目标站点分析
目标URL:https://www.tripadvisor.cn/Attractions-g60763-Activities-New_York_City_New_York.html#FILTERED_LIST
明确内容:
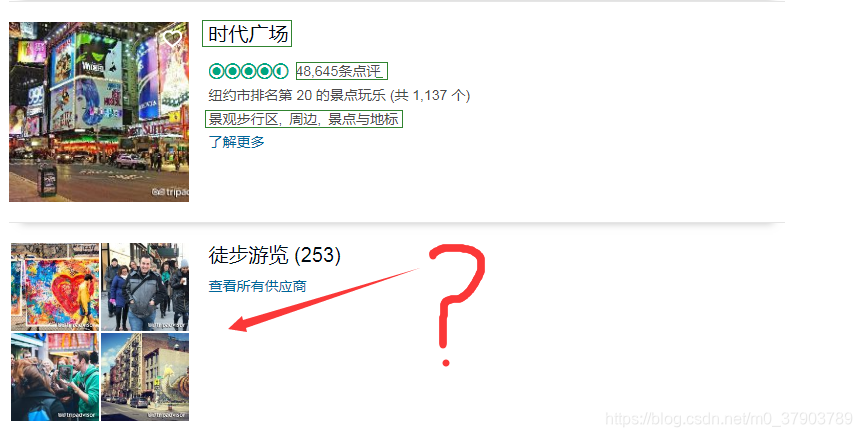
在图中,我们明确爬去的内容为:title,comment, cate(即绿色框中的内容),同时我们也可以看到一些干扰内容,这是我们不需要的内容,需要剔除掉。那我们该如何剔除这些干扰内容呢?(小提示:观察不同之处)
好了,找好了爬去的内容,下面就是怎么去爬去所有的页面呢?

我们看到这里总共有41个页面,那我们该怎么爬完所有的页面呢?
这里主要有两个方案:
1.找寻页面之间的规律,并依照它的规律去遍历
2.一直点击下一页,直到无法点击
这里实现了方案一:

通过对比,我们发现,页面似乎很有规律,-oaXX,并且XX是以30为步进单位。我们便可以依照这个规律,去遍历所有的网页啦!
for i in range(0, self.max_num):
url = "https://www.tripadvisor.cn/Attractions-g60763-Activities-oa{}-New_York_City_New_York.html".format(i*30)
**动动手**
感兴趣的童鞋,试试如何实现方案二吧~
逻辑实现
def run(self):
# 1.Find URL
for i in range(0, self.max_num):
url = self.temp_url.format(i*30)
# 2.Send Request, Get Response
html = self.parse_url(url)
# 3.Get item
if html:
item = self.parse_html(html)
# 4.save information
self.save_item(item)
战绩展示
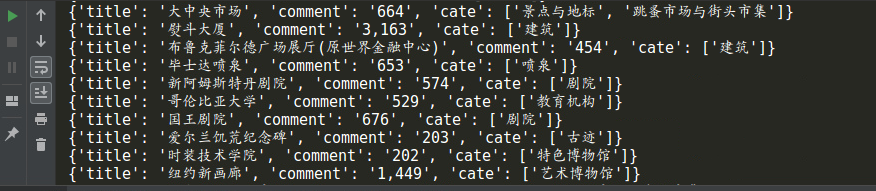
源码地址:https://github.com/NO1117/TripAdvisor_Spider
Python交流群:942913325 欢迎大家一起交流学习