1、Hadoop集群搭建(自学历程CentOS6.5)
1.1、配置虚拟机之间的免密访问
ssh-keygen -t rsa #生成公钥
ssh-copy-id [email protected] #将本机公钥复制到指定IP的虚拟机中
1.2、配置虚拟机之间的免ip(主机名访问)
vi /etc/hosts #配置主机名和ip的映射
# 例如
192.168.32.11 vm1
192.168.32.12 vm2
192.168.32.13 vm3
192.168.32.14 vm4
192.168.32.15 vm5
192.168.32.16 vm6
1.3、安装hadoop
本地上传hadoop
rz #上传文件,xshell会出现弹框选中上传的文件
解压hadoop包到指定的/local/文件夹下(文件夹自选)
tar -zxvf xxxxx -C /local/
解压的文件夹一般会有版本后缀,可以根据自己习惯重命名
cd /local/ #进入hadoop的解压目录
mv hadoopx.x.x hadoop #将hadoop文件夹重命名去掉版本号后缀
配置hadoop的环境变量
vi /etc/profile
# 在打开的文件下加入
export HADOOP_HOME=/local/hadoop
export $PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
(1)更改core-site.xml的内容
<configuration>
<property>
<name>fs.defaultFS</name>
<!--本机的名称:端口 -->
<value>hdfs://vm1:9000</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///local/hadoop/dfs/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
(2)更改hdfs-site.xml的内容
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>vm1:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>vm2:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(3)更改yarn-site.xml的内容
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>vm1</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>vm1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>vm1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>vm1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>vm1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>vm1:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>flase</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>6</value>
<description>每个任务使用的虚拟内存占物理内存的百分比</description>
</property>
</configuration>
(4)更改mapred-site.xml的内容
我的默认后缀有template所以先更名
mv 源文件名 更改的文件名
更改内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>vm1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>vm1:19888</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/local/hadoop/etc/*,
/local/hadoop/etc/hadoop/*,
/local/hadoop/lib/*,
/local/hadoop/share/hadoop/common/*,
/local/hadoop/share/hadoop/common/lib/*,
/local/hadoop/share/hadoop/mapreduce/*,
/local/hadoop/share/hadoop/mapreduce/lib/*,
/local/hadoop/share/hadoop/hdfs/*,
/local/hadoop/share/hadoop/hdfs/lib/*,
/local/hadoop/share/hadoop/yarn/*,
/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
<property>
<name>mapred.remote.os</name>
<value>Linux</value>
</property>
</configuration>
将hadoop拷贝到从节点上(三台机器路径要求一致,这样不需要三台都进行配置)
scp -r hadoop/ vm3:/local/
scp -r hadoop/ vm2:/local/
(5)在第一台机器上格式化
进入hadoop根目录
bin/hdfs namenode -format
chkconfig --level 2345 iptables off #关闭防火墙,为了方便就直接干掉了
sbin/start-dfs.sh #启动hdfs
sbin/start-yarn.sh #启动yarn

此时打开浏览器访问第一台机器配置的地址http://192.168.32.11:50070/
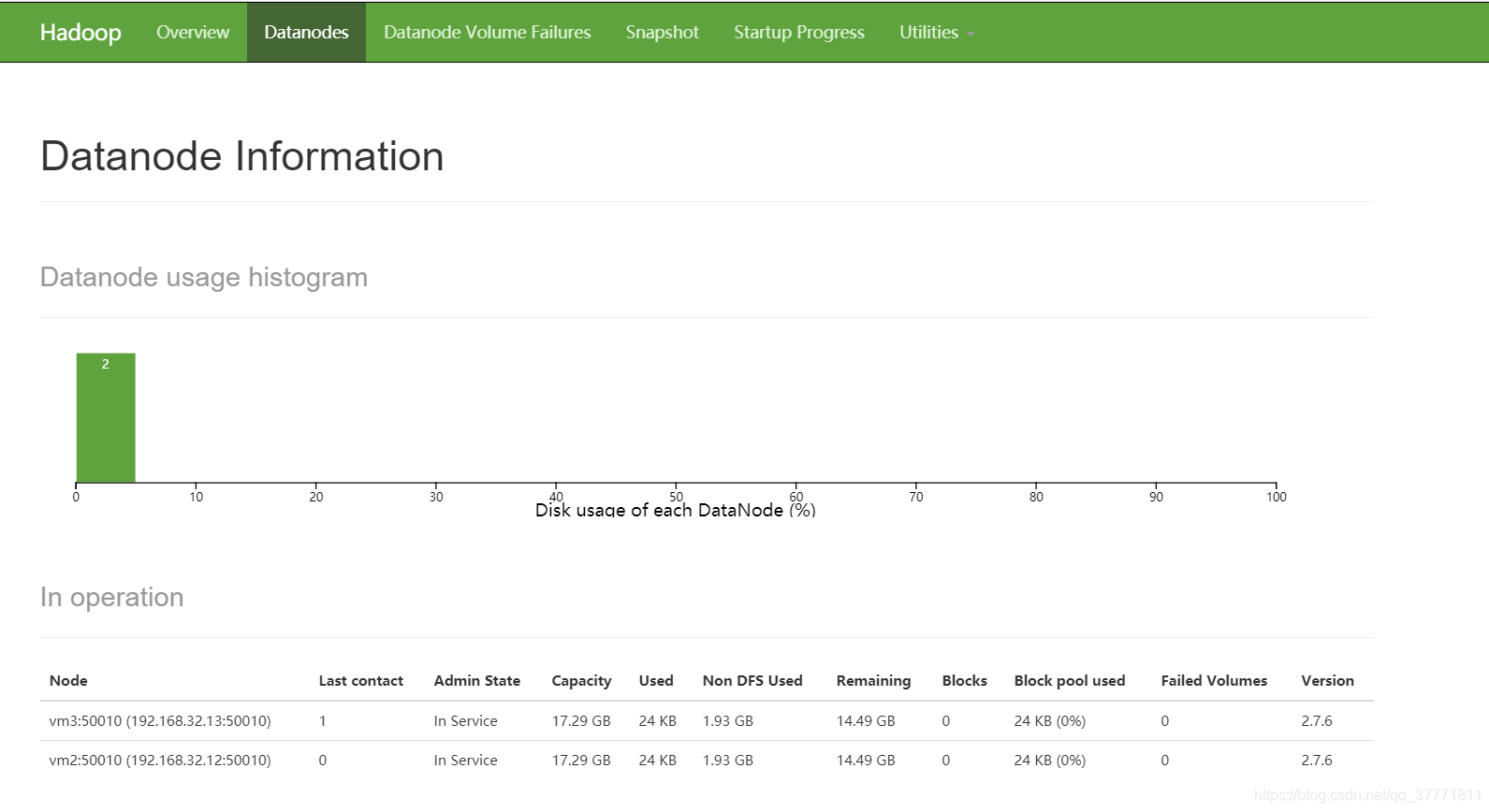
配置完成(本人初学,希望大家指正)