scrapy框架
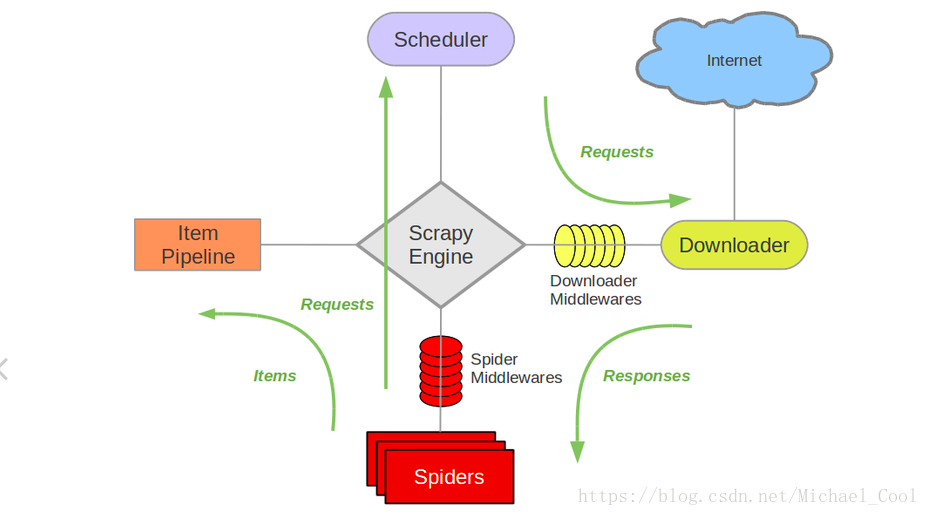
- scrapy是一个爬虫框架。由引擎,爬虫程序,调度表,下载器以及管道组成。
- 引擎负责其他四个模块的调度
- 爬虫程序是爬虫的起点,负责生成url以及对下载器下载的response的处理
- 调度表是对传过来的url进行封装,形成request队列
- 下载器负责请求网页,返回数据,以供爬虫程序进行解析
- 管道负责对返回后的item进行存储
架构图
框架执行步骤
- 爬虫程序提交url给引擎
- 引擎将url交给调度器,调度器生成request对象,传给引擎
- 引擎将request对象传给下载器进行下载,返回response对象
- 引擎将response对象传给爬虫程序,爬虫程序初步解析response将需要继续下载的url和一杯存储的item分别传给引擎
- 引擎将url传给调度器重复2-4步,将item传给管道
- 管道将item文件进行存储
爬虫的基本步骤
- 明确目标:明确要爬取的网站,网站内的信息点
- 请求网页获取,数据
- 对数据进行解析,清洗
- 对解析后的数据进行存储
scrapy的基本操作
scrapy的基本操作
1.创建爬虫的项目
scrapy startproject xxx
2.创建爬虫的文件
cd xxx
scrapy genspider 名字 范围
3.运行爬虫
scrapy crawl 爬虫的名字
scrapy runspider xxx.py(注意点 必须是在爬虫文件路径下)
4.解析数据
4.1 items 文件 设置解析的key
4.2 在爬虫的文件中 解析数据 框架自动转换类型
.xpath().extract()[0]
4.3 yiled 给 引擎 -->管道
5.数据存储
5.1 不管管道 自己存 scrapy crawl xxx -o 文件名字
5.2 使用管道
pipelinse
1.开启爬虫
2.process_item()
3.关闭爬虫
4.千万注意: 最后在setting 开启管道
scrapy shell 测试 解析的数据是否正确
1. 如果 是在项目路径下 默认会加载 项目的settings
2. 桌面 路径, 需要自己设置
scrapy shell "url" -s key=value
3. 测试
/text()
/@属性
extract() --list
extract_first() 返回字符串 None
// css 选择器
response.css(".acloud ::text")
response.css(".acloud ::attr('bz')")
示例:爬取腾讯社招网站上海的所有招聘信息

setting.py
BOT_NAME = 'Tencent'
SPIDER_MODULES = ['Tencent.spiders']
NEWSPIDER_MODULE = 'Tencent.spiders'
USER_AGENT="Mozilla/5.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12A365 Safari/600.1.4"
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'Tencent.pipelines.TencentListPipeline': 300,
}
tencent3.py
# -*- coding: utf-8 -*-
import scrapy
from Tencent.items import TencentListItem
class Tentent_Spider(scrapy.Spider):
# 1.爬虫名字
name = 'tencent3'
# 2. 爬虫的范围
allowed_domains = ['tencent.com']
base_url = 'https://hr.tencent.com/position.php?keywords=&tid=0&lid=2175&start='
url_list = []
for page in range(0, 6):
url = base_url + str(page * 10)
url_list.append(url)
# 3. 开始的Url
start_urls = url_list
def parse(self, response):
# 解析数据
tr_list = response.xpath('//tr[@class="even"]|//tr[@class="odd"]')
# 遍历
for tr in tr_list:
item = TencentListItem()
item['work_name'] = tr.xpath('./td/a/text()').extract_first()
item['work_type'] = tr.xpath('./td[2]text()').extract_first()
item['work_count'] = tr.xpath('./td[3]text()').extract_first()
item['work_place'] = tr.xpath('./td[4]text()').extract_first()
item['work_time'] = tr.xpath('./td[5]text()').extract_first()
item['work_link'] = tr.xpath('./td/a/@href').extract_first()
# 发送详情页 的请求 --》引擎--》调度器
yield scrapy.Request(url=item['work_link'], meta={'tencentItem': item}, callback=self.detail_parse)
# 解析详情页的数据
def detail_parse(self, response):
ul_list = response.xpath('//ul[@class="squareli"]')
item = response.meta['tencentItem']
item['work_duty'] = "".join(ul_list[0].xpath('.li/text()').extract())
item['work_requir'] = "".join(ul_list[1].xpath('./li/text()').extract())
# 数据解析完毕 交给 引擎--》管道
yield item
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TencentListItem(scrapy.Item):
work_name = scrapy.Field()
work_type = scrapy.Field()
work_count = scrapy.Field()
work_place = scrapy.Field()
work_time = scrapy.Field()
work_link = scrapy.Field()
work_duty = scrapy.Field()
work_require = scrapy.Field()
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class TencentListPipeline(object):
# 打开文件
def open_spider(self, spider):
self.file = open('tententList.json', 'w')
# 转换格式,写入文件
def process_item(self, item, spider):
# 判断 item是列表页还是详情页
str_item = json.dumps(dict(item)) + '\n'
self.file.write(str_item)
return item # 给其他管道使用
# 关闭文件
def close_spider(self, spider):
self.file.close()
结果
