')[0].get_text()
title = temp_title.replace('\n', '')
address = soup.select("div.pho_info > p")[0].get('title')
price = soup.select("div.day_l > span")[0].get_text()
host_name = soup.select("a.lorder_name")[0].get_text()
host_gender = soup.select("div.member_pic > div")[0].get('class')[0]
4.保存数据,并放入文档中
# 保存数据
def save_item(self, item_list):
with open('XiaoZhu.txt', 'a+', encoding='utf-8') as f:
for item in item_list:
json.dump(item, f, ensure_ascii=False, indent=2)
f.close()
print("Save success!")
结果展示

好了,本次讲解,到这里就差不多该结束啦~感兴趣的同学,可以动手试试。
源码地址:https://github.com/NO1117/XiaoZhu_Spider
Python交流群:942913325 欢迎大家一起交流学习