今天是一个项目——www.aqistudy.cn 全国空气质量历史数据存储的网站的爬取。
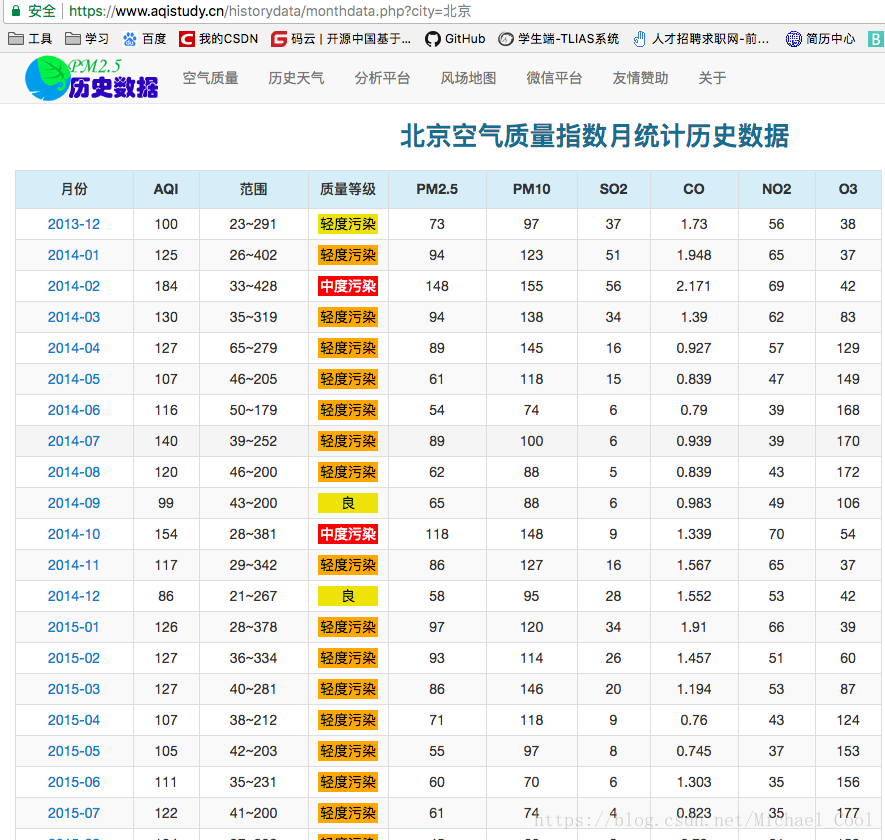
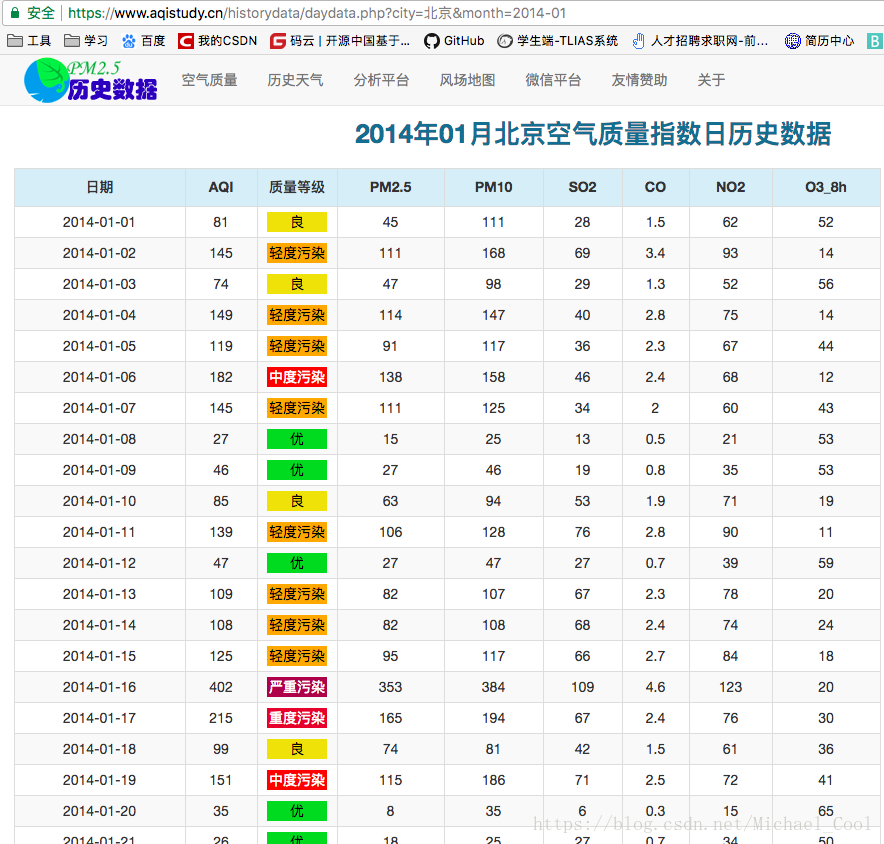
- 使用spider爬取,分别存储为json文件,csv文件,存储到mongoDB中,redis数据库中;使用crawl_spider爬取;scrapy-redis分布式,spider爬取及crawl_spider爬取;
spider爬取
步骤:
- 确认目标数据-爬取每天的历史数据
- 确认网页层级:城市一层,为静态页面;月度数据为第二层,是动态HTML页面;日数据为第三层,是动态HTML页面
- items.py
- aqi.py
- pipeline.py
- 使用download中间件,使用selinium+chrome模拟浏览器发起请求,自定义response对象,直接返回
- settings.py的设置
代码
items.py
import scrapy
class AqiItem(scrapy.Item):
# 城市的名字
city_name = scrapy.Field()
# 1.日期
data = scrapy.Field()
# 2.空气质量系数
aqi = scrapy.Field()
# 3.质量等级
q_level = scrapy.Field()
# 4.PM2.5
pm2_5 = scrapy.Field()
# 5.PM10
pm10 = scrapy.Field()
# 6.so2
so2 = scrapy.Field()
# 7.co
co = scrapy.Field()
# 8.no2
no2 = scrapy.Field()
# 9.o3_8h
o3 = scrapy.Field()
# 数据源
data_source = scrapy.Field()
# 下载时间
data_time = scrapy.Field()
aqi.py
# -*- coding: utf-8 -*-
import scrapy
from AQI.items import AqiItem
class AqiSpider(scrapy.Spider):
name = 'aqi'
allowed_domains = ['aqistudy.cn']
start_urls = ['https://www.aqistudy.cn/historydata/']
base_url = 'https://www.aqistudy.cn/historydata/'
def parse(self, response):
# 获取城市名列表
city_name_list = response.xpath('/html/body/div[3]/div/div[1]/div[2]/div[2]/ul/div[2]/li/a/text()').extract()[0:1]
# 获取月份url列表:
link_list = response.xpath('/html/body/div[3]/div/div[1]/div[2]/div[2]/ul/div[2]/li/a/@href').extract()[0:1]
# 遍历列表
for name, link in zip(city_name_list, link_list):
# 给城市名赋值
item = AqiItem()
item['city_name'] = name
# 完整的link
link = self.base_url + link
# 发起请求,获取月度信息
yield scrapy.Request(url=link, meta={'api_item':item}, callback=self.parse_month)
def parse_month(self, response):
# 获取月度信息url列表
month_url_list = response.xpath('/html/body/div[3]/div[1]/div[1]/table//tr/td[1]/a/@href').extract()[1:2]
# 遍历
for month_url in month_url_list:
# 完整的url
month_url = self.base_url +month_url
# 取出item,再次传递
item = response.meta['api_item']
# 发送请求,获取每天的数据页面
yield scrapy.Request(url=month_url, meta={'api_item':item}, callback=self.parse_day)
def parse_day(self, response):
# 获取所有的tr标签
tr_list = response.xpath('//tr')
# 第一个tr标签不使用,应该删除掉
tr_list.pop(0)
print '**'*40
print tr_list
# 循环列表
for tr in tr_list:
# 获取目标数据
item = response.meta['api_item']
# 1.日期
item['data'] = tr.xpath('./td[1]/text()').extract_first()
# 2.空气质量系数
item['aqi'] = tr.xpath('./td[2]/text()').extract_first()
# 3.质量等级
item['q_level'] = tr.xpath('./td[3]/span/text()').extract_first()
# 4.PM2.5
item['pm2_5'] = tr.xpath('./td[4]/text()').extract_first()
# 5.PM10
item['pm10'] = tr.xpath('./td[5]/text()').extract_first()
# 6.so2
item['so2'] = tr.xpath('./td[6]/text()').extract_first()
# 7.co
item['co'] = tr.xpath('./td[7]/text()').extract_first()
# 8.no2
item['no2'] = tr.xpath('./td[8]/text()').extract_first()
# 9.o3_8h
item['o3'] = tr.xpath('./td[9]/text()').extract_first()
# --->引擎---》管道
yield item
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
from datetime import datetime
from scrapy.exporters import CsvItemExporter
import pymongo
import redis
class AqiDataPipeline(object):
def process_item(self, item, spider):
# 数据源
item['data_source'] = spider.name
# 下载时间
item['data_time'] = str(datetime.utcnow())
return item
# json管道
class AqiJsonPipeline(object):
def open_spider(self, spider):
self.file = open('api.json', 'w')
def process_item(self, item, spider):
str_item = json.dumps(dict(item)) + '\n'
self.file.write(str_item)
return item
def close_spider(self, spider):
self.file.close()
middlewares.py
from selenium import webdriver
import scrapy
import time
# 通过中间件自定义 webdriver的下载器
class ChromeMiddlewares(object):
def process_request(self, request, spider):
# 网址
url = request.url
# 判断,如果首页,不需要自定义
if url != 'https://www.aqistudy.cn/historydata/':
# 发送请求
driver = webdriver.Chrome()
driver.get(url)
# 注意添加延迟
time.sleep(2)
# 获取数据
data = driver.page_source
# 关闭浏览器
driver.quit()
# 构建自己的response对象,直接返回
return scrapy.http.HtmlResponse(url=url, body=data.encode('utf-8'), encoding='utf-8', request=request)
settings.py
BOT_NAME = 'AQI'
SPIDER_MODULES = ['AQI.spiders']
NEWSPIDER_MODULE = 'AQI.spiders'
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES = {
'AQI.middlewares.ChromeMiddlewares': 543,
}
ITEM_PIPELINES = {
'AQI.pipelines.AqiDataPipeline': 100,
}
结果
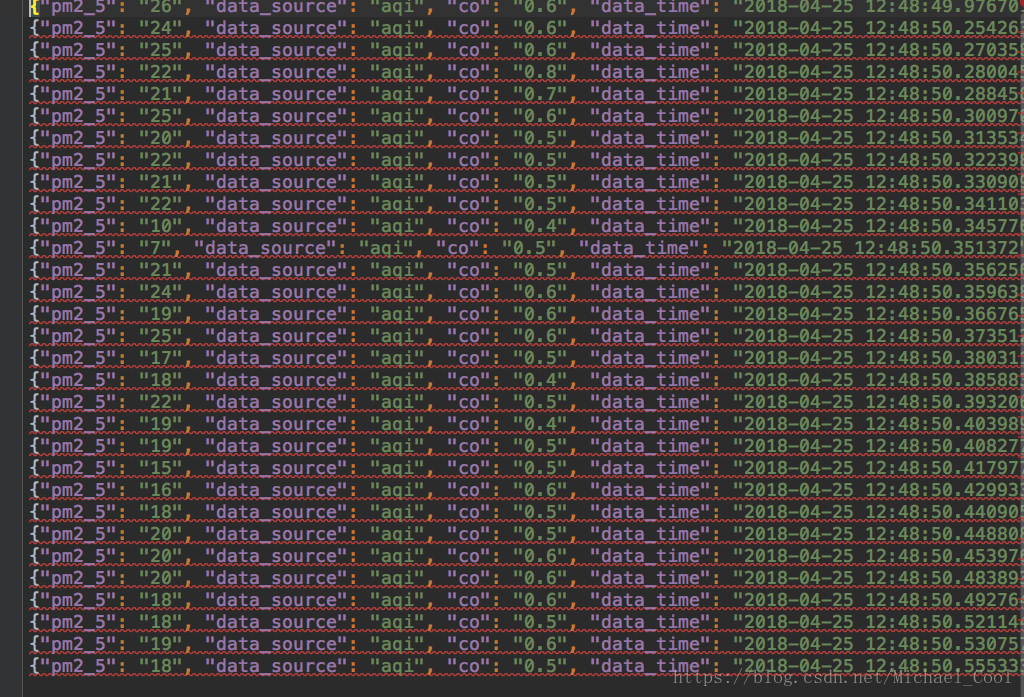
其他存储方式
csv管道
# csv的管道
class AqiCsvPipeline(object):
def open_spider(self, spider):
self.file = open('api.csv', 'w')
# 创建一个写入器
self.writer = CsvItemExporter(self.file)
# 声明开始导出
self.writer.start_exporting()
def process_item(self, item, spider):
self.writer.export_item(item)
return item
def close_spider(self, spider):
self.file.close()
self.writer.finish_exporting()
mongoDB管道
# 存储到MongoDB 注意,需要开启服务
class AqiMongoDBPipeline(object):
def open_spider(self, spider):
# 链接mongoDB数据库
self.client = pymongo.MongoClient('127.0.0.1', 27017)
self.db = self.client['AQI_Mongo']
self.collection = self.db['api']
def process_item(self, item, spider):
# 存储数据
self.collection.insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()
redis管道
# 存储到redis中
class ApiRedisPipeline(object):
def open_spider(self, spider):
self.client = redis.Redis('127.0.0.1', 6379)
def process_item(self, item, spider):
self.client.lpush('AQI_list', dict(item))
return item
spider_crawl爬取
aqi_scrawl.py
# -*- coding: utf-8 -*-
import scrapy
from AQI.items import AqiItem
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class AqiSpider(scrapy.Spider):
name = 'aqi_crawl'
allowed_domains = ['aqistudy.cn']
start_urls = ['https://www.aqistudy.cn/historydata/']
rules = (
# 1.提取城市的链接
Rule(LinkExtractor(allow='monthdata\.php\?city=')),
# 2.提取 月份的链接
Rule(LinkExtractor(allow='daydata\.php\?city='), callback='parse_day', follow=False),
)
def parse_day(self, response):
# 解析城市的名字
city_name = response.xpath('//h2[@id="title"]/text()').extract_first()
# 获取所有的tr标签
tr_list = response.xpath('//tr')
# 第一个tr标签不使用,应该删除掉
tr_list.pop(0)
# 循环列表
for tr in tr_list:
# 获取目标数据
item = AqiItem()
item['city_name'] = city_name[8:-11]
# 1.日期
item['data'] = tr.xpath('./td[1]/text()').extract_first()
# 2.空气质量系数
item['aqi'] = tr.xpath('./td[2]/text()').extract_first()
# 3.质量等级
item['q_level'] = tr.xpath('./td[3]/span/text()').extract_first()
# 4.PM2.5
item['pm2_5'] = tr.xpath('./td[4]/text()').extract_first()
# 5.PM10
item['pm10'] = tr.xpath('./td[5]/text()').extract_first()
# 6.so2
item['so2'] = tr.xpath('./td[6]/text()').extract_first()
# 7.co
item['co'] = tr.xpath('./td[7]/text()').extract_first()
# 8.no2
item['no2'] = tr.xpath('./td[8]/text()').extract_first()
# 9.o3_8h
item['o3'] = tr.xpath('./td[9]/text()').extract_first()
# --->引擎---》管道
yield item
- 其他文件跟aqi.py 一致
scrapy-redis分布式
spider
- 爬虫导入,并继承RedisSpider模块,设置分布式 识别的key
- 修改settings文件
api_redis.py
扫描二维码关注公众号,回复:
418807 查看本文章

...
from scrapy_redis.spiders import RedisSpider
class AqiSpider(RedisSpider):
name = 'aqi_redis'
allowed_domains = ['aqistudy.cn']
# 设置分布式 识别的key
redis_key = 'api:start_urls'
...
settings.py
...
# redis 分布式 四大组件: 调度器,过滤器, spider, item
# 1. 启用 分布式 过滤器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 2.启用 分布式 调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 3.启用 分布式 如果爬虫中断1000个 ,下次从中断的位置10001开始下载
SCHEDULER_PERSIST = True
# 4. redis的管道
# 设置redis host port
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
crawl_spider
- 导入并继承RedisCrawlSpider类,设置分布式 识别的key
- settings.py文件设置和spider一致
aqi_crawl_spider_redis.py
...
from scrapy_redis.spiders import RedisCrawlSpider
class AqiSpider(RedisCrawlSpider):
name = 'aqi_crawl_redis'
allowed_domains = ['aqistudy.cn']
# 设置 分布式识别的key
redis_key = 'api_crawl_redis'
...
- settings.py添加选项同 spider模块