学习python也有一段时间了,就写一个小爬虫来试试身手!
我选择爬的是虎扑网站上面的图片。
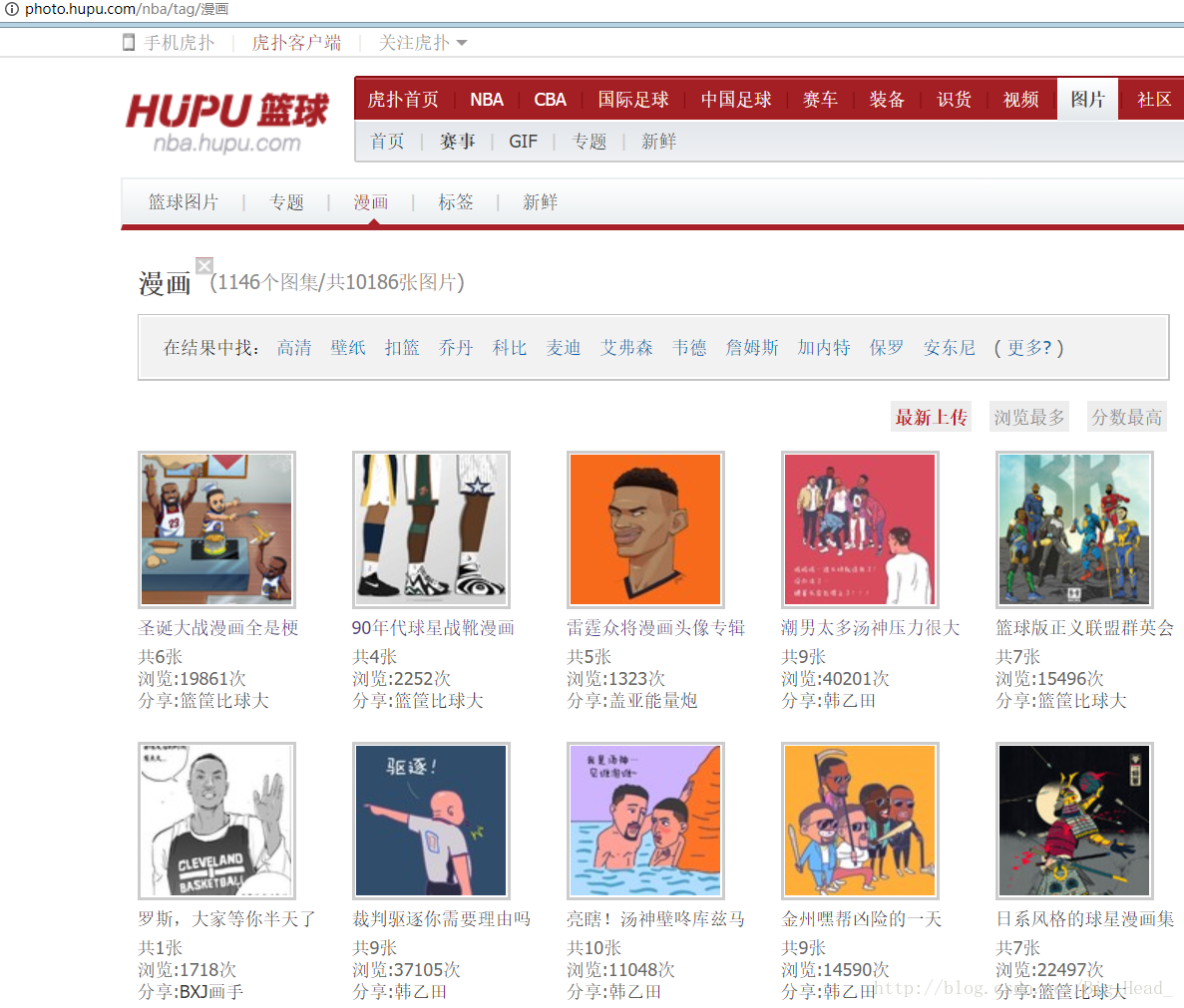
这就是我要爬的网站,最终我要把这个页面上面的图片全部爬取下来。
(由于我不会封装对象,所以我是用函数式编程)
用到的模块有4个:
- requests
- BeautifulSoup
- urllib.requests (我用的python 3.6,所以urllib模块被分割成几个小模块,如果是2.7就直接导入urllib就行了
- os
首先解析目标网页:http://photo.hupu.com/nba/tag/%E6%BC%AB%E7%94%BB
def get_rtext(link, headers):
try:
r = requests.get(link, headers=headers)
return r.text
except:
print('get_rtext error')要在此页面进入到图片的页面,那就要得到跳转的链接,那就找找呗。
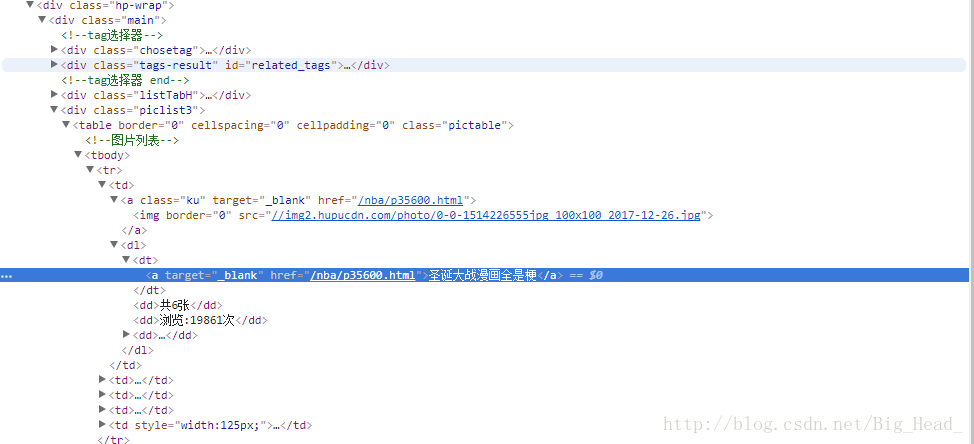
我发现所有链接都在<table border='0'..........>这个标签下面的<a href=.......>里面
那就很简单了,用BeautifulSoup先找到table的标签,再找到全部的a标签,最后解析出里面的链接就行了。
def get_soup(html):
try:
soup = BeautifulSoup(html, "html.parser")
return soup
except:
print('get_soup error')
def find_urls(soup):
try:
targer = soup.find("table", {"border": "0"})
each_url = targer.find_all("a", {"class": "ku"})
return each_url
except:
print('find_urls error')但是看了看爬出来的链接:/nba/p35600.html
欸?好像和目标有些出入喔? 目标:http://photo.hupu.com/nba/p35600.html
稍稍分析一下发现就是少了http://photo.hupu.com
那只需要拼接一下就行了。
base = "http://photo.hupu.com"
each_target = base + each_url这样就得到了每个url,现在要对每个url再次解析,找到图片所对应的链接。
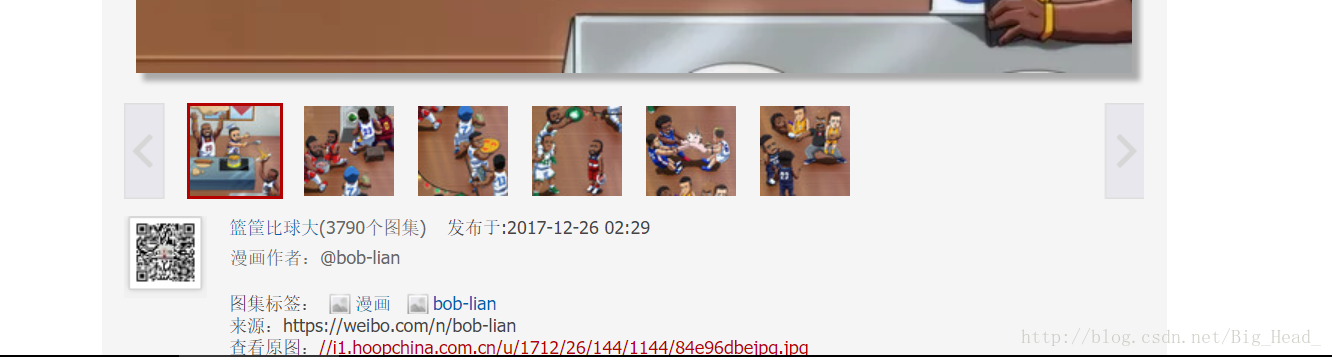
欸?发现每张图片都是一个网页………我的天。
但是翻了一页就发现,网址有规律欸…….
- http://photo.hupu.com/nba/p35600.html
- http://photo.hupu.com/nba/p35600-2.html
- http://photo.hupu.com/nba/p35600-3.html
第一个就是原本爬出来的url,后面的都是-2-3-4……这样递增的
只要用split分割字符串,再拼接起来就行了:
temp = each_target.split('.html')[0] + str('-') + str(a) + str('.html')用一个循环就可以得到若干url
然后再取解析这个网页,找到图片的链接,就可以下载了。
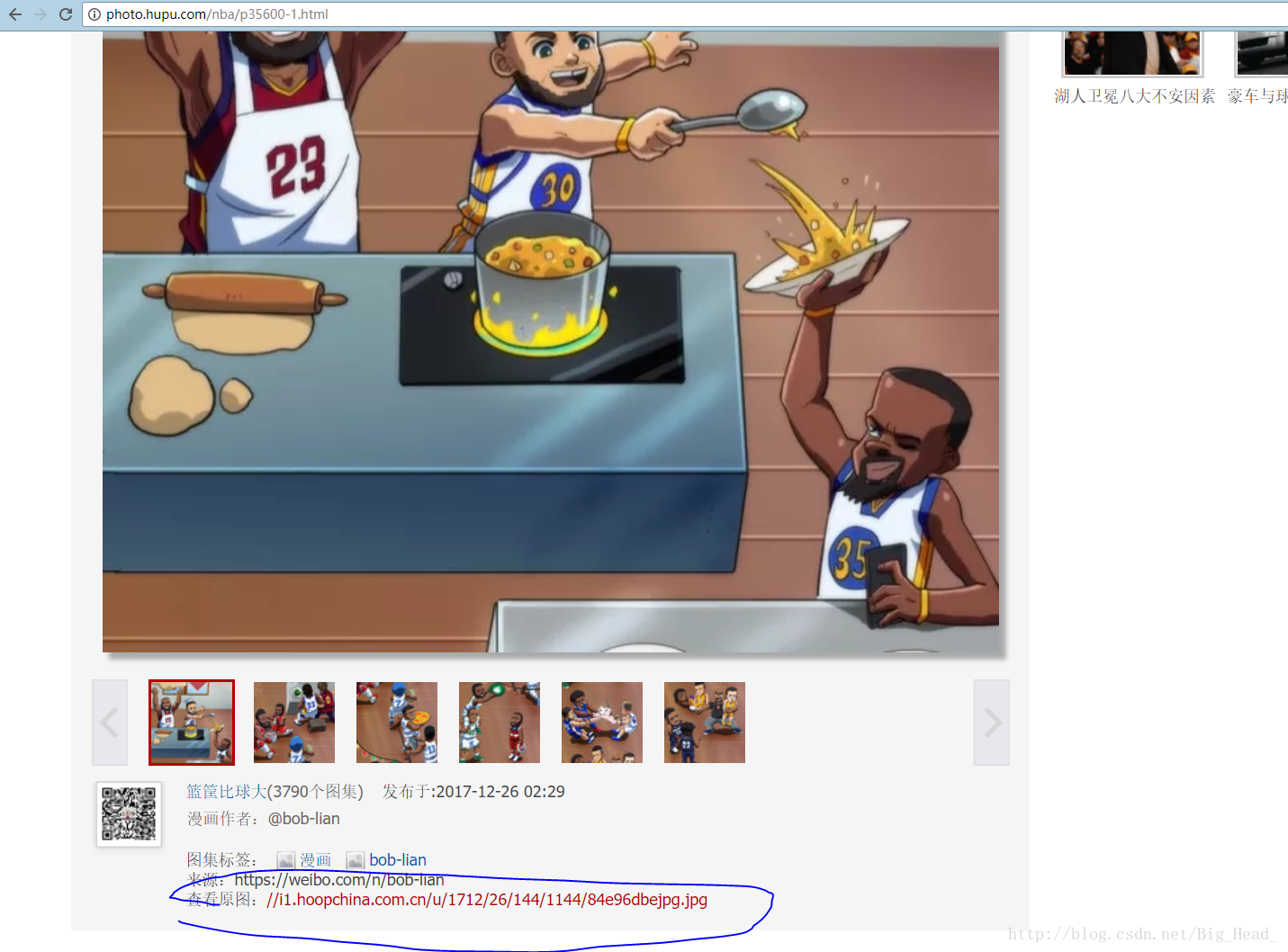
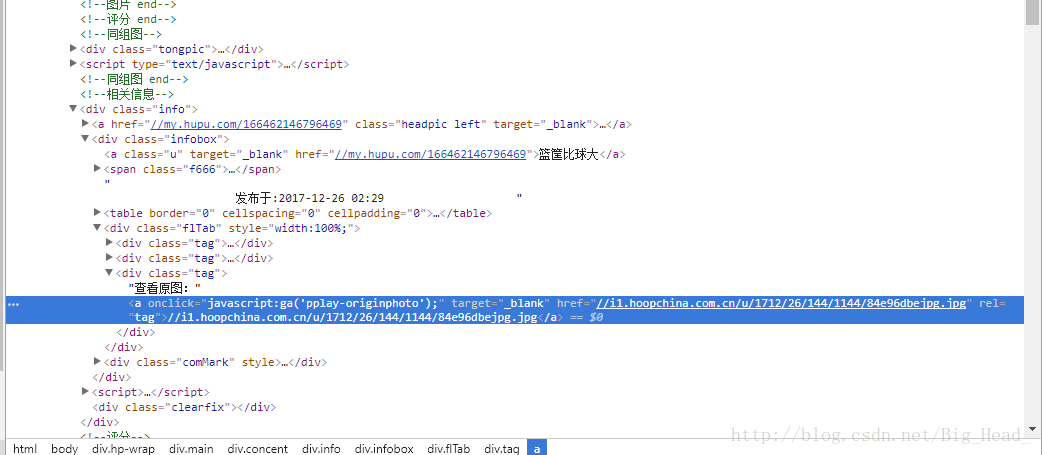
和上面一样,用美丽的汤(BeautifulSoup)解析出这个地址就行了。
def img_url(each_target):
# print(each_target)
try:
html_ = get_rtext(each_target, headers=headers)
soup_ = get_soup(html_)
# print(soup)
img_ipg = soup_.find("a", {"onclick": "javascript:ga('pplay-originphoto');"})
return img_ipg.attrs['href']
except:
return 'F'这样就得到了img的url://i1.hoopchina.com.cn/u/1712/26/144/1144/84e96dbejpg.jpg
发现前面少了http:// ,那就加上去就好了。
img1 = 'http:'
img = img1 + img2最终就是保存图片了。
这里用到os模块,这部分我不是很熟悉,就借用了大牛的代码,实现了把图片放在运行目录下的目标文件夹里面,如果没有文件夹就创建一个新的。
> def save_img(img_url, file_name, file_path='img3\\'):
> # 保存图片到磁盘文件夹 file_path中,默认为当前脚本运行目录下的 book\img文件夹
> try:
> if not os.path.exists(file_path):
> print('文件夹', file_path, '不存在,重新建立')
> # os.mkdir(file_path)
> os.makedirs(file_path)
> # 获得图片后缀
> file_suffix = os.path.splitext(img_url)[1]
> # print(os.path.splitext(img_url))
> # 拼接图片名(包含路径)
> filename = '{}{}{}{}'.format(file_path, os.sep, file_name, file_suffix)
> print(filename)
> # print(filename)
> # 下载图片,并保存到文件夹中
> urllib.request.urlretrieve(img_url, filename=filename)
> except IOError as e:
> print('错误:', e)
> except Exception as e:
> print('错误 :', e)
最后只需要把上面的函数全部拼装起来就可以了话不多说直接上代码:
import requests
from bs4 import BeautifulSoup
import urllib.request
import os
def save_img(img_url, file_name, file_path='img3\\'):
# 保存图片到磁盘文件夹 file_path中,默认为当前脚本运行目录下的 book\img文件夹
try:
if not os.path.exists(file_path):
print('文件夹', file_path, '不存在,重新建立')
# os.mkdir(file_path)
os.makedirs(file_path)
# 获得图片后缀
file_suffix = os.path.splitext(img_url)[1]
# print(os.path.splitext(img_url))
# 拼接图片名(包含路径)
filename = '{}{}{}{}'.format(file_path, os.sep, file_name, file_suffix)
print(filename)
# print(filename)
# 下载图片,并保存到文件夹中
urllib.request.urlretrieve(img_url, filename=filename)
except IOError as e:
print('错误:', e)
except Exception as e:
print('错误 :', e)
def get_rtext(link, headers):
try:
r = requests.get(link, headers=headers)
return r.text
except:
print('get_rtext error')
def get_soup(html):
try:
soup = BeautifulSoup(html, "html.parser")
return soup
except:
print('get_soup error')
def find_urls(soup):
try:
targer = soup.find("table", {"border": "0"})
each_url = targer.find_all("a", {"class": "ku"})
return each_url
except:
print('find_urls error')
def img_url(each_target):
# print(each_target)
try:
html_ = get_rtext(each_target, headers=headers)
soup_ = get_soup(html_)
# print(soup)
img_ipg = soup_.find("a", {"onclick": "javascript:ga('pplay-originphoto');"})
return img_ipg.attrs['href']
except:
return 'F'
link = "http://photo.hupu.com/nba/tag/%E6%BC%AB%E7%94%BB"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"}
base = "http://photo.hupu.com"
html = get_rtext(link, headers)
soup = get_soup(html)
img_urls = find_urls(soup)
i = 0
for each in img_urls:
# print(each.attrs['href'])
each_url = each.attrs['href']
# print(each_url)
each_target = base + each_url
for a in range(1, 20):
if a == 1:
img2 = img_url(each_target)
if img2 == 'F':
break
img1 = 'http:'
img = img1 + img2
save_img(img, file_name=i)
i = i + 1
else:
temp = each_target.split('.html')[0] + str('-') + str(a) + str('.html')
img2 = img_url(temp)
if img2 == 'F':
break
img1 = 'http:'
img = img1 + img2
save_img(img, file_name=i)
i = i + 1(新手没能把代码更简介一点(lll¬ω¬))
当当当当!!!爬了许久,把四百多张图片给爬了下来。
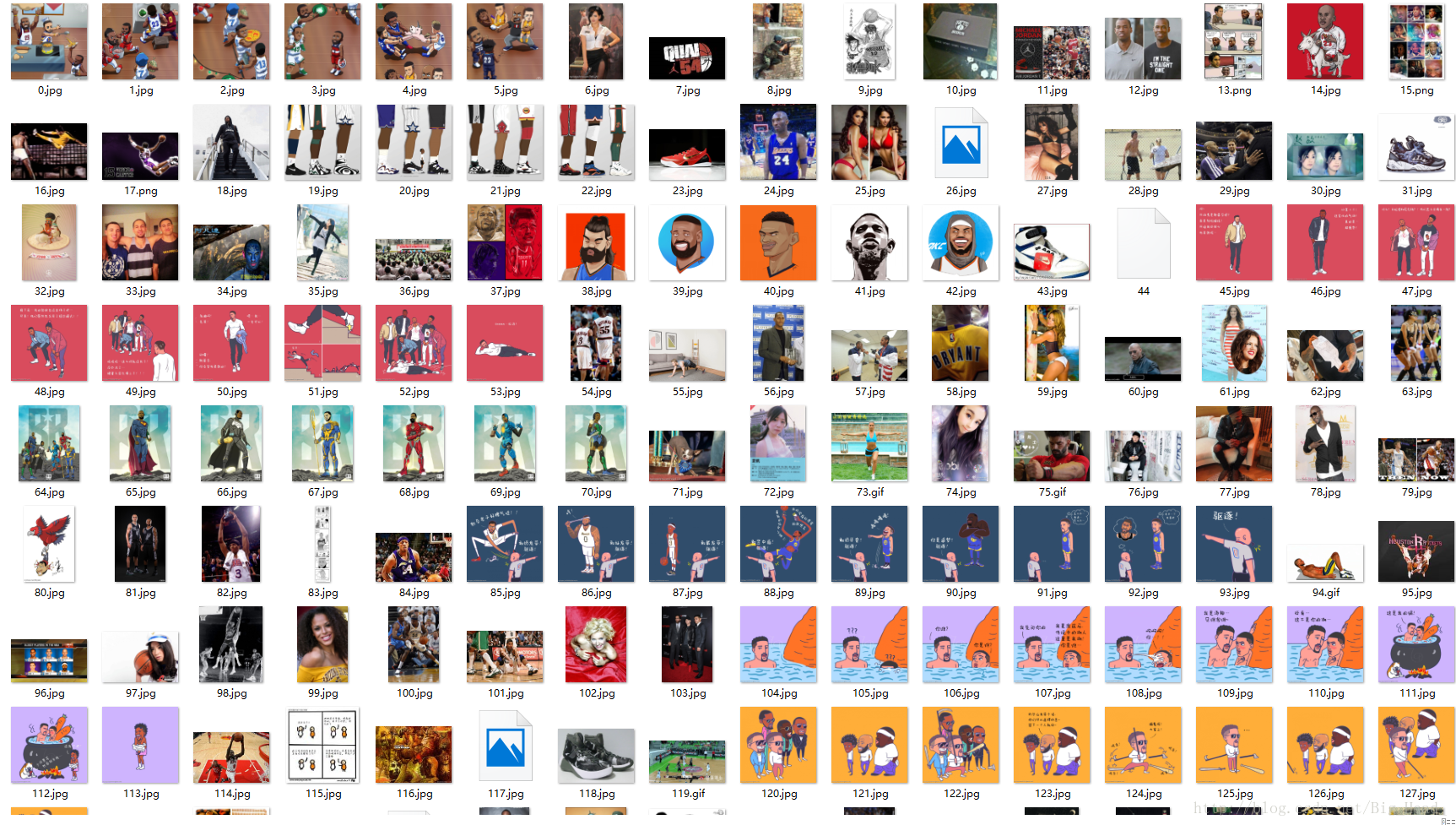
这次我只是爬取了专栏的第一页,以后再完善到可以爬取任意页数,还要提升一下速度,毕竟这个速度真的是有点慢………..还要加上cookie,完善请求头,避免大量爬取的时候被虎扑给拒绝访问。好了,就这样了,熄灯睡觉~